 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generating near-infrared facial expression datasets with dimensional affect labels
Jun 28, 2022
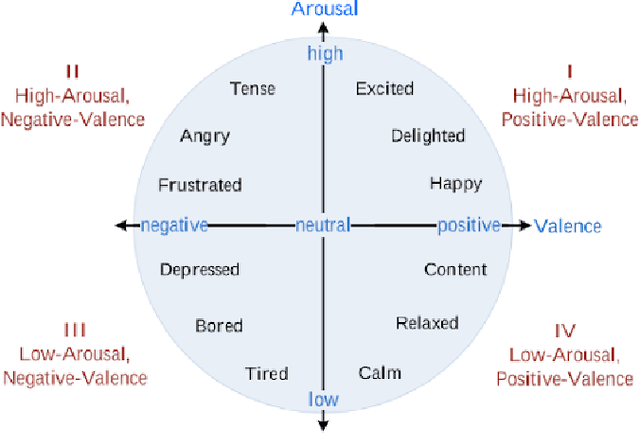
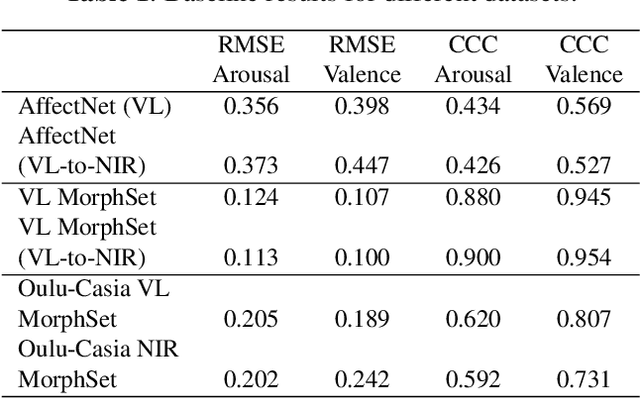
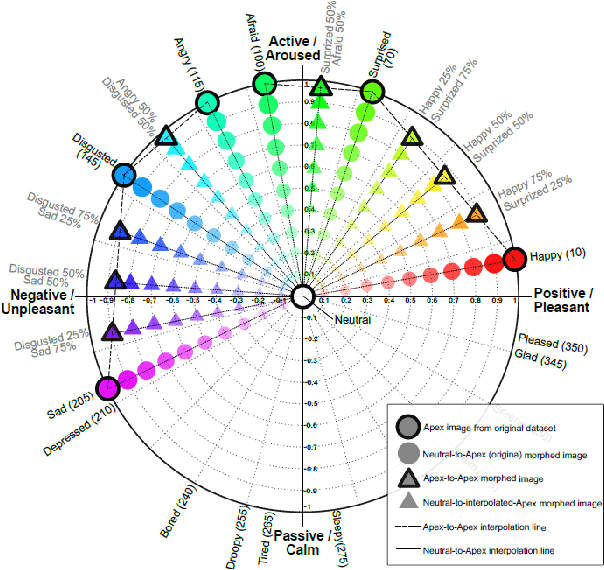

Facial expression analysis has long been an active research area of computer vision. Traditional methods mainly analyse images for prototypical discrete emotions; as a result, they do not provide an accurate depiction of the complex emotional states in humans. Furthermore, illumination variance remains a challenge for face analysis in the visible light spectrum. To address these issues, we propose using a dimensional model based on valence and arousal to represent a wider range of emotions, in combination with near infra-red (NIR) imagery, which is more robust to illumination changes. Since there are no existing NIR facial expression datasets with valence-arousal labels available, we present two complementary data augmentation methods (face morphing and CycleGAN approach) to create NIR image datasets with dimensional emotion labels from existing categorical and/or visible-light datasets. Our experiments show that these generated NIR datasets are comparable to existing datasets in terms of data quality and baseline prediction performance.
BRIMA: low-overhead BRowser-only IMage Annotation tool (Preprint)
Jul 13, 2021

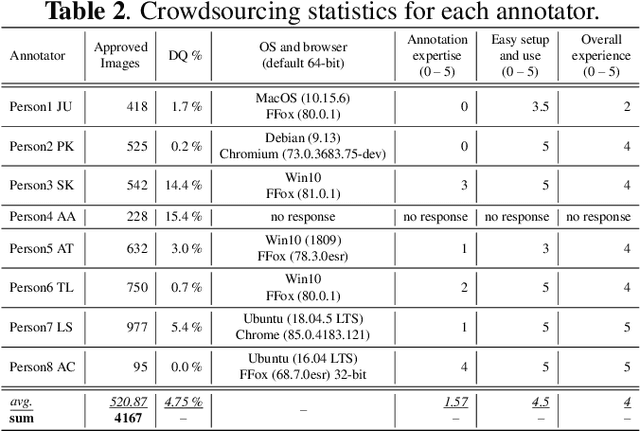
Image annotation and large annotated datasets are crucial parts within the Computer Vision and Artificial Intelligence fields.At the same time, it is well-known and acknowledged by the research community that the image annotation process is challenging, time-consuming and hard to scale. Therefore, the researchers and practitioners are always seeking ways to perform the annotations easier, faster, and at higher quality. Even though several widely used tools exist and the tools' landscape evolved considerably, most of the tools still require intricate technical setups and high levels of technical savviness from its operators and crowdsource contributors. In order to address such challenges, we develop and present BRIMA -- a flexible and open-source browser extension that allows BRowser-only IMage Annotation at considerably lower overheads. Once added to the browser, it instantly allows the user to annotate images easily and efficiently directly from the browser without any installation or setup on the client-side. It also features cross-browser and cross-platform functionality thus presenting itself as a neat tool for researchers within the Computer Vision, Artificial Intelligence, and privacy-related fields.
Self-Paced Contrastive Learning for Semi-supervised Medical Image Segmentation with Meta-labels
Aug 22, 2021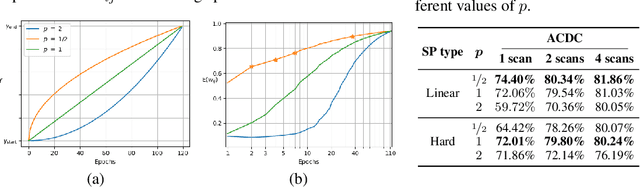
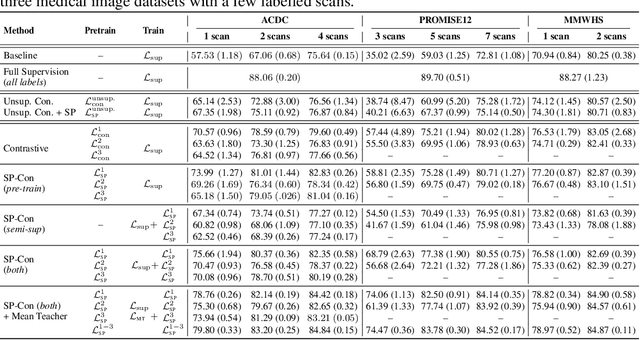
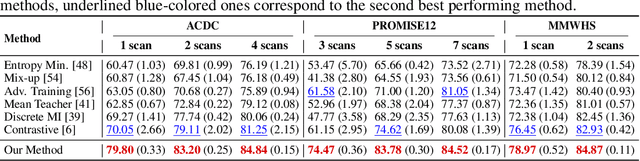
Pre-training a recognition model with contrastive learning on a large dataset of unlabeled data has shown great potential to boost the performance of a downstream task, e.g., image classification. However, in domains such as medical imaging, collecting unlabeled data can be challenging and expensive. In this work, we propose to adapt contrastive learning to work with meta-label annotations, for improving the model's performance in medical image segmentation even when no additional unlabeled data is available. Meta-labels such as the location of a 2D slice in a 3D MRI scan or the type of device used, often come for free during the acquisition process. We use the meta-labels for pre-training the image encoder as well as to regularize a semi-supervised training, in which a reduced set of annotated data is used for training. Finally, to fully exploit the weak annotations, a self-paced learning approach is used to help the learning and discriminate useful labels from noise. Results on three different medical image segmentation datasets show that our approach: i) highly boosts the performance of a model trained on a few scans, ii) outperforms previous contrastive and semi-supervised approaches, and iii) reaches close to the performance of a model trained on the full data.
Design of an embedded system with on-demand image capturing and transmission for remote agricultural monitoring
May 25, 2022
The ability to visually verify some element of a remotely controlled agricultural automation system through a photograph is valuable in many cases, not only in the operational phase of the system, but especially in the design and implementation phases. Owing to the remote location of many of the application sites, cellular technology is one enabling medium through which wireless transmission of the photographs could be realized. As data usage is a concern for systems using cellular technology, MQTT chosen over other protocols due to its lower message-to-header overhead. This paper outlines the hardware and firmware design of the LTE Cat-M1 enabled embedded system and the backend web development of the cloud-based web application to facilitate the receiving of the photograph. A satisfactory degree of implementation success was achieved in this project, with deployment to a production environment possible after further refinements.
Reconstruction of Time-varying Graph Signals via Sobolev Smoothness
Jul 13, 2022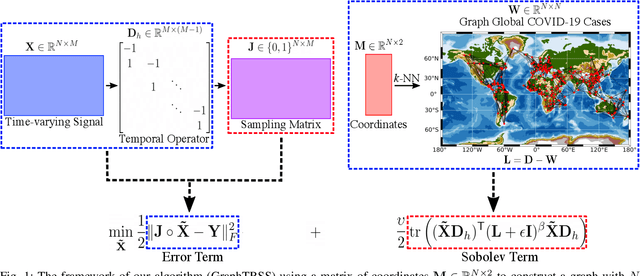
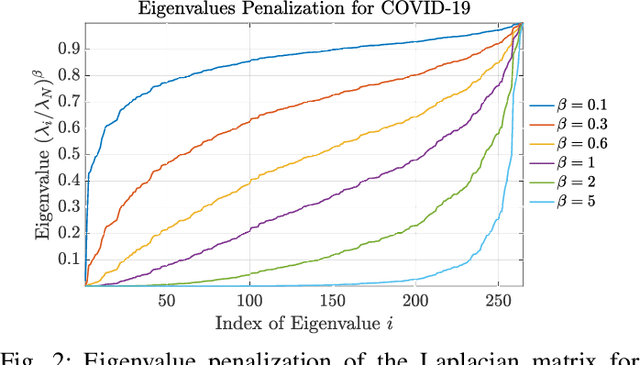
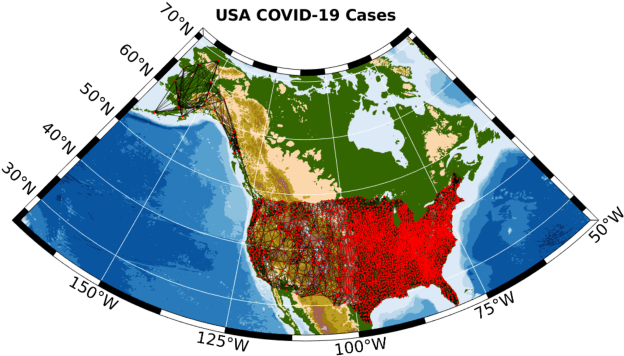
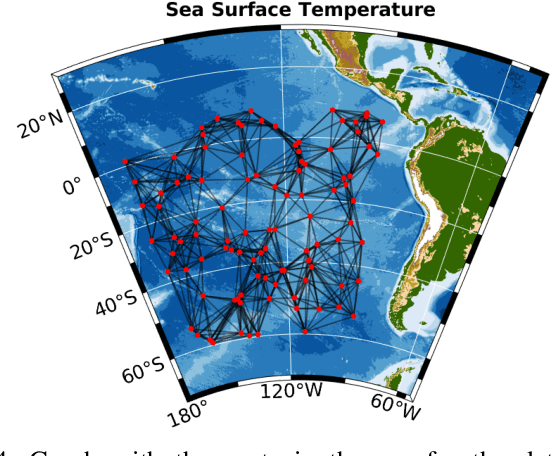
Graph Signal Processing (GSP) is an emerging research field that extends the concepts of digital signal processing to graphs. GSP has numerous applications in different areas such as sensor networks, machine learning, and image processing. The sampling and reconstruction of static graph signals have played a central role in GSP. However, many real-world graph signals are inherently time-varying and the smoothness of the temporal differences of such graph signals may be used as a prior assumption. In the current work, we assume that the temporal differences of graph signals are smooth, and we introduce a novel algorithm based on the extension of a Sobolev smoothness function for the reconstruction of time-varying graph signals from discrete samples. We explore some theoretical aspects of the convergence rate of our Time-varying Graph signal Reconstruction via Sobolev Smoothness (GraphTRSS) algorithm by studying the condition number of the Hessian associated with our optimization problem. Our algorithm has the advantage of converging faster than other methods that are based on Laplacian operators without requiring expensive eigenvalue decomposition or matrix inversions. The proposed GraphTRSS is evaluated on several datasets including two COVID-19 datasets and it has outperformed many existing state-of-the-art methods for time-varying graph signal reconstruction. GraphTRSS has also shown excellent performance on two environmental datasets for the recovery of particulate matter and sea surface temperature signals.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021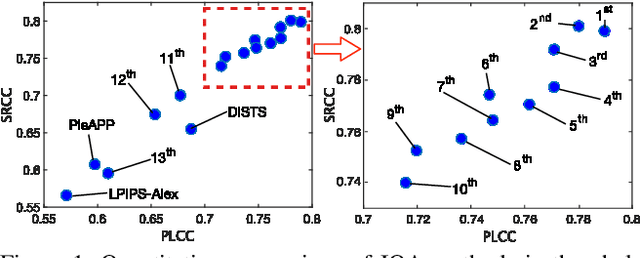
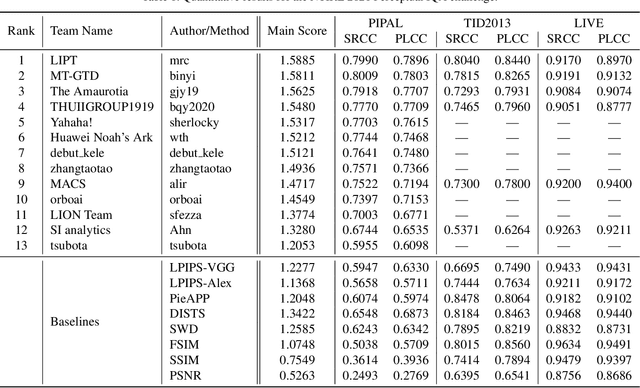

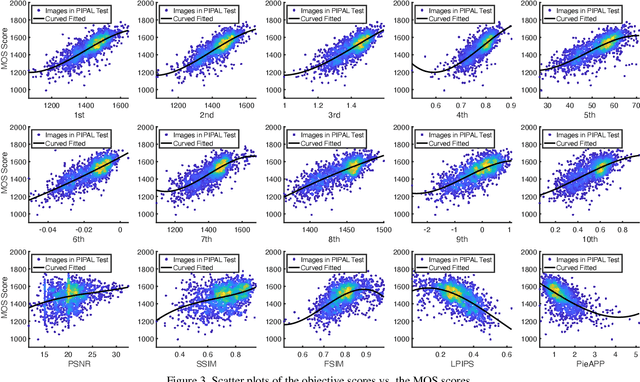
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Going deeper with Image Transformers
Mar 31, 2021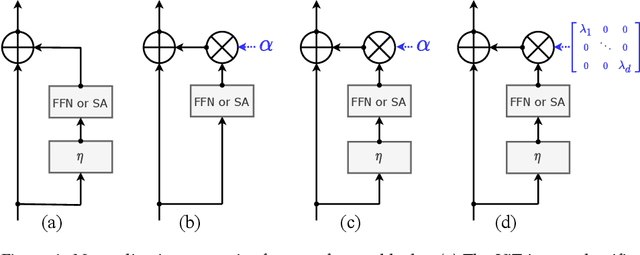
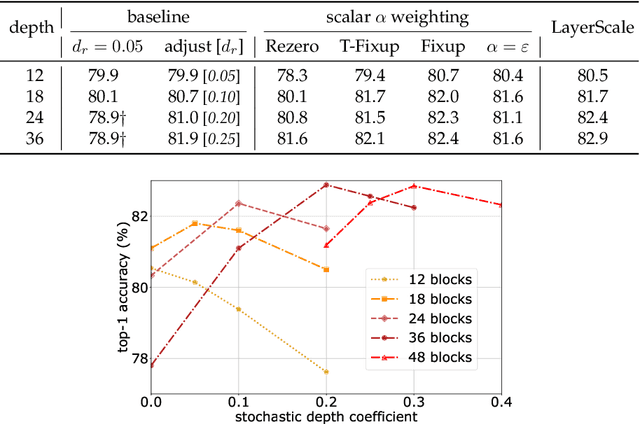
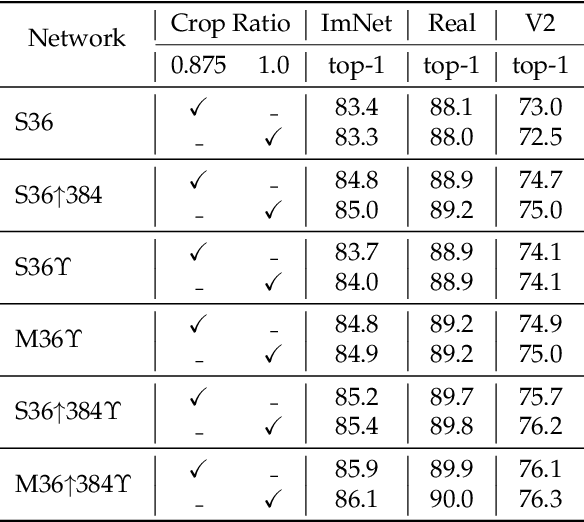
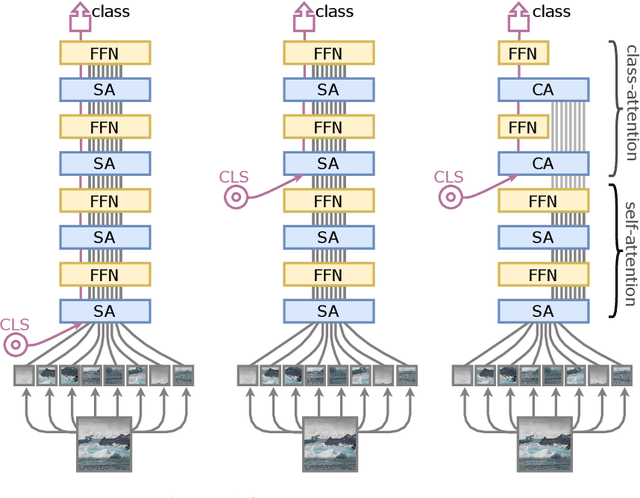
Transformers have been recently adapted for large scale image classification, achieving high scores shaking up the long supremacy of convolutional neural networks. However the optimization of image transformers has been little studied so far. In this work, we build and optimize deeper transformer networks for image classification. In particular, we investigate the interplay of architecture and optimization of such dedicated transformers. We make two transformers architecture changes that significantly improve the accuracy of deep transformers. This leads us to produce models whose performance does not saturate early with more depth, for instance we obtain 86.3% top-1 accuracy on Imagenet when training with no external data. Our best model establishes the new state of the art on Imagenet with Reassessed labels and Imagenet-V2 / match frequency, in the setting with no additional training data.
Multi-Fake Evolutionary Generative Adversarial Networks for Imbalance Hyperspectral Image Classification
Nov 07, 2021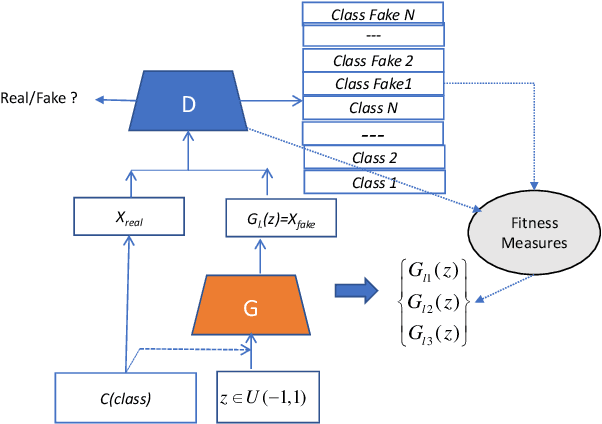
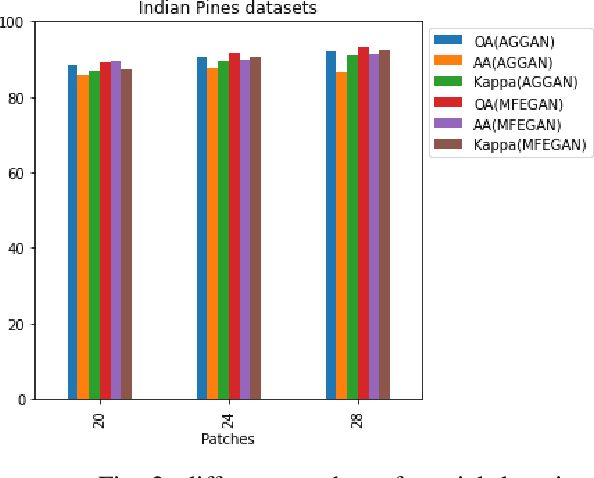
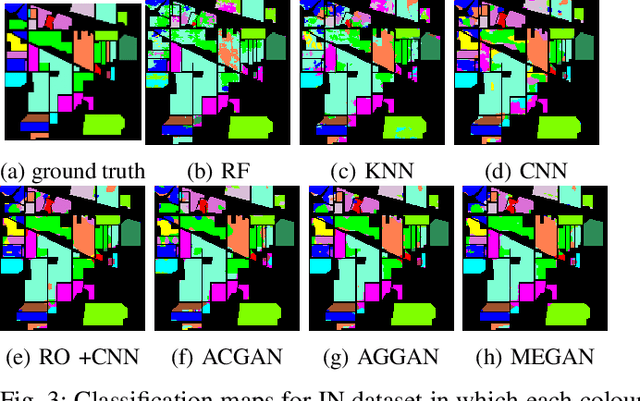
This paper presents a novel multi-fake evolutionary generative adversarial network(MFEGAN) for handling imbalance hyperspectral image classification. It is an end-to-end approach in which different generative objective losses are considered in the generator network to improve the classification performance of the discriminator network. Thus, the same discriminator network has been used as a standard classifier by embedding the classifier network on top of the discriminating function. The effectiveness of the proposed method has been validated through two hyperspectral spatial-spectral data sets. The same generative and discriminator architectures have been utilized with two different GAN objectives for a fair performance comparison with the proposed method. It is observed from the experimental validations that the proposed method outperforms the state-of-the-art methods with better classification performance.
A Meta-Analysis of Distributionally-Robust Models
Jun 15, 2022
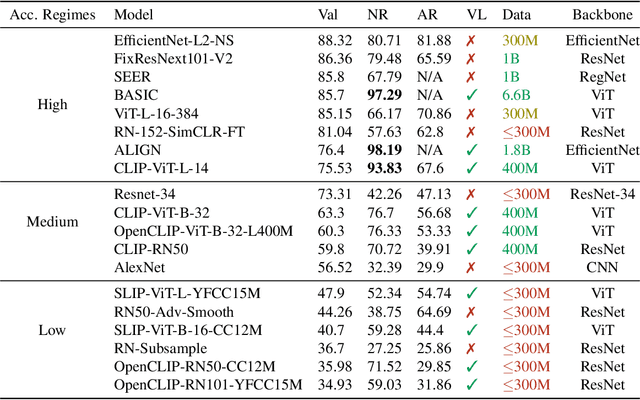
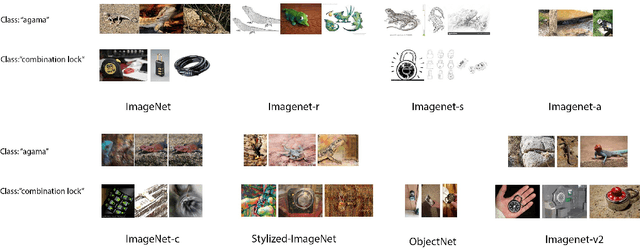
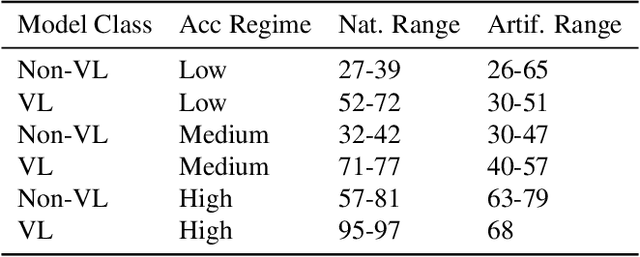
State-of-the-art image classifiers trained on massive datasets (such as ImageNet) have been shown to be vulnerable to a range of both intentional and incidental distribution shifts. On the other hand, several recent classifiers with favorable out-of-distribution (OOD) robustness properties have emerged, achieving high accuracy on their target tasks while maintaining their in-distribution accuracy on challenging benchmarks. We present a meta-analysis on a wide range of publicly released models, most of which have been published over the last twelve months. Through this meta-analysis, we empirically identify four main commonalities for all the best-performing OOD-robust models, all of which illuminate the considerable promise of vision-language pre-training.
Explainability of the Implications of Supervised and Unsupervised Face Image Quality Estimations Through Activation Map Variation Analyses in Face Recognition Models
Dec 09, 2021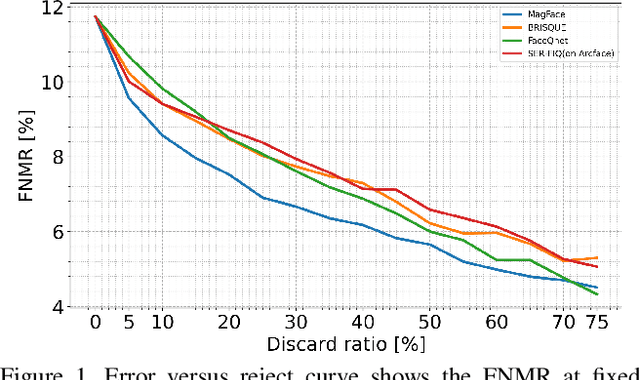
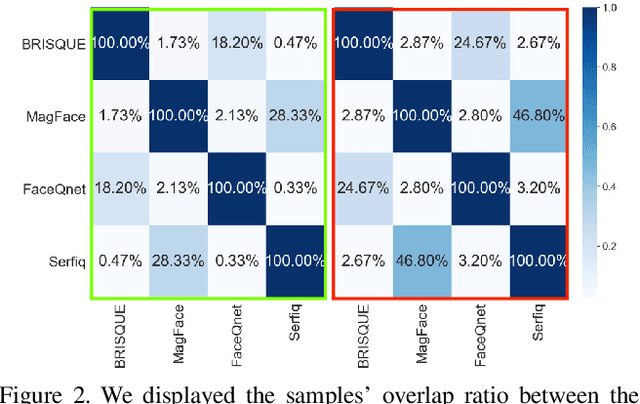
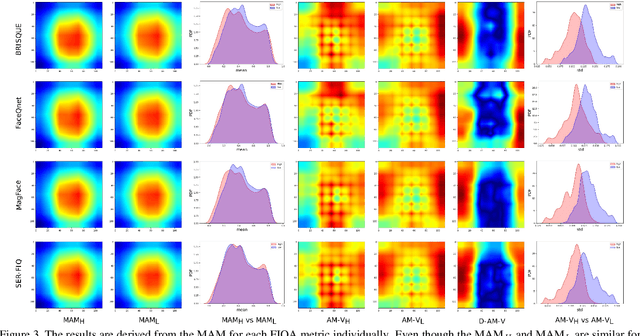
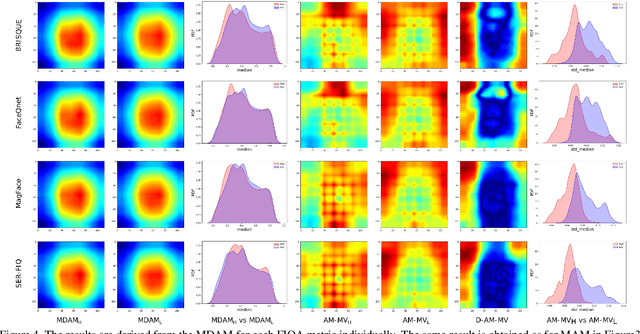
It is challenging to derive explainability for unsupervised or statistical-based face image quality assessment (FIQA) methods. In this work, we propose a novel set of explainability tools to derive reasoning for different FIQA decisions and their face recognition (FR) performance implications. We avoid limiting the deployment of our tools to certain FIQA methods by basing our analyses on the behavior of FR models when processing samples with different FIQA decisions. This leads to explainability tools that can be applied for any FIQA method with any CNN-based FR solution using activation mapping to exhibit the network's activation derived from the face embedding. To avoid the low discrimination between the general spatial activation mapping of low and high-quality images in FR models, we build our explainability tools in a higher derivative space by analyzing the variation of the FR activation maps of image sets with different quality decisions. We demonstrate our tools and analyze the findings on four FIQA methods, by presenting inter and intra-FIQA method analyses. Our proposed tools and the analyses based on them point out, among other conclusions, that high-quality images typically cause consistent low activation on the areas outside of the central face region, while low-quality images, despite general low activation, have high variations of activation in such areas. Our explainability tools also extend to analyzing single images where we show that low-quality images tend to have an FR model spatial activation that strongly differs from what is expected from a high-quality image where this difference also tends to appear more in areas outside of the central face region and does correspond to issues like extreme poses and facial occlusions. The implementation of the proposed tools is accessible here [link].