 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Physical-AI for Self-Aware RF Systems
Mar 21, 2026Intelligent control of RF transceivers adapting to dynamic operational conditions is essential in the modern and future communication systems. We propose a multi-agent neurosymbolic AI system, where AI agents are assigned for circuit components. Agents have an internal model and a corresponding control algorithm as its constituents. Modeling of the IF amplifier shows promising results, where the same approach can be extended to all the components, thus creating a fully intelligent RF system.
A Patient-Independent Neonatal Seizure Prediction Model Using Reduced Montage EEG and ECG
Nov 18, 2025Neonates are highly susceptible to seizures, often leading to short or long-term neurological impairments. However, clinical manifestations of neonatal seizures are subtle and often lead to misdiagnoses. This increases the risk of prolonged, untreated seizure activity and subsequent brain injury. Continuous video electroencephalogram (cEEG) monitoring is the gold standard for seizure detection. However, this is an expensive evaluation that requires expertise and time. In this study, we propose a convolutional neural network-based model for early prediction of neonatal seizures by distinguishing between interictal and preictal states of the EEG. Our model is patient-independent, enabling generalization across multiple subjects, and utilizes mel-frequency cepstral coefficient matrices extracted from multichannel EEG and electrocardiogram (ECG) signals as input features. Trained and validated on the Helsinki neonatal EEG dataset with 10-fold cross-validation, the proposed model achieved an average accuracy of 97.52%, sensitivity of 98.31%, specificity of 96.39%, and F1-score of 97.95%, enabling accurate seizure prediction up to 30 minutes before onset. The inclusion of ECG alongside EEG improved the F1-score by 1.42%, while the incorporation of an attention mechanism yielded an additional 0.5% improvement. To enhance transparency, we incorporated SHapley Additive exPlanations (SHAP) as an explainable artificial intelligence method to interpret the model and provided localization of seizure focus using scalp plots. The overall results demonstrate the model's potential for minimally supervised deployment in neonatal intensive care units, enabling timely and reliable prediction of neonatal seizures, while demonstrating strong generalization capability across unseen subjects through transfer learning.
Uncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology
Jun 13, 2025



Machine-learning-assisted cancer subtyping is a promising avenue in digital pathology. Cancer subtyping models, however, require careful training using expert annotations so that they can be inferred with a degree of known certainty (or uncertainty). To this end, we introduce the concept of uncertainty awareness into a self-supervised contrastive learning model. This is achieved by computing an evidence vector at every epoch, which assesses the model's confidence in its predictions. The derived uncertainty score is then utilized as a metric to selectively label the most crucial images that require further annotation, thus iteratively refining the training process. With just 1-10% of strategically selected annotations, we attain state-of-the-art performance in cancer subtyping on benchmark datasets. Our method not only strategically guides the annotation process to minimize the need for extensive labeled datasets, but also improves the precision and efficiency of classifications. This development is particularly beneficial in settings where the availability of labeled data is limited, offering a promising direction for future research and application in digital pathology.
Improving Neonatal Care: An Active Dry-Contact Electrode-based Continuous EEG Monitoring System with Seizure Detection
Mar 30, 2025Objective: Neonates are highly susceptible to seizures, which can have severe long-term consequences if undetected and left untreated. Early detection is crucial and typically requires continuous electroencephalography (EEG) monitoring in a hospital setting, which is costly, inconvenient, and requires specialized experts for diagnosis. In this work, we propose a new low-cost active dry-contact electrode-based adjustable EEG headset, a new explainable deep learning model to detect neonatal seizures, and an advanced signal processing algorithm to remove artifacts to address the key aspects that lead to the underdiagnosis of neonatal seizures. Methods: EEG signals are acquired through active electrodes and processed using a custom-designed analog front end (AFE) that filters and digitizes the captured EEG signals. The adjustable headset is designed using three-dimensional (3D) printing and laser cutting to fit a wide range of head sizes. A deep learning model is developed to classify seizure and non-seizure epochs in real-time. Furthermore, a separate multimodal deep learning model is designed to remove noise artifacts. The device is tested on a pediatric patient with absence seizures in a hospital setting. Simultaneous recordings are captured using both the custom device and the commercial wet electrode device available in the hospital for comparison. Results: The signals obtained using our custom design and a commercial device show a high correlation (>0.8). Further analysis using signal-to-noise ratio values shows that our device can mitigate noise similar to the commercial device. The proposed deep learning model has improvements in accuracy and recall by 2.76% and 16.33%, respectively, compared to the state-of-the-art. Furthermore, the developed artifact removal algorithm can identify and remove artifacts while keeping seizure patterns intact.
Arbitrary Volumetric Refocusing of Dense and Sparse Light Fields
Feb 26, 2025A four-dimensional light field (LF) captures both textural and geometrical information of a scene in contrast to a two-dimensional image that captures only the textural information of a scene. Post-capture refocusing is an exciting application of LFs enabled by the geometric information captured. Previously proposed LF refocusing methods are mostly limited to the refocusing of single planar or volumetric region of a scene corresponding to a depth range and cannot simultaneously generate in-focus and out-of-focus regions having the same depth range. In this paper, we propose an end-to-end pipeline to simultaneously refocus multiple arbitrary planar or volumetric regions of a dense or a sparse LF. We employ pixel-dependent shifts with the typical shift-and-sum method to refocus an LF. The pixel-dependent shifts enables to refocus each pixel of an LF independently. For sparse LFs, the shift-and-sum method introduces ghosting artifacts due to the spatial undersampling. We employ a deep learning model based on U-Net architecture to almost completely eliminate the ghosting artifacts. The experimental results obtained with several LF datasets confirm the effectiveness of the proposed method. In particular, sparse LFs refocused with the proposed method archive structural similarity index higher than 0.9 despite having only 20% of data compared to dense LFs.
Contrastive Deep Encoding Enables Uncertainty-aware Machine-learning-assisted Histopathology
Sep 13, 2023



Deep neural network models can learn clinically relevant features from millions of histopathology images. However generating high-quality annotations to train such models for each hospital, each cancer type, and each diagnostic task is prohibitively laborious. On the other hand, terabytes of training data -- while lacking reliable annotations -- are readily available in the public domain in some cases. In this work, we explore how these large datasets can be consciously utilized to pre-train deep networks to encode informative representations. We then fine-tune our pre-trained models on a fraction of annotated training data to perform specific downstream tasks. We show that our approach can reach the state-of-the-art (SOTA) for patch-level classification with only 1-10% randomly selected annotations compared to other SOTA approaches. Moreover, we propose an uncertainty-aware loss function, to quantify the model confidence during inference. Quantified uncertainty helps experts select the best instances to label for further training. Our uncertainty-aware labeling reaches the SOTA with significantly fewer annotations compared to random labeling. Last, we demonstrate how our pre-trained encoders can surpass current SOTA for whole-slide image classification with weak supervision. Our work lays the foundation for data and task-agnostic pre-trained deep networks with quantified uncertainty.
MOSAIC: Masked Optimisation with Selective Attention for Image Reconstruction
Jun 01, 2023



Compressive sensing (CS) reconstructs images from sub-Nyquist measurements by solving a sparsity-regularized inverse problem. Traditional CS solvers use iterative optimizers with hand crafted sparsifiers, while early data-driven methods directly learn an inverse mapping from the low-dimensional measurement space to the original image space. The latter outperforms the former, but is restrictive to a pre-defined measurement domain. More recent, deep unrolling methods combine traditional proximal gradient methods and data-driven approaches to iteratively refine an image approximation. To achieve higher accuracy, it has also been suggested to learn both the sampling matrix, and the choice of measurement vectors adaptively. Contrary to the current trend, in this work we hypothesize that a general inverse mapping from a random set of compressed measurements to the image domain exists for a given measurement basis, and can be learned. Such a model is single-shot, non-restrictive and does not parametrize the sampling process. To this end, we propose MOSAIC, a novel compressive sensing framework to reconstruct images given any random selection of measurements, sampled using a fixed basis. Motivated by the uneven distribution of information across measurements, MOSAIC incorporates an embedding technique to efficiently apply attention mechanisms on an encoded sequence of measurements, while dispensing the need to use unrolled deep networks. A range of experiments validate our proposed architecture as a promising alternative for existing CS reconstruction methods, by achieving the state-of-the-art for metrics of reconstruction accuracy on standard datasets.
A Knowledge Distillation Framework For Enhancing Ear-EEG Based Sleep Staging With Scalp-EEG Data
Oct 27, 2022Sleep plays a crucial role in the well-being of human lives. Traditional sleep studies using Polysomnography are associated with discomfort and often lower sleep quality caused by the acquisition setup. Previous works have focused on developing less obtrusive methods to conduct high-quality sleep studies, and ear-EEG is among popular alternatives. However, the performance of sleep staging based on ear-EEG is still inferior to scalp-EEG based sleep staging. In order to address the performance gap between scalp-EEG and ear-EEG based sleep staging, we propose a cross-modal knowledge distillation strategy, which is a domain adaptation approach. Our experiments and analysis validate the effectiveness of the proposed approach with existing architectures, where it enhances the accuracy of the ear-EEG based sleep staging by 3.46% and Cohen's kappa coefficient by a margin of 0.038.
Vision Transformer with Convolutional Encoder-Decoder for Hand Gesture Recognition using 24 GHz Doppler Radar
Sep 12, 2022

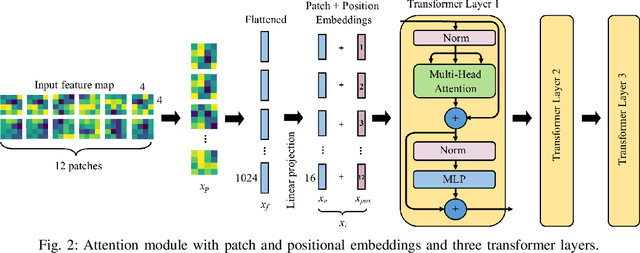
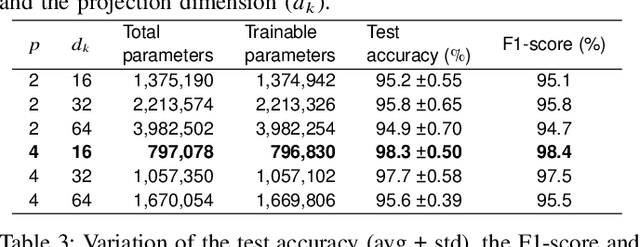
Transformers combined with convolutional encoders have been recently used for hand gesture recognition (HGR) using micro-Doppler signatures. We propose a vision-transformer-based architecture for HGR with multi-antenna continuous-wave Doppler radar receivers. The proposed architecture consists of three modules: a convolutional encoderdecoder, an attention module with three transformer layers, and a multi-layer perceptron. The novel convolutional decoder helps to feed patches with larger sizes to the attention module for improved feature extraction. Experimental results obtained with a dataset corresponding to a two-antenna continuous-wave Doppler radar receiver operating at 24 GHz (published by Skaria et al.) confirm that the proposed architecture achieves an accuracy of 98.3% which substantially surpasses the state-of-the-art on the used dataset.
Towards Interpretable Sleep Stage Classification Using Cross-Modal Transformers
Aug 15, 2022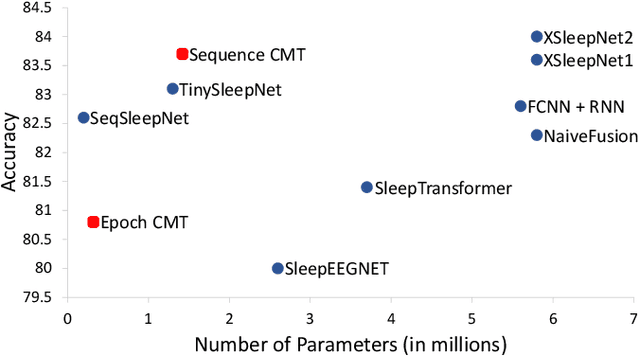
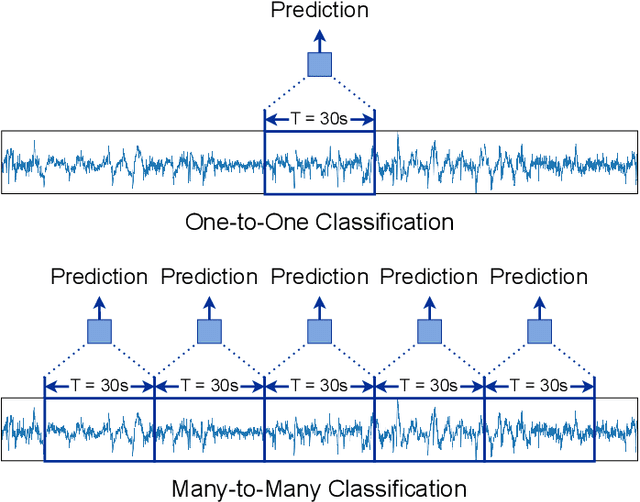
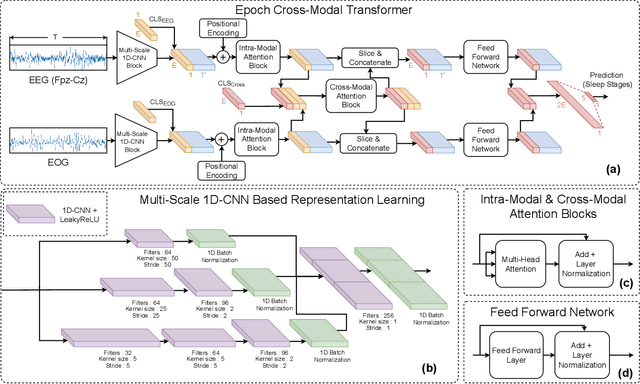
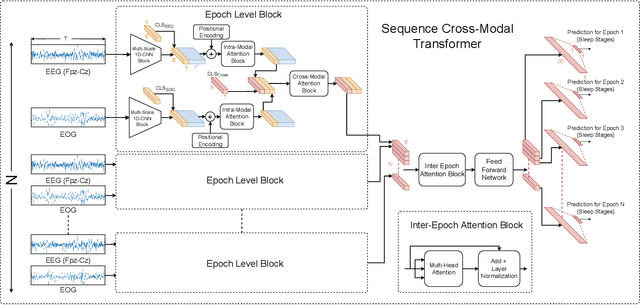
Accurate sleep stage classification is significant for sleep health assessment. In recent years, several deep learning and machine learning based sleep staging algorithms have been developed and they have achieved performance on par with human annotation. Despite improved performance, a limitation of most deep-learning based algorithms is their Black-box behavior, which which have limited their use in clinical settings. Here, we propose Cross-Modal Transformers, which is a transformer-based method for sleep stage classification. Our models achieve both competitive performance with the state-of-the-art approaches and eliminates the Black-box behavior of deep-learning models by utilizing the interpretability aspect of the attention modules. The proposed cross-modal transformers consist of a novel cross-modal transformer encoder architecture along with a multi-scale 1-dimensional convolutional neural network for automatic representation learning. Our sleep stage classifier based on this design was able to achieve sleep stage classification performance on par with or better than the state-of-the-art approaches, along with interpretability, a fourfold reduction in the number of parameters and a reduced training time compared to the current state-of-the-art. Our code is available at https://github.com/Jathurshan0330/Cross-Modal-Transformer.