 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GGRt: Towards Pose-free Generalizable 3D Gaussian Splatting in Real-time
Mar 19, 2024
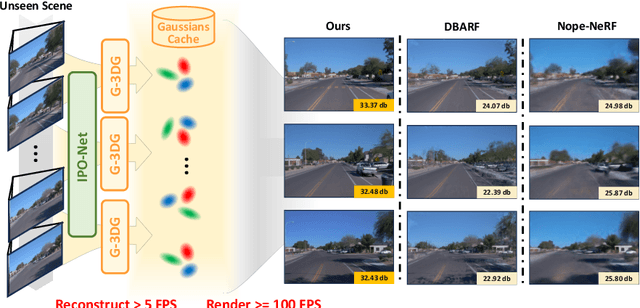
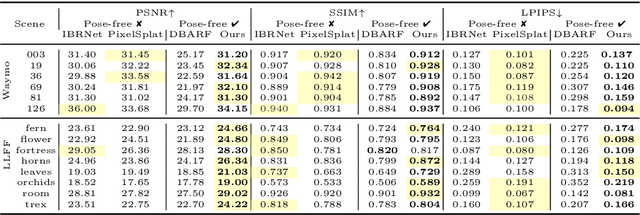
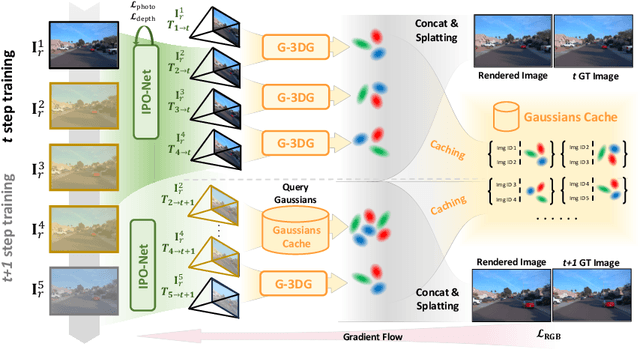

This paper presents GGRt, a novel approach to generalizable novel view synthesis that alleviates the need for real camera poses, complexity in processing high-resolution images, and lengthy optimization processes, thus facilitating stronger applicability of 3D Gaussian Splatting (3D-GS) in real-world scenarios. Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model. With the joint learning mechanism, the proposed framework can inherently estimate robust relative pose information from the image observations and thus primarily alleviate the requirement of real camera poses. Moreover, we implement a deferred back-propagation mechanism that enables high-resolution training and inference, overcoming the resolution constraints of previous methods. To enhance the speed and efficiency, we further introduce a progressive Gaussian cache module that dynamically adjusts during training and inference. As the first pose-free generalizable 3D-GS framework, GGRt achieves inference at $\ge$ 5 FPS and real-time rendering at $\ge$ 100 FPS. Through extensive experimentation, we demonstrate that our method outperforms existing NeRF-based pose-free techniques in terms of inference speed and effectiveness. It can also approach the real pose-based 3D-GS methods. Our contributions provide a significant leap forward for the integration of computer vision and computer graphics into practical applications, offering state-of-the-art results on LLFF, KITTI, and Waymo Open datasets and enabling real-time rendering for immersive experiences.
Biophysics Informed Pathological Regularisation for Brain Tumour Segmentation
Mar 18, 2024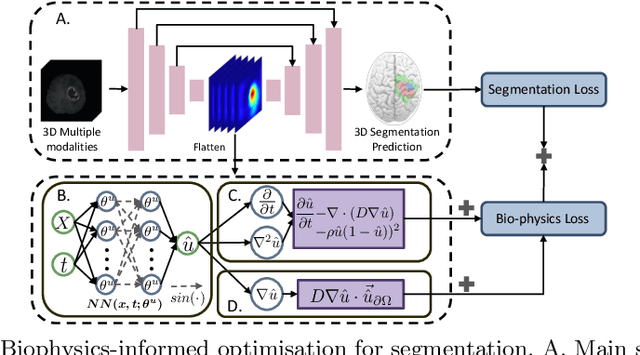
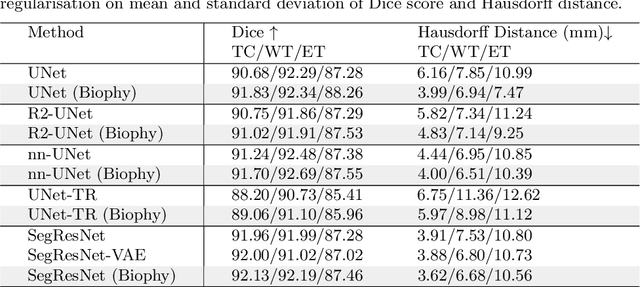
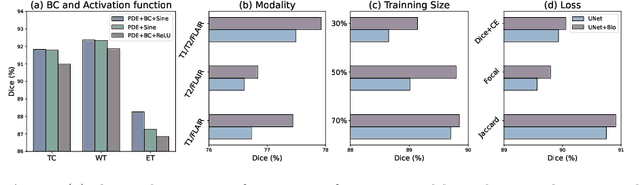
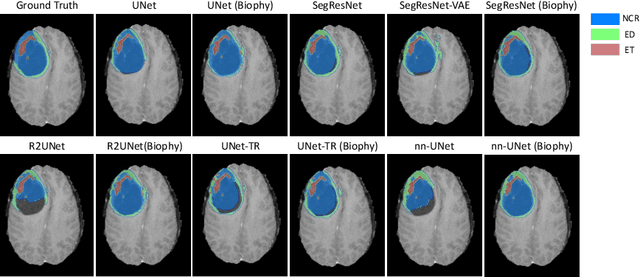
Recent advancements in deep learning have significantly improved brain tumour segmentation techniques; however, the results still lack confidence and robustness as they solely consider image data without biophysical priors or pathological information. Integrating biophysics-informed regularisation is one effective way to change this situation, as it provides an prior regularisation for automated end-to-end learning. In this paper, we propose a novel approach that designs brain tumour growth Partial Differential Equation (PDE) models as a regularisation with deep learning, operational with any network model. Our method introduces tumour growth PDE models directly into the segmentation process, improving accuracy and robustness, especially in data-scarce scenarios. This system estimates tumour cell density using a periodic activation function. By effectively integrating this estimation with biophysical models, we achieve a better capture of tumour characteristics. This approach not only aligns the segmentation closer to actual biological behaviour but also strengthens the model's performance under limited data conditions. We demonstrate the effectiveness of our framework through extensive experiments on the BraTS 2023 dataset, showcasing significant improvements in both precision and reliability of tumour segmentation.
Point Mamba: A Novel Point Cloud Backbone Based on State Space Model with Octree-Based Ordering Strategy
Mar 18, 2024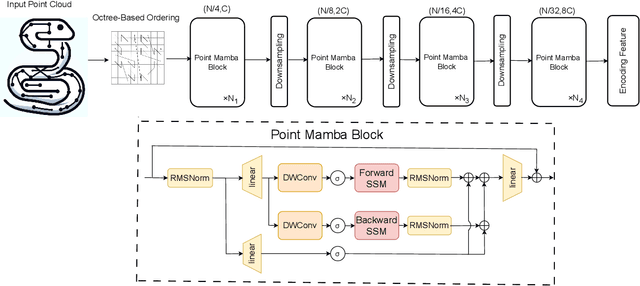
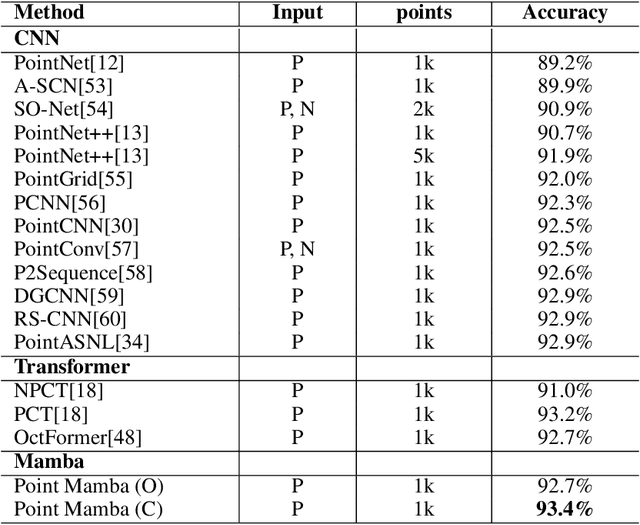
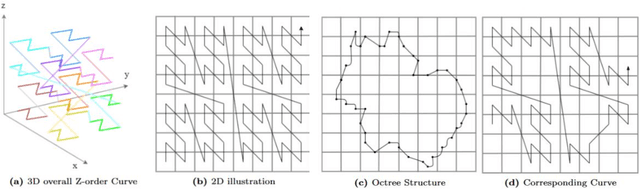
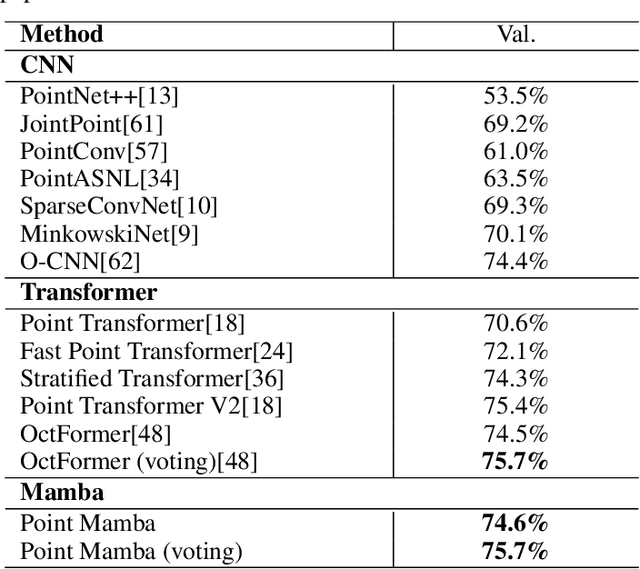
Recently, state space model (SSM) has gained great attention due to its promising performance, linear complexity, and long sequence modeling ability in both language and image domains. However, it is non-trivial to extend SSM to the point cloud field, because of the causality requirement of SSM and the disorder and irregularity nature of point clouds. In this paper, we propose a novel SSM-based point cloud processing backbone, named Point Mamba, with a causality-aware ordering mechanism. To construct the causal dependency relationship, we design an octree-based ordering strategy on raw irregular points, globally sorting points in a z-order sequence and also retaining their spatial proximity. Our method achieves state-of-the-art performance compared with transformer-based counterparts, with 93.4% accuracy and 75.7 mIOU respectively on the ModelNet40 classification dataset and ScanNet semantic segmentation dataset. Furthermore, our Point Mamba has linear complexity, which is more efficient than transformer-based methods. Our method demonstrates the great potential that SSM can serve as a generic backbone in point cloud understanding. Codes are released at https://github.com/IRMVLab/Point-Mamba.
Binary Noise for Binary Tasks: Masked Bernoulli Diffusion for Unsupervised Anomaly Detection
Mar 18, 2024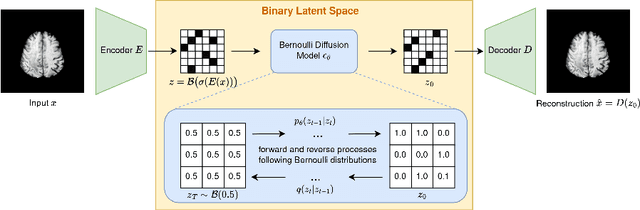
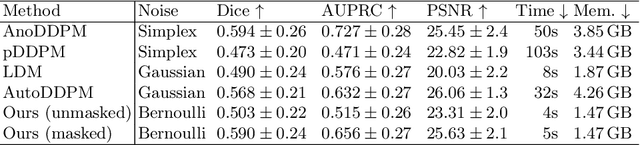
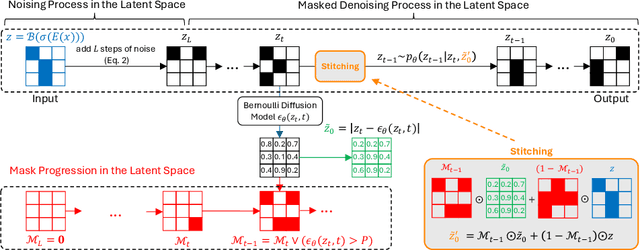
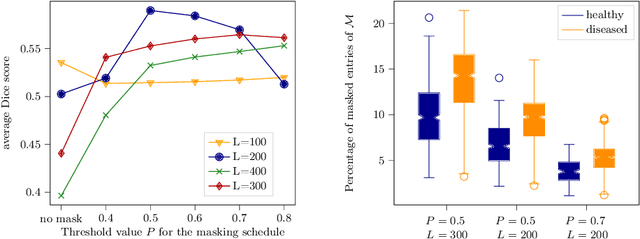
The high performance of denoising diffusion models for image generation has paved the way for their application in unsupervised medical anomaly detection. As diffusion-based methods require a lot of GPU memory and have long sampling times, we present a novel and fast unsupervised anomaly detection approach based on latent Bernoulli diffusion models. We first apply an autoencoder to compress the input images into a binary latent representation. Next, a diffusion model that follows a Bernoulli noise schedule is employed to this latent space and trained to restore binary latent representations from perturbed ones. The binary nature of this diffusion model allows us to identify entries in the latent space that have a high probability of flipping their binary code during the denoising process, which indicates out-of-distribution data. We propose a masking algorithm based on these probabilities, which improves the anomaly detection scores. We achieve state-of-the-art performance compared to other diffusion-based unsupervised anomaly detection algorithms while significantly reducing sampling time and memory consumption. The code is available at https://github.com/JuliaWolleb/Anomaly_berdiff.
LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation
Mar 18, 2024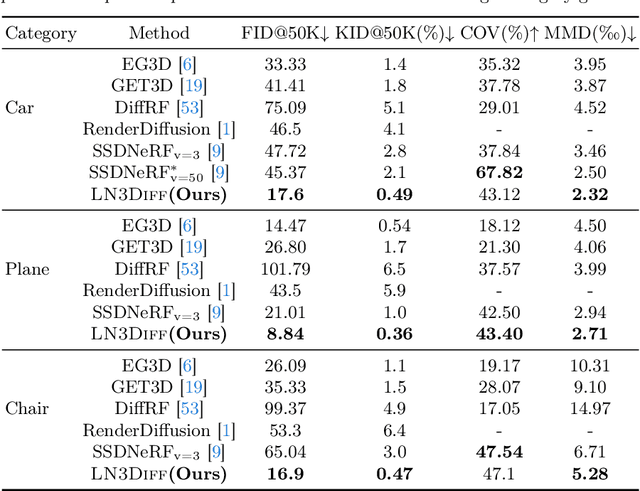
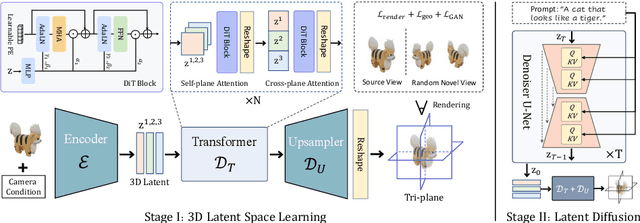

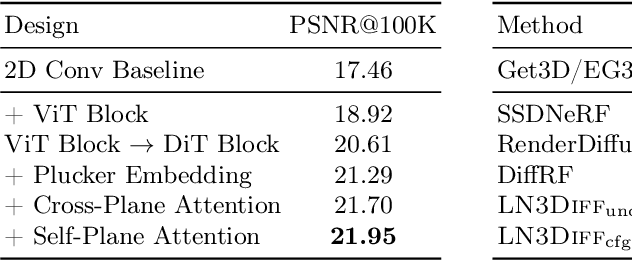
The field of neural rendering has witnessed significant progress with advancements in generative models and differentiable rendering techniques. Though 2D diffusion has achieved success, a unified 3D diffusion pipeline remains unsettled. This paper introduces a novel framework called LN3Diff to address this gap and enable fast, high-quality, and generic conditional 3D generation. Our approach harnesses a 3D-aware architecture and variational autoencoder (VAE) to encode the input image into a structured, compact, and 3D latent space. The latent is decoded by a transformer-based decoder into a high-capacity 3D neural field. Through training a diffusion model on this 3D-aware latent space, our method achieves state-of-the-art performance on ShapeNet for 3D generation and demonstrates superior performance in monocular 3D reconstruction and conditional 3D generation across various datasets. Moreover, it surpasses existing 3D diffusion methods in terms of inference speed, requiring no per-instance optimization. Our proposed LN3Diff presents a significant advancement in 3D generative modeling and holds promise for various applications in 3D vision and graphics tasks.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Mar 18, 2024
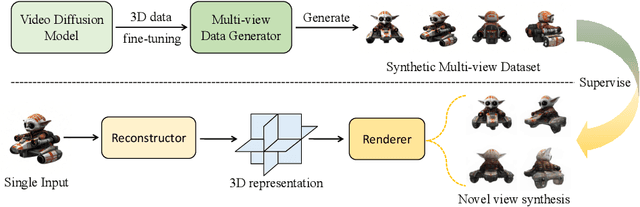
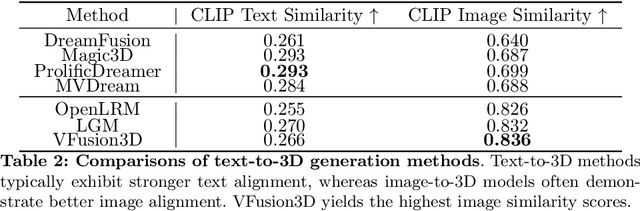

This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
Sub-photon accuracy noise reduction of single shot coherent diffraction pattern with atomic model trained autoencoder
Mar 18, 2024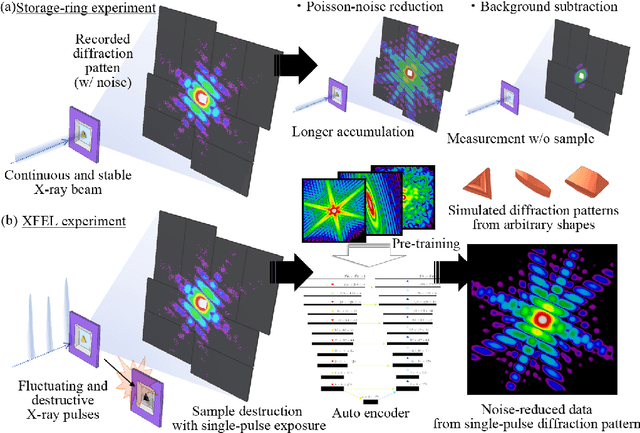
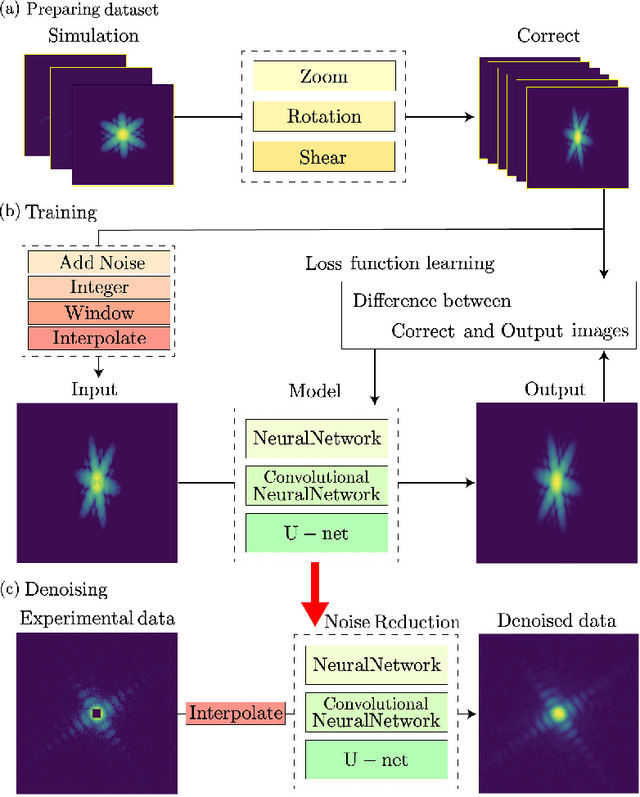
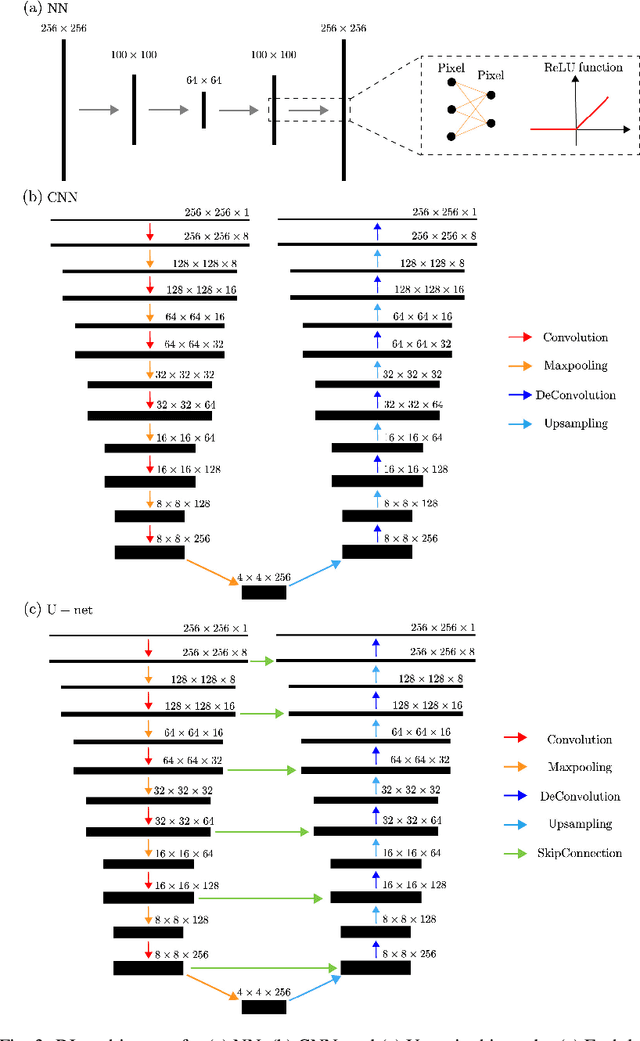
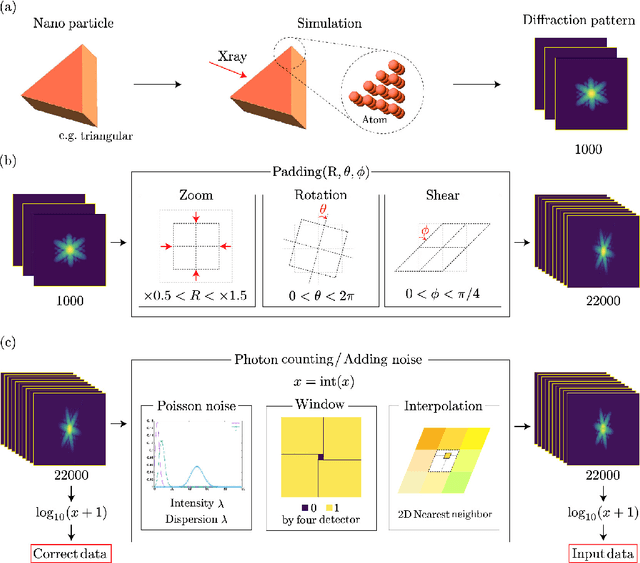
Single-shot imaging with femtosecond X-ray lasers is a powerful measurement technique that can achieve both high spatial and temporal resolution. However, its accuracy has been severely limited by the difficulty of applying conventional noise-reduction processing. This study uses deep learning to validate noise reduction techniques, with autoencoders serving as the learning model. Focusing on the diffraction patterns of nanoparticles, we simulated a large dataset treating the nanoparticles as composed of many independent atoms. Three neural network architectures are investigated: neural network, convolutional neural network and U-net, with U-net showing superior performance in noise reduction and subphoton reproduction. We also extended our models to apply to diffraction patterns of particle shapes different from those in the simulated data. We then applied the U-net model to a coherent diffractive imaging study, wherein a nanoparticle in a microfluidic device is exposed to a single X-ray free-electron laser pulse. After noise reduction, the reconstructed nanoparticle image improved significantly even though the nanoparticle shape was different from the training data, highlighting the importance of transfer learning.
PAON: A New Neuron Model using Padé Approximants
Mar 18, 2024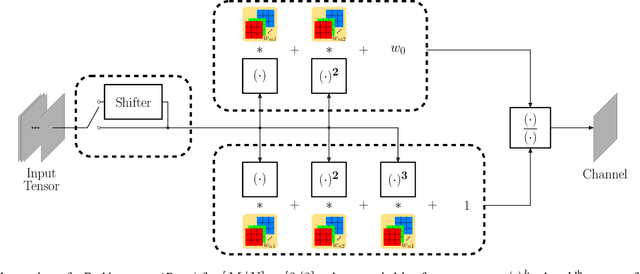

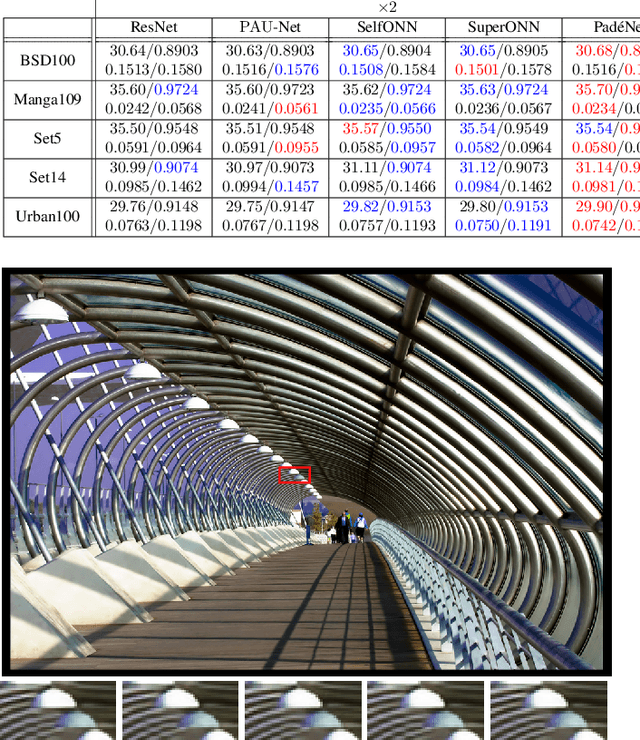
Convolutional neural networks (CNN) are built upon the classical McCulloch-Pitts neuron model, which is essentially a linear model, where the nonlinearity is provided by a separate activation function. Several researchers have proposed enhanced neuron models, including quadratic neurons, generalized operational neurons, generative neurons, and super neurons, with stronger nonlinearity than that provided by the pointwise activation function. There has also been a proposal to use Pade approximation as a generalized activation function. In this paper, we introduce a brand new neuron model called Pade neurons (Paons), inspired by the Pade approximants, which is the best mathematical approximation of a transcendental function as a ratio of polynomials with different orders. We show that Paons are a super set of all other proposed neuron models. Hence, the basic neuron in any known CNN model can be replaced by Paons. In this paper, we extend the well-known ResNet to PadeNet (built by Paons) to demonstrate the concept. Our experiments on the single-image super-resolution task show that PadeNets can obtain better results than competing architectures.
Dynamic Tuning Towards Parameter and Inference Efficiency for ViT Adaptation
Mar 18, 2024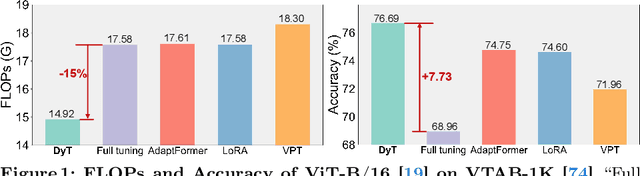

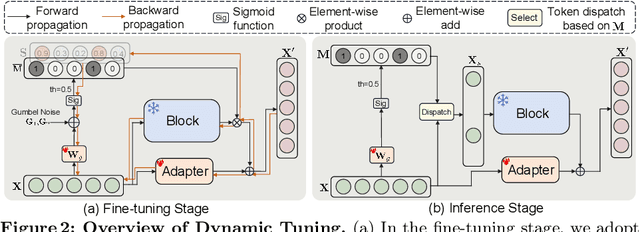

Existing parameter-efficient fine-tuning (PEFT) methods have achieved significant success on vision transformers (ViTs) adaptation by improving parameter efficiency. However, the exploration of enhancing inference efficiency during adaptation remains underexplored. This limits the broader application of pre-trained ViT models, especially when the model is computationally extensive. In this paper, we propose Dynamic Tuning (DyT), a novel approach to improve both parameter and inference efficiency for ViT adaptation. Specifically, besides using the lightweight adapter modules, we propose a token dispatcher to distinguish informative tokens from less important ones, allowing the latter to dynamically skip the original block, thereby reducing the redundant computation during inference. Additionally, we explore multiple design variants to find the best practice of DyT. Finally, inspired by the mixture-of-experts (MoE) mechanism, we introduce an enhanced adapter to further boost the adaptation performance. We validate DyT across various tasks, including image/video recognition and semantic segmentation. For instance, DyT achieves comparable or even superior performance compared to existing PEFT methods while evoking only 71%-85% of their FLOPs on the VTAB-1K benchmark.
Fed3DGS: Scalable 3D Gaussian Splatting with Federated Learning
Mar 18, 2024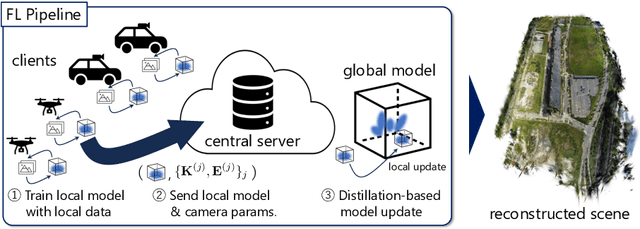
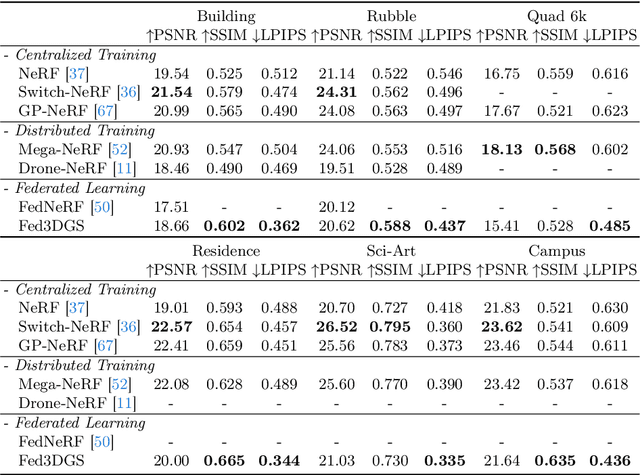
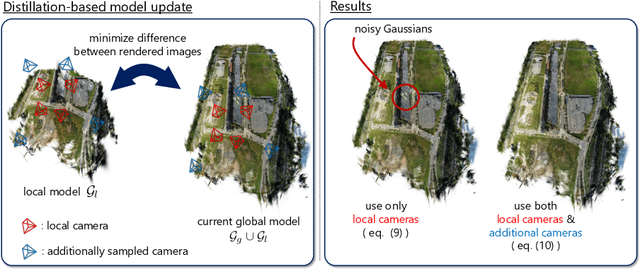

In this work, we present Fed3DGS, a scalable 3D reconstruction framework based on 3D Gaussian splatting (3DGS) with federated learning. Existing city-scale reconstruction methods typically adopt a centralized approach, which gathers all data in a central server and reconstructs scenes. The approach hampers scalability because it places a heavy load on the server and demands extensive data storage when reconstructing scenes on a scale beyond city-scale. In pursuit of a more scalable 3D reconstruction, we propose a federated learning framework with 3DGS, which is a decentralized framework and can potentially use distributed computational resources across millions of clients. We tailor a distillation-based model update scheme for 3DGS and introduce appearance modeling for handling non-IID data in the scenario of 3D reconstruction with federated learning. We simulate our method on several large-scale benchmarks, and our method demonstrates rendered image quality comparable to centralized approaches. In addition, we also simulate our method with data collected in different seasons, demonstrating that our framework can reflect changes in the scenes and our appearance modeling captures changes due to seasonal variations.