 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection with Test Time Augmentation and Consistency Evaluation
Paper and Code
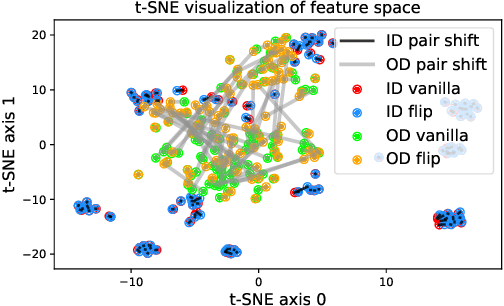
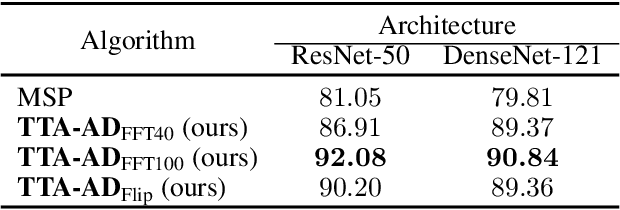

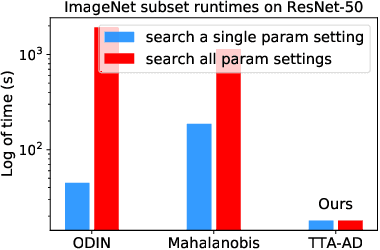
Deep neural networks are known to be vulnerable to unseen data: they may wrongly assign high confidence stcores to out-distribuion samples. Recent works try to solve the problem using representation learning methods and specific metrics. In this paper, we propose a simple, yet effective post-hoc anomaly detection algorithm named Test Time Augmentation Anomaly Detection (TTA-AD), inspired by a novel observation. Specifically, we observe that in-distribution data enjoy more consistent predictions for its original and augmented versions on a trained network than out-distribution data, which separates in-distribution and out-distribution samples. Experiments on various high-resolution image benchmark datasets demonstrate that TTA-AD achieves comparable or better detection performance under dataset-vs-dataset anomaly detection settings with a 60%~90\% running time reduction of existing classifier-based algorithms. We provide empirical verification that the key to TTA-AD lies in the remaining classes between augmented features, which has long been partially ignored by previous works. Additionally, we use RUNS as a surrogate to analyze our algorithm theoretically.