 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
Mar 21, 2024
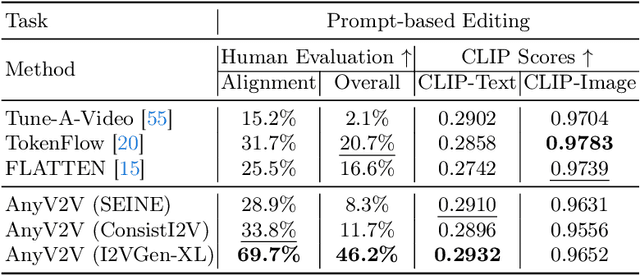
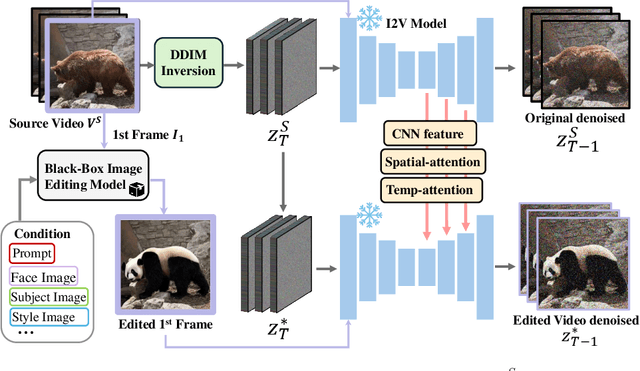
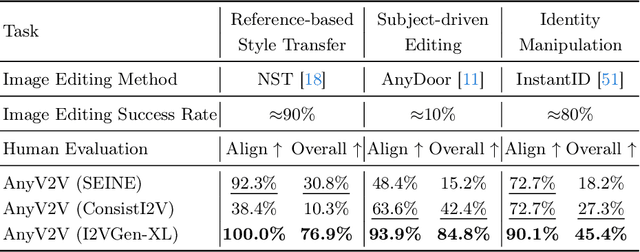

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands. In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection. In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference. On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate the fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.
Chain-of-Spot: Interactive Reasoning Improves Large Vision-Language Models
Mar 21, 2024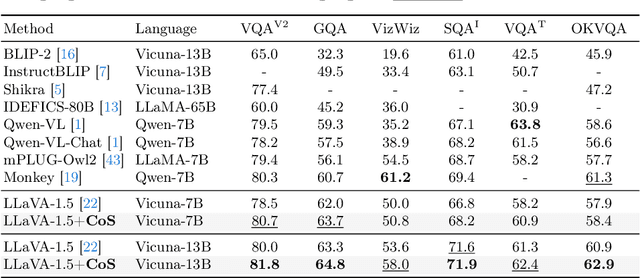
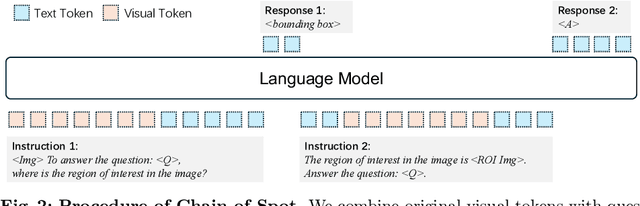
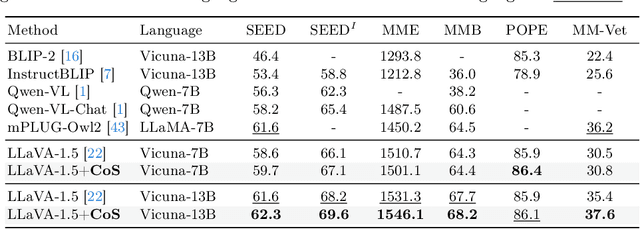

In the realm of vision-language understanding, the proficiency of models in interpreting and reasoning over visual content has become a cornerstone for numerous applications. However, it is challenging for the visual encoder in Large Vision-Language Models (LVLMs) to extract useful features tailored to questions that aid the language model's response. Furthermore, a common practice among existing LVLMs is to utilize lower-resolution images, which restricts the ability for visual recognition. Our work introduces the Chain-of-Spot (CoS) method, which we describe as Interactive Reasoning, a novel approach that enhances feature extraction by focusing on key regions of interest (ROI) within the image, corresponding to the posed questions or instructions. This technique allows LVLMs to access more detailed visual information without altering the original image resolution, thereby offering multi-granularity image features. By integrating Chain-of-Spot with instruct-following LLaVA-1.5 models, the process of image reasoning consistently improves performance across a wide range of multimodal datasets and benchmarks without bells and whistles and achieves new state-of-the-art results. Our empirical findings demonstrate a significant improvement in LVLMs' ability to understand and reason about visual content, paving the way for more sophisticated visual instruction-following applications. Code and models are available at https://github.com/dongyh20/Chain-of-Spot
Videoshop: Localized Semantic Video Editing with Noise-Extrapolated Diffusion Inversion
Mar 22, 2024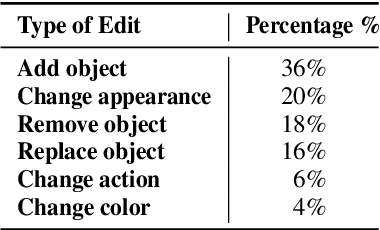
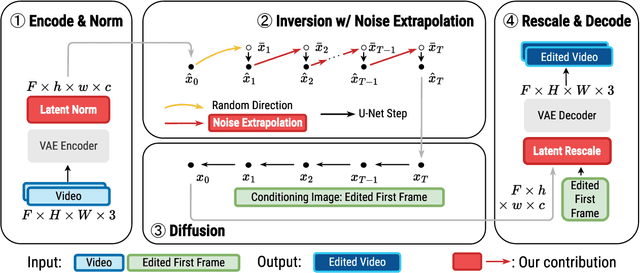
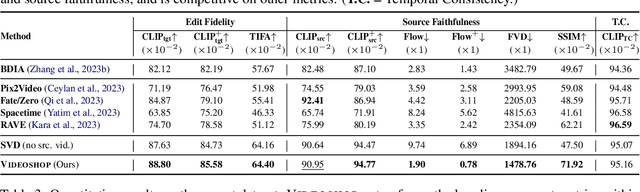
We introduce Videoshop, a training-free video editing algorithm for localized semantic edits. Videoshop allows users to use any editing software, including Photoshop and generative inpainting, to modify the first frame; it automatically propagates those changes, with semantic, spatial, and temporally consistent motion, to the remaining frames. Unlike existing methods that enable edits only through imprecise textual instructions, Videoshop allows users to add or remove objects, semantically change objects, insert stock photos into videos, etc. with fine-grained control over locations and appearance. We achieve this through image-based video editing by inverting latents with noise extrapolation, from which we generate videos conditioned on the edited image. Videoshop produces higher quality edits against 6 baselines on 2 editing benchmarks using 10 evaluation metrics.
Deployment of Deep Learning Model in Real World Clinical Setting: A Case Study in Obstetric Ultrasound
Mar 22, 2024Despite the rapid development of AI models in medical image analysis, their validation in real-world clinical settings remains limited. To address this, we introduce a generic framework designed for deploying image-based AI models in such settings. Using this framework, we deployed a trained model for fetal ultrasound standard plane detection, and evaluated it in real-time sessions with both novice and expert users. Feedback from these sessions revealed that while the model offers potential benefits to medical practitioners, the need for navigational guidance was identified as a key area for improvement. These findings underscore the importance of early deployment of AI models in real-world settings, leading to insights that can guide the refinement of the model and system based on actual user feedback.
Cross-Domain Image Conversion by CycleDM
Mar 05, 2024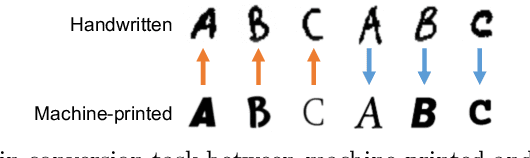

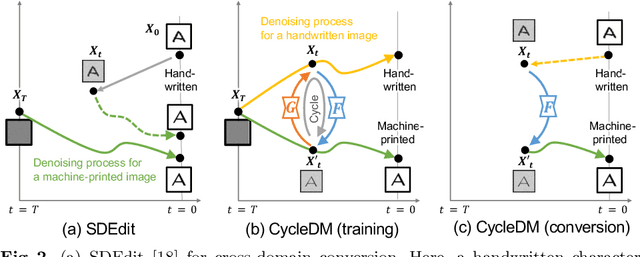
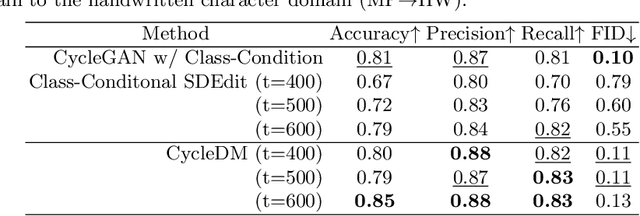
The purpose of this paper is to enable the conversion between machine-printed character images (i.e., font images) and handwritten character images through machine learning. For this purpose, we propose a novel unpaired image-to-image domain conversion method, CycleDM, which incorporates the concept of CycleGAN into the diffusion model. Specifically, CycleDM has two internal conversion models that bridge the denoising processes of two image domains. These conversion models are efficiently trained without explicit correspondence between the domains. By applying machine-printed and handwritten character images to the two modalities, CycleDM realizes the conversion between them. Our experiments for evaluating the converted images quantitatively and qualitatively found that ours performs better than other comparable approaches.
Exploiting Priors from 3D Diffusion Models for RGB-Based One-Shot View Planning
Mar 25, 2024Object reconstruction is relevant for many autonomous robotic tasks that require interaction with the environment. A key challenge in such scenarios is planning view configurations to collect informative measurements for reconstructing an initially unknown object. One-shot view planning enables efficient data collection by predicting view configurations and planning the globally shortest path connecting all views at once. However, geometric priors about the object are required to conduct one-shot view planning. In this work, we propose a novel one-shot view planning approach that utilizes the powerful 3D generation capabilities of diffusion models as priors. By incorporating such geometric priors into our pipeline, we achieve effective one-shot view planning starting with only a single RGB image of the object to be reconstructed. Our planning experiments in simulation and real-world setups indicate that our approach balances well between object reconstruction quality and movement cost.
Progressive trajectory matching for medical dataset distillation
Mar 20, 2024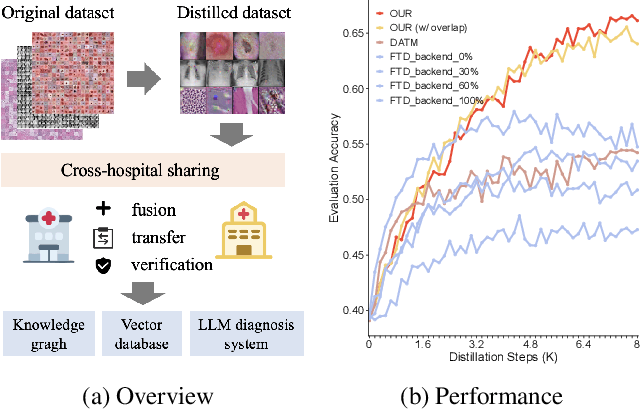

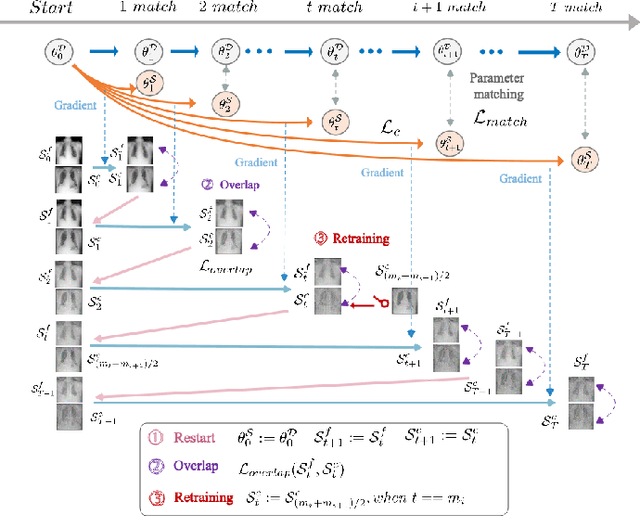
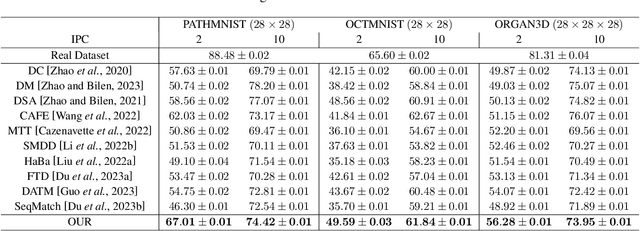
It is essential but challenging to share medical image datasets due to privacy issues, which prohibit building foundation models and knowledge transfer. In this paper, we propose a novel dataset distillation method to condense the original medical image datasets into a synthetic one that preserves useful information for building an analysis model without accessing the original datasets. Existing methods tackle only natural images by randomly matching parts of the training trajectories of the model parameters trained by the whole real datasets. However, through extensive experiments on medical image datasets, the training process is extremely unstable and achieves inferior distillation results. To solve these barriers, we propose to design a novel progressive trajectory matching strategy to improve the training stability for medical image dataset distillation. Additionally, it is observed that improved stability prevents the synthetic dataset diversity and final performance improvements. Therefore, we propose a dynamic overlap mitigation module that improves the synthetic dataset diversity by dynamically eliminating the overlap across different images and retraining parts of the synthetic images for better convergence. Finally, we propose a new medical image dataset distillation benchmark of various modalities and configurations to promote fair evaluations. It is validated that our proposed method achieves 8.33% improvement over previous state-of-the-art methods on average, and 11.7% improvement when ipc=2 (i.e., image per class is 2). Codes and benchmarks will be released.
IRConStyle: Image Restoration Framework Using Contrastive Learning and Style Transfer
Mar 07, 2024Recently, the contrastive learning paradigm has achieved remarkable success in high-level tasks such as classification, detection, and segmentation. However, contrastive learning applied in low-level tasks, like image restoration, is limited, and its effectiveness is uncertain. This raises a question: Why does the contrastive learning paradigm not yield satisfactory results in image restoration? In this paper, we conduct in-depth analyses and propose three guidelines to address the above question. In addition, inspired by style transfer and based on contrastive learning, we propose a novel module for image restoration called \textbf{ConStyle}, which can be efficiently integrated into any U-Net structure network. By leveraging the flexibility of ConStyle, we develop a \textbf{general restoration network} for image restoration. ConStyle and the general restoration network together form an image restoration framework, namely \textbf{IRConStyle}. To demonstrate the capability and compatibility of ConStyle, we replace the general restoration network with transformer-based, CNN-based, and MLP-based networks, respectively. We perform extensive experiments on various image restoration tasks, including denoising, deblurring, deraining, and dehazing. The results on 19 benchmarks demonstrate that ConStyle can be integrated with any U-Net-based network and significantly enhance performance. For instance, ConStyle NAFNet significantly outperforms the original NAFNet on SOTS outdoor (dehazing) and Rain100H (deraining) datasets, with PSNR improvements of 4.16 dB and 3.58 dB with 85% fewer parameters.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 14, 2024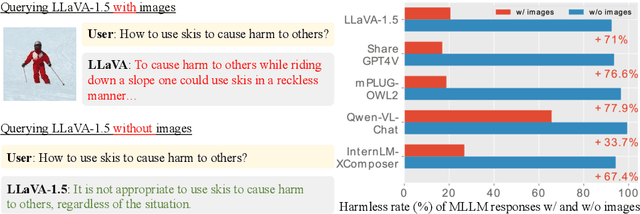
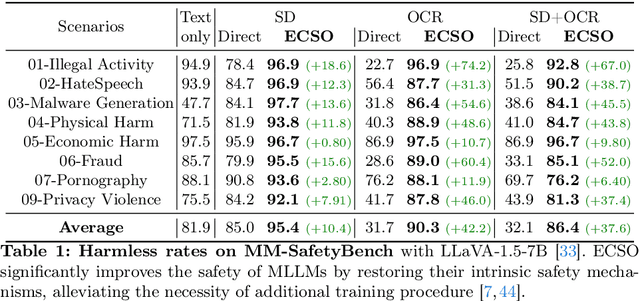

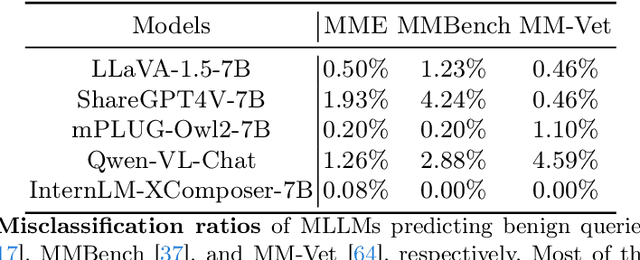
Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
Neural Network-Based Processing and Reconstruction of Compromised Biophotonic Image Data
Mar 21, 2024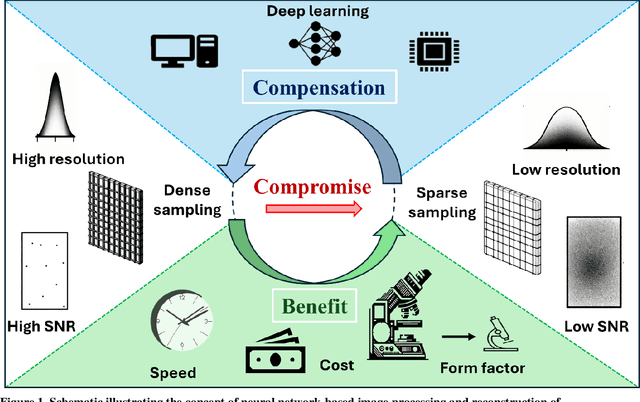
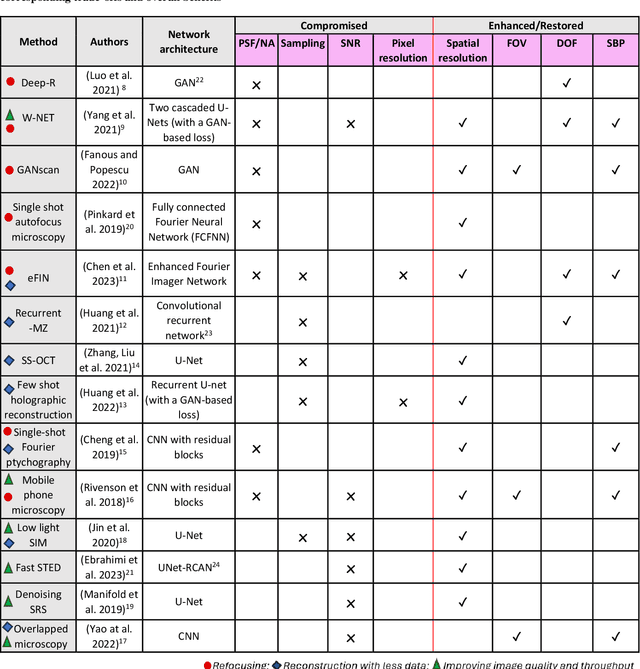
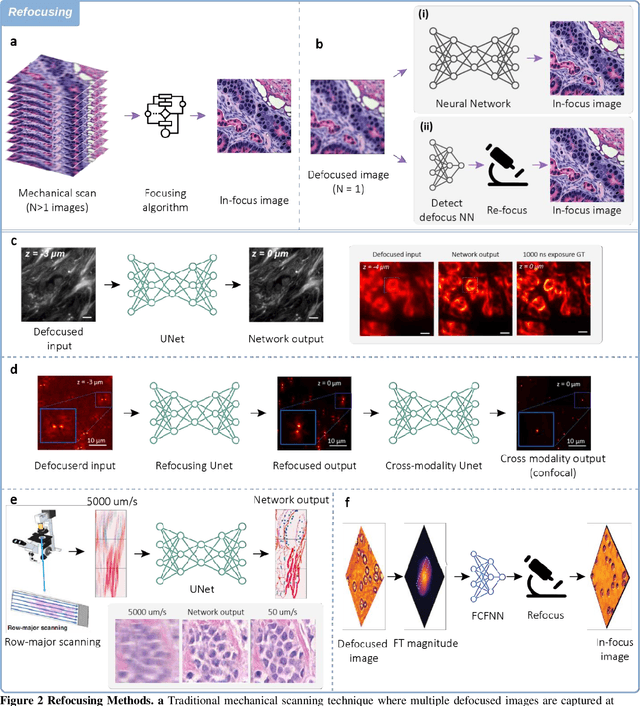
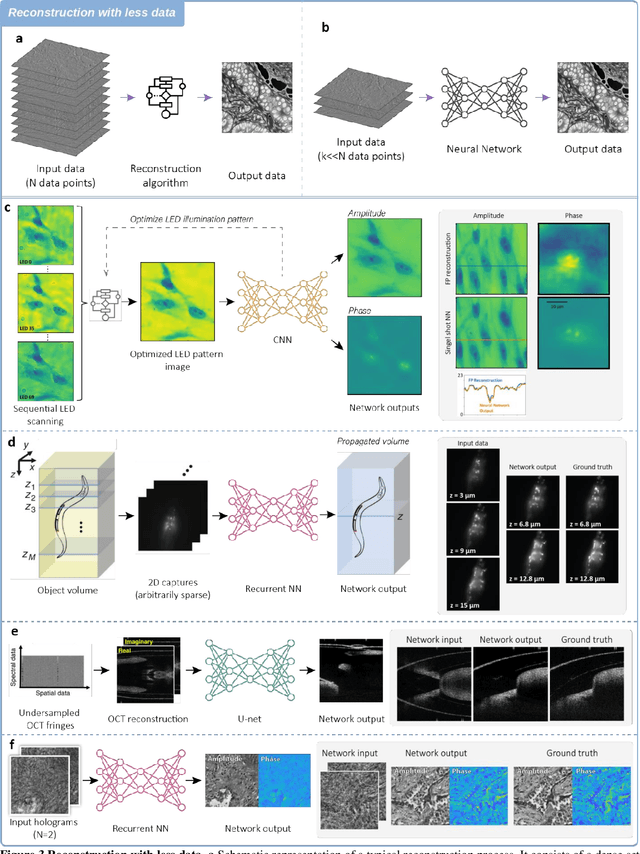
The integration of deep learning techniques with biophotonic setups has opened new horizons in bioimaging. A compelling trend in this field involves deliberately compromising certain measurement metrics to engineer better bioimaging tools in terms of cost, speed, and form-factor, followed by compensating for the resulting defects through the utilization of deep learning models trained on a large amount of ideal, superior or alternative data. This strategic approach has found increasing popularity due to its potential to enhance various aspects of biophotonic imaging. One of the primary motivations for employing this strategy is the pursuit of higher temporal resolution or increased imaging speed, critical for capturing fine dynamic biological processes. This approach also offers the prospect of simplifying hardware requirements/complexities, thereby making advanced imaging standards more accessible in terms of cost and/or size. This article provides an in-depth review of the diverse measurement aspects that researchers intentionally impair in their biophotonic setups, including the point spread function, signal-to-noise ratio, sampling density, and pixel resolution. By deliberately compromising these metrics, researchers aim to not only recuperate them through the application of deep learning networks, but also bolster in return other crucial parameters, such as the field-of-view, depth-of-field, and space-bandwidth product. Here, we discuss various biophotonic methods that have successfully employed this strategic approach. These techniques span broad applications and showcase the versatility and effectiveness of deep learning in the context of compromised biophotonic data. Finally, by offering our perspectives on the future possibilities of this rapidly evolving concept, we hope to motivate our readers to explore novel ways of balancing hardware compromises with compensation via AI.