 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaViD: Spectravista Aesthetic Vision Integration for Robust and Discerning 3D Object Detection in Challenging Environments
Mar 26, 2025



The fusion of LiDAR and camera sensors has demonstrated significant effectiveness in achieving accurate detection for short-range tasks in autonomous driving. However, this fusion approach could face challenges when dealing with long-range detection scenarios due to disparity between sparsity of LiDAR and high-resolution camera data. Moreover, sensor corruption introduces complexities that affect the ability to maintain robustness, despite the growing adoption of sensor fusion in this domain. We present SaViD, a novel framework comprised of a three-stage fusion alignment mechanism designed to address long-range detection challenges in the presence of natural corruption. The SaViD framework consists of three key elements: the Global Memory Attention Network (GMAN), which enhances the extraction of image features through offering a deeper understanding of global patterns; the Attentional Sparse Memory Network (ASMN), which enhances the integration of LiDAR and image features; and the KNNnectivity Graph Fusion (KGF), which enables the entire fusion of spatial information. SaViD achieves superior performance on the long-range detection Argoverse-2 (AV2) dataset with a performance improvement of 9.87% in AP value and an improvement of 2.39% in mAPH for L2 difficulties on the Waymo Open dataset (WOD). Comprehensive experiments are carried out to showcase its robustness against 14 natural sensor corruptions. SaViD exhibits a robust performance improvement of 31.43% for AV2 and 16.13% for WOD in RCE value compared to other existing fusion-based methods while considering all the corruptions for both datasets. Our code is available at \href{https://github.com/sanjay-810/SAVID}
UNetVL: Enhancing 3D Medical Image Segmentation with Chebyshev KAN Powered Vision-LSTM
Jan 13, 2025



3D medical image segmentation has progressed considerably due to Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), yet these methods struggle to balance long-range dependency acquisition with computational efficiency. To address this challenge, we propose UNETVL (U-Net Vision-LSTM), a novel architecture that leverages recent advancements in temporal information processing. UNETVL incorporates Vision-LSTM (ViL) for improved scalability and memory functions, alongside an efficient Chebyshev Kolmogorov-Arnold Networks (KAN) to handle complex and long-range dependency patterns more effectively. We validated our method on the ACDC and AMOS2022 (post challenge Task 2) benchmark datasets, showing a significant improvement in mean Dice score compared to recent state-of-the-art approaches, especially over its predecessor, UNETR, with increases of 7.3% on ACDC and 15.6% on AMOS, respectively. Extensive ablation studies were conducted to demonstrate the impact of each component in UNETVL, providing a comprehensive understanding of its architecture. Our code is available at https://github.com/tgrex6/UNETVL, facilitating further research and applications in this domain.
DRACO-DehazeNet: An Efficient Image Dehazing Network Combining Detail Recovery and a Novel Contrastive Learning Paradigm
Oct 18, 2024



Image dehazing is crucial for clarifying images obscured by haze or fog, but current learning-based approaches is dependent on large volumes of training data and hence consumed significant computational power. Additionally, their performance is often inadequate under non-uniform or heavy haze. To address these challenges, we developed the Detail Recovery And Contrastive DehazeNet, which facilitates efficient and effective dehazing via a dense dilated inverted residual block and an attention-based detail recovery network that tailors enhancements to specific dehazed scene contexts. A major innovation is its ability to train effectively with limited data, achieved through a novel quadruplet loss-based contrastive dehazing paradigm. This approach distinctly separates hazy and clear image features while also distinguish lower-quality and higher-quality dehazed images obtained from each sub-modules of our network, thereby refining the dehazing process to a larger extent. Extensive tests on a variety of benchmarked haze datasets demonstrated the superiority of our approach. The code repository for this work will be available soon.
Quantum Inverse Contextual Vision Transformers (Q-ICVT): A New Frontier in 3D Object Detection for AVs
Aug 20, 2024



The field of autonomous vehicles (AVs) predominantly leverages multi-modal integration of LiDAR and camera data to achieve better performance compared to using a single modality. However, the fusion process encounters challenges in detecting distant objects due to the disparity between the high resolution of cameras and the sparse data from LiDAR. Insufficient integration of global perspectives with local-level details results in sub-optimal fusion performance.To address this issue, we have developed an innovative two-stage fusion process called Quantum Inverse Contextual Vision Transformers (Q-ICVT). This approach leverages adiabatic computing in quantum concepts to create a novel reversible vision transformer known as the Global Adiabatic Transformer (GAT). GAT aggregates sparse LiDAR features with semantic features in dense images for cross-modal integration in a global form. Additionally, the Sparse Expert of Local Fusion (SELF) module maps the sparse LiDAR 3D proposals and encodes position information of the raw point cloud onto the dense camera feature space using a gating point fusion approach. Our experiments show that Q-ICVT achieves an mAPH of 82.54 for L2 difficulties on the Waymo dataset, improving by 1.88% over current state-of-the-art fusion methods. We also analyze GAT and SELF in ablation studies to highlight the impact of Q-ICVT. Our code is available at https://github.com/sanjay-810/Qicvt Q-ICVT
Dehazing Remote Sensing and UAV Imagery: A Review of Deep Learning, Prior-based, and Hybrid Approaches
May 13, 2024High-quality images are crucial in remote sensing and UAV applications, but atmospheric haze can severely degrade image quality, making image dehazing a critical research area. Since the introduction of deep convolutional neural networks, numerous approaches have been proposed, and even more have emerged with the development of vision transformers and contrastive/few-shot learning. Simultaneously, papers describing dehazing architectures applicable to various Remote Sensing (RS) domains are also being published. This review goes beyond the traditional focus on benchmarked haze datasets, as we also explore the application of dehazing techniques to remote sensing and UAV datasets, providing a comprehensive overview of both deep learning and prior-based approaches in these domains. We identify key challenges, including the lack of large-scale RS datasets and the need for more robust evaluation metrics, and outline potential solutions and future research directions to address them. This review is the first, to our knowledge, to provide comprehensive discussions on both existing and very recent dehazing approaches (as of 2024) on benchmarked and RS datasets, including UAV-based imagery.
AYDIV: Adaptable Yielding 3D Object Detection via Integrated Contextual Vision Transformer
Feb 12, 2024Combining LiDAR and camera data has shown potential in enhancing short-distance object detection in autonomous driving systems. Yet, the fusion encounters difficulties with extended distance detection due to the contrast between LiDAR's sparse data and the dense resolution of cameras. Besides, discrepancies in the two data representations further complicate fusion methods. We introduce AYDIV, a novel framework integrating a tri-phase alignment process specifically designed to enhance long-distance detection even amidst data discrepancies. AYDIV consists of the Global Contextual Fusion Alignment Transformer (GCFAT), which improves the extraction of camera features and provides a deeper understanding of large-scale patterns; the Sparse Fused Feature Attention (SFFA), which fine-tunes the fusion of LiDAR and camera details; and the Volumetric Grid Attention (VGA) for a comprehensive spatial data fusion. AYDIV's performance on the Waymo Open Dataset (WOD) with an improvement of 1.24% in mAPH value(L2 difficulty) and the Argoverse2 Dataset with a performance improvement of 7.40% in AP value demonstrates its efficacy in comparison to other existing fusion-based methods. Our code is publicly available at https://github.com/sanjay-810/AYDIV2
OrthoSeisnet: Seismic Inversion through Orthogonal Multi-scale Frequency Domain U-Net for Geophysical Exploration
Jan 09, 2024Seismic inversion is crucial in hydrocarbon exploration, particularly for detecting hydrocarbons in thin layers. However, the detection of sparse thin layers within seismic datasets presents a significant challenge due to the ill-posed nature and poor non-linearity of the problem. While data-driven deep learning algorithms have shown promise, effectively addressing sparsity remains a critical area for improvement. To overcome this limitation, we propose OrthoSeisnet, a novel technique that integrates a multi-scale frequency domain transform within the U-Net framework. OrthoSeisnet aims to enhance the interpretability and resolution of seismic images, enabling the identification and utilization of sparse frequency components associated with hydrocarbon-bearing layers. By leveraging orthogonal basis functions and decoupling frequency components, OrthoSeisnet effectively improves data sparsity. We evaluate the performance of OrthoSeisnet using synthetic and real datasets obtained from the Krishna-Godavari basin. Orthoseisnet outperforms the traditional method through extensive performance analysis utilizing commonly used measures, such as mean absolute error (MAE), mean squared error (MSE), and structural similarity index (SSIM) https://github.com/supriyo100/Orthoseisnet.
Unlocking the capabilities of explainable fewshot learning in remote sensing
Oct 12, 2023Recent advancements have significantly improved the efficiency and effectiveness of deep learning methods for imagebased remote sensing tasks. However, the requirement for large amounts of labeled data can limit the applicability of deep neural networks to existing remote sensing datasets. To overcome this challenge, fewshot learning has emerged as a valuable approach for enabling learning with limited data. While previous research has evaluated the effectiveness of fewshot learning methods on satellite based datasets, little attention has been paid to exploring the applications of these methods to datasets obtained from UAVs, which are increasingly used in remote sensing studies. In this review, we provide an up to date overview of both existing and newly proposed fewshot classification techniques, along with appropriate datasets that are used for both satellite based and UAV based data. Our systematic approach demonstrates that fewshot learning can effectively adapt to the broader and more diverse perspectives that UAVbased platforms can provide. We also evaluate some SOTA fewshot approaches on a UAV disaster scene classification dataset, yielding promising results. We emphasize the importance of integrating XAI techniques like attention maps and prototype analysis to increase the transparency, accountability, and trustworthiness of fewshot models for remote sensing. Key challenges and future research directions are identified, including tailored fewshot methods for UAVs, extending to unseen tasks like segmentation, and developing optimized XAI techniques suited for fewshot remote sensing problems. This review aims to provide researchers and practitioners with an improved understanding of fewshot learnings capabilities and limitations in remote sensing, while highlighting open problems to guide future progress in efficient, reliable, and interpretable fewshot methods.
WATT-EffNet: A Lightweight and Accurate Model for Classifying Aerial Disaster Images
May 01, 2023Incorporating deep learning (DL) classification models into unmanned aerial vehicles (UAVs) can significantly augment search-and-rescue operations and disaster management efforts. In such critical situations, the UAV's ability to promptly comprehend the crisis and optimally utilize its limited power and processing resources to narrow down search areas is crucial. Therefore, developing an efficient and lightweight method for scene classification is of utmost importance. However, current approaches tend to prioritize accuracy on benchmark datasets at the expense of computational efficiency. To address this shortcoming, we introduce the Wider ATTENTION EfficientNet (WATT-EffNet), a novel method that achieves higher accuracy with a more lightweight architecture compared to the baseline EfficientNet. The WATT-EffNet leverages width-wise incremental feature modules and attention mechanisms over width-wise features to ensure the network structure remains lightweight. We evaluate our method on a UAV-based aerial disaster image classification dataset and demonstrate that it outperforms the baseline by up to 15 times in terms of classification accuracy and 38.3% in terms of computing efficiency as measured by Floating Point Operations per second (FLOPs). Additionally, we conduct an ablation study to investigate the effect of varying the width of WATT-EffNet on accuracy and computational efficiency. Our code is available at \url{https://github.com/TanmDL/WATT-EffNet}.
Improving Self-supervised Learning for Out-of-distribution Task via Auxiliary Classifier
Sep 07, 2022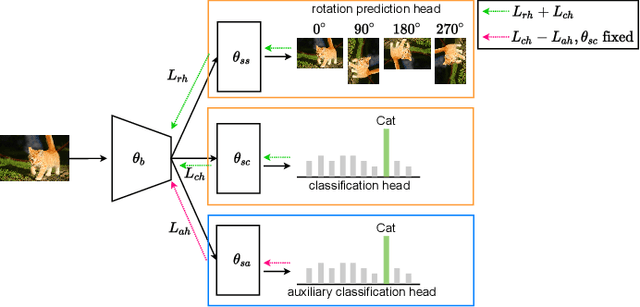
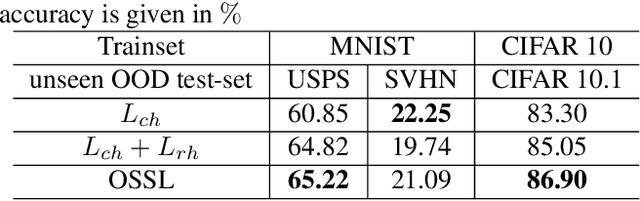

In real world scenarios, out-of-distribution (OOD) datasets may have a large distributional shift from training datasets. This phenomena generally occurs when a trained classifier is deployed on varying dynamic environments, which causes a significant drop in performance. To tackle this issue, we are proposing an end-to-end deep multi-task network in this work. Observing a strong relationship between rotation prediction (self-supervised) accuracy and semantic classification accuracy on OOD tasks, we introduce an additional auxiliary classification head in our multi-task network along with semantic classification and rotation prediction head. To observe the influence of this addition classifier in improving the rotation prediction head, our proposed learning method is framed into bi-level optimisation problem where the upper-level is trained to update the parameters for semantic classification and rotation prediction head. In the lower-level optimisation, only the auxiliary classification head is updated through semantic classification head by fixing the parameters of the semantic classification head. The proposed method has been validated through three unseen OOD datasets where it exhibits a clear improvement in semantic classification accuracy than other two baseline methods. Our code is available on GitHub \url{https://github.com/harshita-555/OSSL}