 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-contempt: a hybrid MCTS algorithm for training AlphaZero-like engines with better computational efficiency
Apr 10, 2025AlphaZero in 2017 was able to master chess and other games without human knowledge by playing millions of games against itself (self-play), with a computation budget running in the tens of millions of dollars. It used a variant of the Monte Carlo Tree Search (MCTS) algorithm, known as PUCT. This paper introduces search-contempt, a novel hybrid variant of the MCTS algorithm that fundamentally alters the distribution of positions generated in self-play, preferring more challenging positions. In addition, search-contempt has been shown to give a big boost in strength for engines in Odds Chess (where one side receives an unfavorable position from the start). More significantly, it opens up the possibility of training a self-play based engine, in a much more computationally efficient manner with the number of training games running into hundreds of thousands, costing tens of thousands of dollars (instead of tens of millions of training games costing millions of dollars required by AlphaZero). This means that it may finally be possible to train such a program from zero on a standard consumer GPU even with a very limited compute, cost, or time budget.
A Curious Case of Remarkable Resilience to Gradient Attacks via Fully Convolutional and Differentiable Front End with a Skip Connection
Feb 26, 2024We tested front-end enhanced neural models where a frozen classifier was prepended by a differentiable and fully convolutional model with a skip connection. By training them using a small learning rate for about one epoch, we obtained models that retained the accuracy of the backbone classifier while being unusually resistant to gradient attacks including APGD and FAB-T attacks from the AutoAttack package, which we attributed to gradient masking. The gradient masking phenomenon is not new, but the degree of masking was quite remarkable for fully differentiable models that did not have gradient-shattering components such as JPEG compression or components that are expected to cause diminishing gradients. Though black box attacks can be partially effective against gradient masking, they are easily defeated by combining models into randomized ensembles. We estimate that such ensembles achieve near-SOTA AutoAttack accuracy on CIFAR10, CIFAR100, and ImageNet despite having virtually zero accuracy under adaptive attacks. Adversarial training of the backbone classifier can further increase resistance of the front-end enhanced model to gradient attacks. On CIFAR10, the respective randomized ensemble achieved 90.8$\pm 2.5$% (99% CI) accuracy under AutoAttack while having only 18.2$\pm 3.6$% accuracy under the adaptive attack. We do not establish SOTA in adversarial robustness. Instead, we make methodological contributions and further supports the thesis that adaptive attacks designed with the complete knowledge of model architecture are crucial in demonstrating model robustness and that even the so-called white-box gradient attacks can have limited applicability. Although gradient attacks can be complemented with black-box attack such as the SQUARE attack or the zero-order PGD, black-box attacks can be weak against randomized ensembles, e.g., when ensemble models mask gradients.
PriViT: Vision Transformers for Fast Private Inference
Oct 06, 2023



The Vision Transformer (ViT) architecture has emerged as the backbone of choice for state-of-the-art deep models for computer vision applications. However, ViTs are ill-suited for private inference using secure multi-party computation (MPC) protocols, due to the large number of non-polynomial operations (self-attention, feed-forward rectifiers, layer normalization). We propose PriViT, a gradient based algorithm to selectively "Taylorize" nonlinearities in ViTs while maintaining their prediction accuracy. Our algorithm is conceptually simple, easy to implement, and achieves improved performance over existing approaches for designing MPC-friendly transformer architectures in terms of achieving the Pareto frontier in latency-accuracy. We confirm these improvements via experiments on several standard image classification tasks. Public code is available at https://github.com/NYU-DICE-Lab/privit.
Distributionally Robust Classification on a Data Budget
Aug 07, 2023



Real world uses of deep learning require predictable model behavior under distribution shifts. Models such as CLIP show emergent natural distributional robustness comparable to humans, but may require hundreds of millions of training samples. Can we train robust learners in a domain where data is limited? To rigorously address this question, we introduce JANuS (Joint Annotations and Names Set), a collection of four new training datasets with images, labels, and corresponding captions, and perform a series of carefully controlled investigations of factors contributing to robustness in image classification, then compare those results to findings derived from a large-scale meta-analysis. Using this approach, we show that standard ResNet-50 trained with the cross-entropy loss on 2.4 million image samples can attain comparable robustness to a CLIP ResNet-50 trained on 400 million samples. To our knowledge, this is the first result showing (near) state-of-the-art distributional robustness on limited data budgets. Our dataset is available at \url{https://huggingface.co/datasets/penfever/JANuS_dataset}, and the code used to reproduce our experiments can be found at \url{https://github.com/penfever/vlhub/}.
Identity-Preserving Aging of Face Images via Latent Diffusion Models
Jul 17, 2023



The performance of automated face recognition systems is inevitably impacted by the facial aging process. However, high quality datasets of individuals collected over several years are typically small in scale. In this work, we propose, train, and validate the use of latent text-to-image diffusion models for synthetically aging and de-aging face images. Our models succeed with few-shot training, and have the added benefit of being controllable via intuitive textual prompting. We observe high degrees of visual realism in the generated images while maintaining biometric fidelity measured by commonly used metrics. We evaluate our method on two benchmark datasets (CelebA and AgeDB) and observe significant reduction (~44%) in the False Non-Match Rate compared to existing state-of the-art baselines.
Vision-Language Models can Identify Distracted Driver Behavior from Naturalistic Videos
Jun 22, 2023Recognizing the activities, causing distraction, in real-world driving scenarios is critical for ensuring the safety and reliability of both drivers and pedestrians on the roadways. Conventional computer vision techniques are typically data-intensive and require a large volume of annotated training data to detect and classify various distracted driving behaviors, thereby limiting their efficiency and scalability. We aim to develop a generalized framework that showcases robust performance with access to limited or no annotated training data. Recently, vision-language models have offered large-scale visual-textual pretraining that can be adapted to task-specific learning like distracted driving activity recognition. Vision-language pretraining models, such as CLIP, have shown significant promise in learning natural language-guided visual representations. This paper proposes a CLIP-based driver activity recognition approach that identifies driver distraction from naturalistic driving images and videos. CLIP's vision embedding offers zero-shot transfer and task-based finetuning, which can classify distracted activities from driving video data. Our results show that this framework offers state-of-the-art performance on zero-shot transfer and video-based CLIP for predicting the driver's state on two public datasets. We propose both frame-based and video-based frameworks developed on top of the CLIP's visual representation for distracted driving detection and classification task and report the results.
ZeroForge: Feedforward Text-to-Shape Without 3D Supervision
Jun 16, 2023



Current state-of-the-art methods for text-to-shape generation either require supervised training using a labeled dataset of pre-defined 3D shapes, or perform expensive inference-time optimization of implicit neural representations. In this work, we present ZeroForge, an approach for zero-shot text-to-shape generation that avoids both pitfalls. To achieve open-vocabulary shape generation, we require careful architectural adaptation of existing feed-forward approaches, as well as a combination of data-free CLIP-loss and contrastive losses to avoid mode collapse. Using these techniques, we are able to considerably expand the generative ability of existing feed-forward text-to-shape models such as CLIP-Forge. We support our method via extensive qualitative and quantitative evaluations
Caption supervision enables robust learners
Oct 13, 2022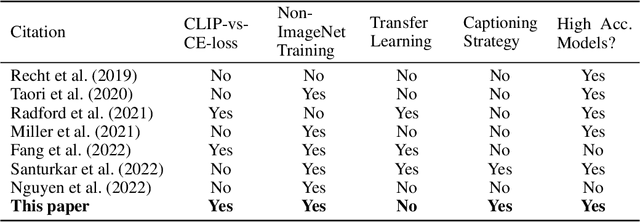
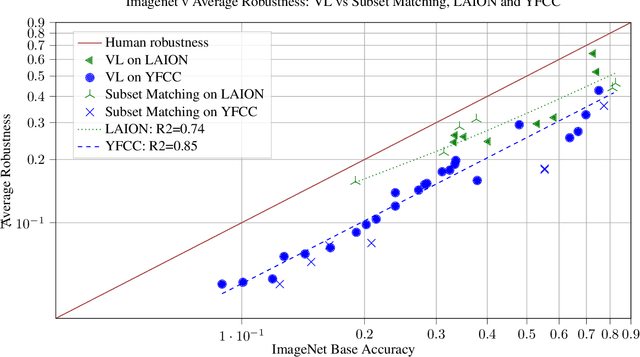


Vision language models like CLIP are robust to natural distribution shifts, in part because CLIP learns on unstructured data using a technique called caption supervision; the model inteprets image-linked texts as ground-truth labels. In a carefully controlled comparison study, we show that CNNs trained on a standard cross-entropy loss can also benefit from caption supervision, in some cases even more than VL models, on the same data. To facilitate future experiments with high-accuracy caption-supervised models, we introduce CaptionNet (https://github.com/penfever/CaptionNet/), which includes a class-balanced, fully supervised dataset with over 50,000 new human-labeled ImageNet-compliant samples which includes web-scraped captions. In a series of experiments on CaptionNet, we show how the choice of loss function, data filtration and supervision strategy enable robust computer vision. We also provide the codebase necessary to reproduce our experiments at https://github.com/penfever/vlhub/
Revisiting Self-Distillation
Jun 17, 2022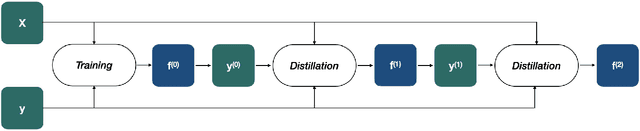
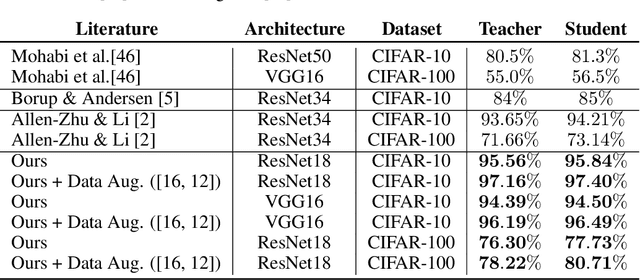
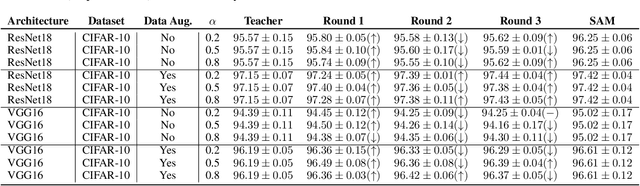
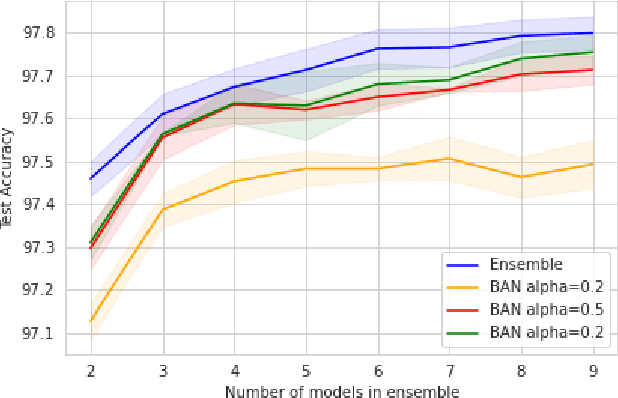
Knowledge distillation is the procedure of transferring "knowledge" from a large model (the teacher) to a more compact one (the student), often being used in the context of model compression. When both models have the same architecture, this procedure is called self-distillation. Several works have anecdotally shown that a self-distilled student can outperform the teacher on held-out data. In this work, we systematically study self-distillation in a number of settings. We first show that even with a highly accurate teacher, self-distillation allows a student to surpass the teacher in all cases. Secondly, we revisit existing theoretical explanations of (self) distillation and identify contradicting examples, revealing possible drawbacks of these explanations. Finally, we provide an alternative explanation for the dynamics of self-distillation through the lens of loss landscape geometry. We conduct extensive experiments to show that self-distillation leads to flatter minima, thereby resulting in better generalization.
A Meta-Analysis of Distributionally-Robust Models
Jun 15, 2022
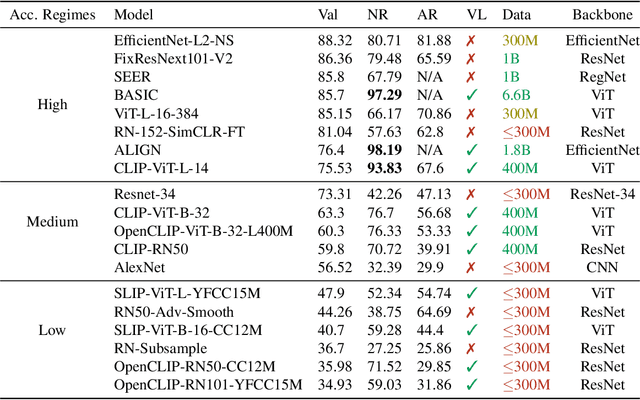
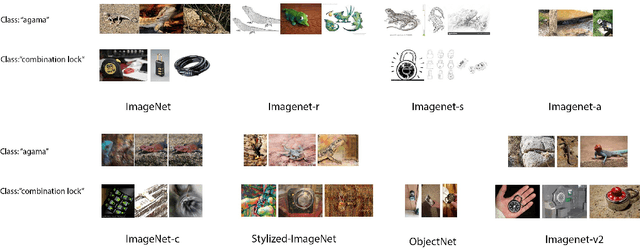
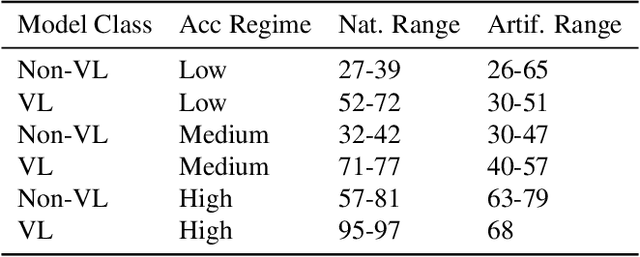
State-of-the-art image classifiers trained on massive datasets (such as ImageNet) have been shown to be vulnerable to a range of both intentional and incidental distribution shifts. On the other hand, several recent classifiers with favorable out-of-distribution (OOD) robustness properties have emerged, achieving high accuracy on their target tasks while maintaining their in-distribution accuracy on challenging benchmarks. We present a meta-analysis on a wide range of publicly released models, most of which have been published over the last twelve months. Through this meta-analysis, we empirically identify four main commonalities for all the best-performing OOD-robust models, all of which illuminate the considerable promise of vision-language pre-training.