 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFFS: Adversarial Deformations for Facial Feminization Surgery Planning
Mar 02, 2026Facial feminization surgery (FFS) is a key component of gender affirmation for transgender and gender diverse patients, aiming to reshape craniofacial structures toward a female morphology. Current surgical planning procedures largely rely on subjective clinical assessment, lacking quantitative and reproducible anatomical guidance. We therefore propose AutoFFS, a novel data-driven framework that generates counterfactual skull morphologies through adversarial free-form deformations. Our method performs a deformation-based targeted adversarial attack on an ensemble of pre-trained binary sex classifiers that learned sexual dimorphism, effectively transforming individual skull shapes toward the target sex. The generated counterfactual skull morphologies provide a quantitative foundation for preoperative planning in FFS, driving advances in this largely overlooked patient group. We validate our approach through classifier-based evaluation and a human perceptual study, confirming that the generated morphologies exhibit target sex characteristics.
Optimizing Rank for High-Fidelity Implicit Neural Representations
Dec 16, 2025Implicit Neural Representations (INRs) based on vanilla Multi-Layer Perceptrons (MLPs) are widely believed to be incapable of representing high-frequency content. This has directed research efforts towards architectural interventions, such as coordinate embeddings or specialized activation functions, to represent high-frequency signals. In this paper, we challenge the notion that the low-frequency bias of vanilla MLPs is an intrinsic, architectural limitation to learn high-frequency content, but instead a symptom of stable rank degradation during training. We empirically demonstrate that regulating the network's rank during training substantially improves the fidelity of the learned signal, rendering even simple MLP architectures expressive. Extensive experiments show that using optimizers like Muon, with high-rank, near-orthogonal updates, consistently enhances INR architectures even beyond simple ReLU MLPs. These substantial improvements hold across a diverse range of domains, including natural and medical images, and novel view synthesis, with up to 9 dB PSNR improvements over the previous state-of-the-art. Our project page, which includes code and experimental results, is available at: (https://muon-inrs.github.io).
Fine-tuning Behavioral Cloning Policies with Preference-Based Reinforcement Learning
Sep 30, 2025Deploying reinforcement learning (RL) in robotics, industry, and health care is blocked by two obstacles: the difficulty of specifying accurate rewards and the risk of unsafe, data-hungry exploration. We address this by proposing a two-stage framework that first learns a safe initial policy from a reward-free dataset of expert demonstrations, then fine-tunes it online using preference-based human feedback. We provide the first principled analysis of this offline-to-online approach and introduce BRIDGE, a unified algorithm that integrates both signals via an uncertainty-weighted objective. We derive regret bounds that shrink with the number of offline demonstrations, explicitly connecting the quantity of offline data to online sample efficiency. We validate BRIDGE in discrete and continuous control MuJoCo environments, showing it achieves lower regret than both standalone behavioral cloning and online preference-based RL. Our work establishes a theoretical foundation for designing more sample-efficient interactive agents.
Towards MR-Based Trochleoplasty Planning
Aug 08, 2025To treat Trochlear Dysplasia (TD), current approaches rely mainly on low-resolution clinical Magnetic Resonance (MR) scans and surgical intuition. The surgeries are planned based on surgeons experience, have limited adoption of minimally invasive techniques, and lead to inconsistent outcomes. We propose a pipeline that generates super-resolved, patient-specific 3D pseudo-healthy target morphologies from conventional clinical MR scans. First, we compute an isotropic super-resolved MR volume using an Implicit Neural Representation (INR). Next, we segment femur, tibia, patella, and fibula with a multi-label custom-trained network. Finally, we train a Wavelet Diffusion Model (WDM) to generate pseudo-healthy target morphologies of the trochlear region. In contrast to prior work producing pseudo-healthy low-resolution 3D MR images, our approach enables the generation of sub-millimeter resolved 3D shapes compatible for pre- and intraoperative use. These can serve as preoperative blueprints for reshaping the femoral groove while preserving the native patella articulation. Furthermore, and in contrast to other work, we do not require a CT for our pipeline - reducing the amount of radiation. We evaluated our approach on 25 TD patients and could show that our target morphologies significantly improve the sulcus angle (SA) and trochlear groove depth (TGD). The code and interactive visualization are available at https://wehrlimi.github.io/sr-3d-planning/.
VidFuncta: Towards Generalizable Neural Representations for Ultrasound Videos
Jul 29, 2025Ultrasound is widely used in clinical care, yet standard deep learning methods often struggle with full video analysis due to non-standardized acquisition and operator bias. We offer a new perspective on ultrasound video analysis through implicit neural representations (INRs). We build on Functa, an INR framework in which each image is represented by a modulation vector that conditions a shared neural network. However, its extension to the temporal domain of medical videos remains unexplored. To address this gap, we propose VidFuncta, a novel framework that leverages Functa to encode variable-length ultrasound videos into compact, time-resolved representations. VidFuncta disentangles each video into a static video-specific vector and a sequence of time-dependent modulation vectors, capturing both temporal dynamics and dataset-level redundancies. Our method outperforms 2D and 3D baselines on video reconstruction and enables downstream tasks to directly operate on the learned 1D modulation vectors. We validate VidFuncta on three public ultrasound video datasets -- cardiac, lung, and breast -- and evaluate its downstream performance on ejection fraction prediction, B-line detection, and breast lesion classification. These results highlight the potential of VidFuncta as a generalizable and efficient representation framework for ultrasound videos. Our code is publicly available under https://github.com/JuliaWolleb/VidFuncta_public.
fastWDM3D: Fast and Accurate 3D Healthy Tissue Inpainting
Jul 17, 2025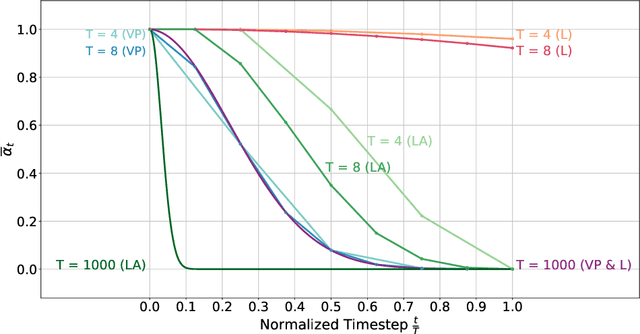
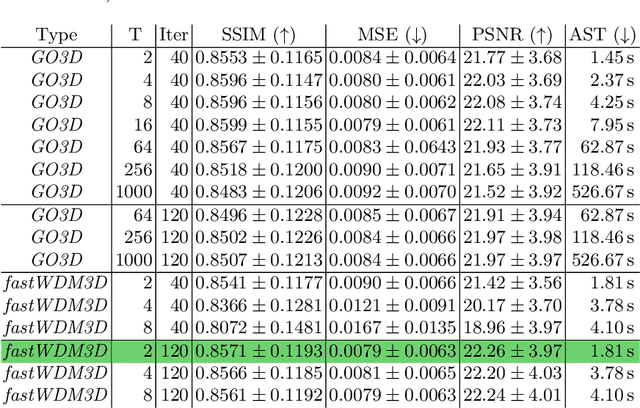
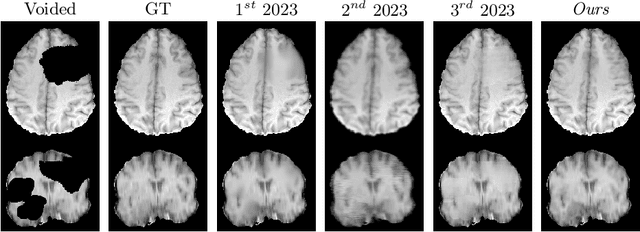
Healthy tissue inpainting has significant applications, including the generation of pseudo-healthy baselines for tumor growth models and the facilitation of image registration. In previous editions of the BraTS Local Synthesis of Healthy Brain Tissue via Inpainting Challenge, denoising diffusion probabilistic models (DDPMs) demonstrated qualitatively convincing results but suffered from low sampling speed. To mitigate this limitation, we adapted a 2D image generation approach, combining DDPMs with generative adversarial networks (GANs) and employing a variance-preserving noise schedule, for the task of 3D inpainting. Our experiments showed that the variance-preserving noise schedule and the selected reconstruction losses can be effectively utilized for high-quality 3D inpainting in a few time steps without requiring adversarial training. We applied our findings to a different architecture, a 3D wavelet diffusion model (WDM3D) that does not include a GAN component. The resulting model, denoted as fastWDM3D, obtained a SSIM of 0.8571, a MSE of 0.0079, and a PSNR of 22.26 on the BraTS inpainting test set. Remarkably, it achieved these scores using only two time steps, completing the 3D inpainting process in 1.81 s per image. When compared to other DDPMs used for healthy brain tissue inpainting, our model is up to 800 x faster while still achieving superior performance metrics. Our proposed method, fastWDM3D, represents a promising approach for fast and accurate healthy tissue inpainting. Our code is available at https://github.com/AliciaDurrer/fastWDM3D.
MedFuncta: Modality-Agnostic Representations Based on Efficient Neural Fields
Feb 20, 2025



Recent research in medical image analysis with deep learning almost exclusively focuses on grid- or voxel-based data representations. We challenge this common choice by introducing MedFuncta, a modality-agnostic continuous data representation based on neural fields. We demonstrate how to scale neural fields from single instances to large datasets by exploiting redundancy in medical signals and by applying an efficient meta-learning approach with a context reduction scheme. We further address the spectral bias in commonly used SIREN activations, by introducing an $\omega_0$-schedule, improving reconstruction quality and convergence speed. We validate our proposed approach on a large variety of medical signals of different dimensions and modalities (1D: ECG; 2D: Chest X-ray, Retinal OCT, Fundus Camera, Dermatoscope, Colon Histopathology, Cell Microscopy; 3D: Brain MRI, Lung CT) and successfully demonstrate that we can solve relevant downstream tasks on these representations. We additionally release a large-scale dataset of > 550k annotated neural fields to promote research in this direction.
Generating 3D Pseudo-Healthy Knee MR Images to Support Trochleoplasty Planning
Dec 13, 2024



Purpose: Trochlear Dysplasia (TD) is a common malformation in adolescents, leading to anterior knee pain and instability. Surgical interventions such as trochleoplasty require precise planning to correct the trochlear groove. However, no standardized preoperative plan exists to guide surgeons in reshaping the femur. This study aims to generate patient-specific, pseudo-healthy MR images of the trochlear region that should theoretically align with the respective patient's patella, potentially supporting the pre-operative planning of trochleoplasty. Methods: We employ a Wavelet Diffusion Model (WDM) to generate personalized pseudo-healthy, anatomically plausible MR scans of the trochlear region. We train our model using knee MR scans of healthy subjects. During inference, we mask out pathological regions around the patella in scans of patients affected by TD, and replace them with their pseudo-healthy counterpart. An orthopedic surgeon measured the sulcus angle (SA), trochlear groove depth (TGD) and D\'ejour classification in MR scans before and after inpainting. The code is available at https://github.com/wehrlimi/Generate-Pseudo-Healthy-Knee-MRI . Results: The inpainting by our model significantly improves the SA, TGD and D\'ejour classification in a study with 49 knee MR scans. Conclusion: This study demonstrates the potential of WDMs in providing surgeons with patient-specific guidance. By offering anatomically plausible MR scans, the method could potentially enhance the precision and preoperative planning of trochleoplasty, and pave the way to more minimally invasive surgeries.
cWDM: Conditional Wavelet Diffusion Models for Cross-Modality 3D Medical Image Synthesis
Nov 26, 2024



This paper contributes to the "BraTS 2024 Brain MR Image Synthesis Challenge" and presents a conditional Wavelet Diffusion Model (cWDM) for directly solving a paired image-to-image translation task on high-resolution volumes. While deep learning-based brain tumor segmentation models have demonstrated clear clinical utility, they typically require MR scans from various modalities (T1, T1ce, T2, FLAIR) as input. However, due to time constraints or imaging artifacts, some of these modalities may be missing, hindering the application of well-performing segmentation algorithms in clinical routine. To address this issue, we propose a method that synthesizes one missing modality image conditioned on three available images, enabling the application of downstream segmentation models. We treat this paired image-to-image translation task as a conditional generation problem and solve it by combining a Wavelet Diffusion Model for high-resolution 3D image synthesis with a simple conditioning strategy. This approach allows us to directly apply our model to full-resolution volumes, avoiding artifacts caused by slice- or patch-wise data processing. While this work focuses on a specific application, the presented method can be applied to all kinds of paired image-to-image translation problems, such as CT $\leftrightarrow$ MR and MR $\leftrightarrow$ PET translation, or mask-conditioned anatomically guided image generation.
Deep Generative Models for 3D Medical Image Synthesis
Oct 23, 2024



Deep generative modeling has emerged as a powerful tool for synthesizing realistic medical images, driving advances in medical image analysis, disease diagnosis, and treatment planning. This chapter explores various deep generative models for 3D medical image synthesis, with a focus on Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and Denoising Diffusion Models (DDMs). We discuss the fundamental principles, recent advances, as well as strengths and weaknesses of these models and examine their applications in clinically relevant problems, including unconditional and conditional generation tasks like image-to-image translation and image reconstruction. We additionally review commonly used evaluation metrics for assessing image fidelity, diversity, utility, and privacy and provide an overview of current challenges in the field.