 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Segmentation Guided Sparse Transformer for Under-Display Camera Image Restoration
Mar 09, 2024


Under-Display Camera (UDC) is an emerging technology that achieves full-screen display via hiding the camera under the display panel. However, the current implementation of UDC causes serious degradation. The incident light required for camera imaging undergoes attenuation and diffraction when passing through the display panel, leading to various artifacts in UDC imaging. Presently, the prevailing UDC image restoration methods predominantly utilize convolutional neural network architectures, whereas Transformer-based methods have exhibited superior performance in the majority of image restoration tasks. This is attributed to the Transformer's capability to sample global features for the local reconstruction of images, thereby achieving high-quality image restoration. In this paper, we observe that when using the Vision Transformer for UDC degraded image restoration, the global attention samples a large amount of redundant information and noise. Furthermore, compared to the ordinary Transformer employing dense attention, the Transformer utilizing sparse attention can alleviate the adverse impact of redundant information and noise. Building upon this discovery, we propose a Segmentation Guided Sparse Transformer method (SGSFormer) for the task of restoring high-quality images from UDC degraded images. Specifically, we utilize sparse self-attention to filter out redundant information and noise, directing the model's attention to focus on the features more relevant to the degraded regions in need of reconstruction. Moreover, we integrate the instance segmentation map as prior information to guide the sparse self-attention in filtering and focusing on the correct regions.
Feature Manipulation for DDPM based Change Detection
Mar 23, 2024Change Detection is a classic task of computer vision that receives a bi-temporal image pair as input and separates the semantically changed and unchanged regions of it. The diffusion model is used in image synthesis and as a feature extractor and has been applied to various downstream tasks. Using this, a feature map is extracted from the pre-trained diffusion model from the large-scale data set, and changes are detected through the additional network. On the one hand, the current diffusion-based change detection approach focuses only on extracting a good feature map using the diffusion model. It obtains and uses differences without further adjustment to the created feature map. Our method focuses on manipulating the feature map extracted from the Diffusion Model to be more semantically useful, and for this, we propose two methods: Feature Attention and FDAF. Our model with Feature Attention achieved a state-of-the-art F1 score (90.18) and IoU (83.86) on the LEVIR-CD dataset.
Inpainting-Driven Mask Optimization for Object Removal
Mar 23, 2024This paper proposes a mask optimization method for improving the quality of object removal using image inpainting. While many inpainting methods are trained with a set of random masks, a target for inpainting may be an object, such as a person, in many realistic scenarios. This domain gap between masks in training and inference images increases the difficulty of the inpainting task. In our method, this domain gap is resolved by training the inpainting network with object masks extracted by segmentation, and such object masks are also used in the inference step. Furthermore, to optimize the object masks for inpainting, the segmentation network is connected to the inpainting network and end-to-end trained to improve the inpainting performance. The effect of this end-to-end training is further enhanced by our mask expansion loss for achieving the trade-off between large and small masks. Experimental results demonstrate the effectiveness of our method for better object removal using image inpainting.
Cross-Modal and Uni-Modal Soft-Label Alignment for Image-Text Retrieval
Mar 08, 2024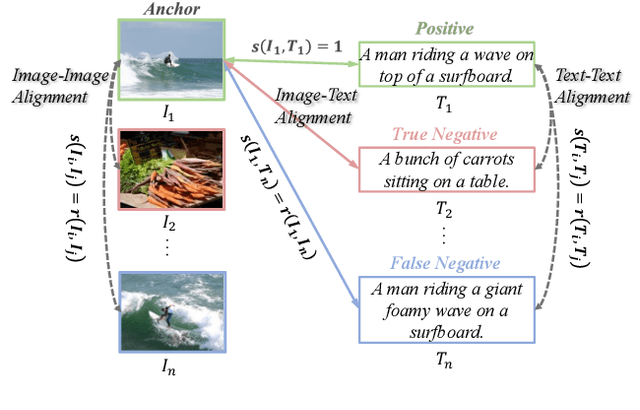
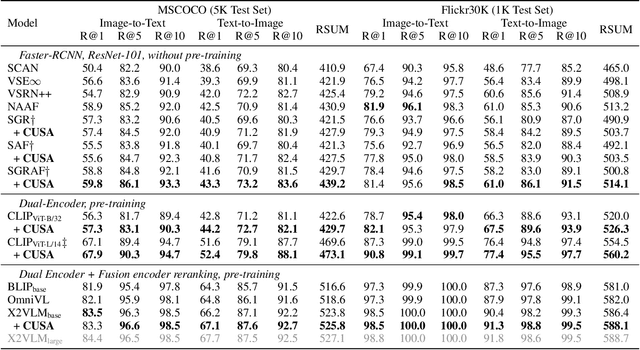
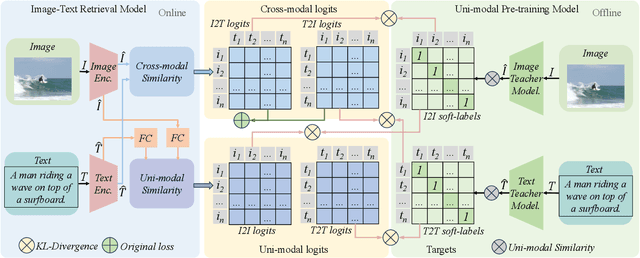
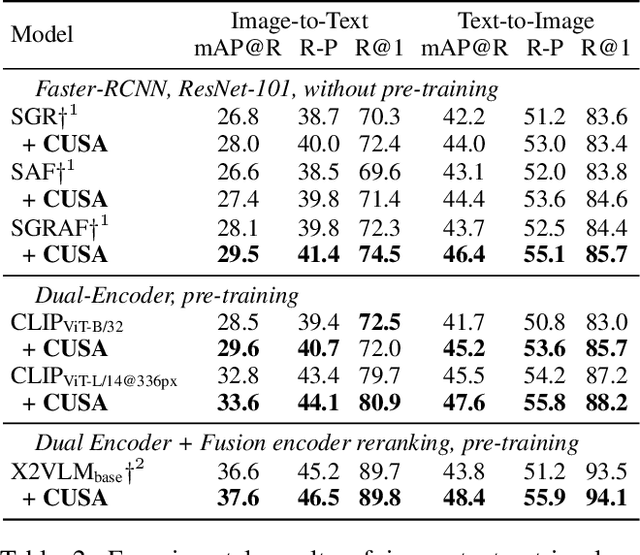
Current image-text retrieval methods have demonstrated impressive performance in recent years. However, they still face two problems: the inter-modal matching missing problem and the intra-modal semantic loss problem. These problems can significantly affect the accuracy of image-text retrieval. To address these challenges, we propose a novel method called Cross-modal and Uni-modal Soft-label Alignment (CUSA). Our method leverages the power of uni-modal pre-trained models to provide soft-label supervision signals for the image-text retrieval model. Additionally, we introduce two alignment techniques, Cross-modal Soft-label Alignment (CSA) and Uni-modal Soft-label Alignment (USA), to overcome false negatives and enhance similarity recognition between uni-modal samples. Our method is designed to be plug-and-play, meaning it can be easily applied to existing image-text retrieval models without changing their original architectures. Extensive experiments on various image-text retrieval models and datasets, we demonstrate that our method can consistently improve the performance of image-text retrieval and achieve new state-of-the-art results. Furthermore, our method can also boost the uni-modal retrieval performance of image-text retrieval models, enabling it to achieve universal retrieval. The code and supplementary files can be found at https://github.com/lerogo/aaai24_itr_cusa.
Universal Debiased Editing for Fair Medical Image Classification
Mar 10, 2024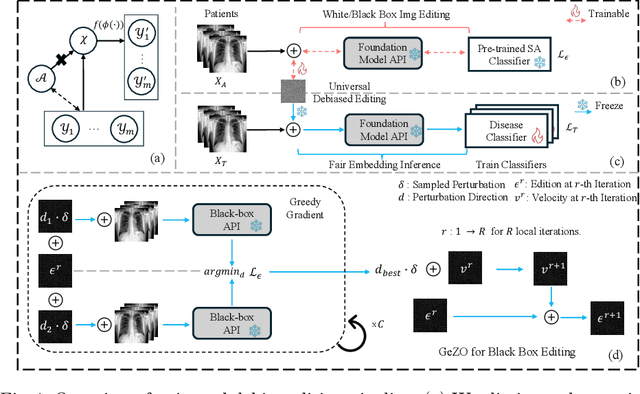
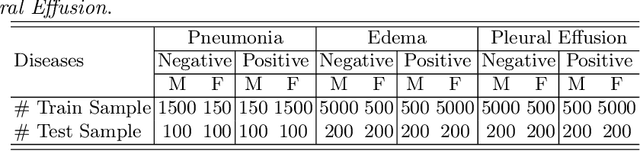
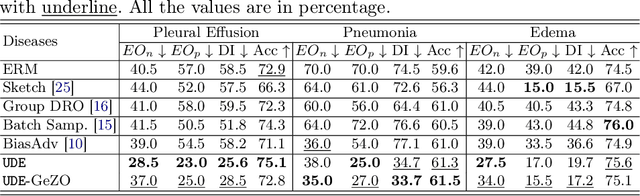
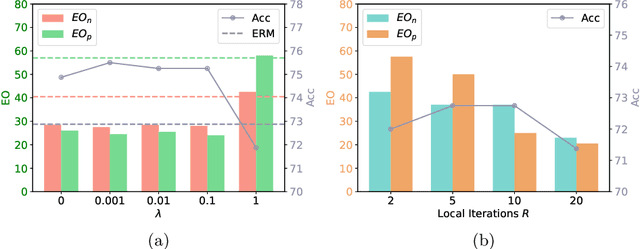
In the era of Foundation Models' (FMs) rising prominence in AI, our study addresses the challenge of biases in medical images while using FM API, particularly spurious correlations between pixels and sensitive attributes. Traditional methods for bias mitigation face limitations due to the restricted access to web-hosted FMs and difficulties in addressing the underlying bias encoded within the FM API. We propose an U(niversal) D(ebiased) E(diting) strategy, termed UDE, which generates UDE noise to mask such spurious correlation. UDE is capable of mitigating bias both within the FM API embedding and the images themselves. Furthermore, UDE is suitable for both white-box and black-box FM APIs, where we introduced G(reedy) (Z)eroth-O(rder) (GeZO) optimization for it when the gradient is inaccessible in black-box APIs. Our whole pipeline enables fairness-aware image editing that can be applied across various medical contexts without requiring direct model manipulation or significant computational resources. Our empirical results demonstrate the method's effectiveness in maintaining fairness and utility across different patient groups and diseases. In the era of AI-driven medicine, this work contributes to making healthcare diagnostics more equitable, showcasing a practical solution for bias mitigation in pre-trained image FMs.
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Mar 21, 2024
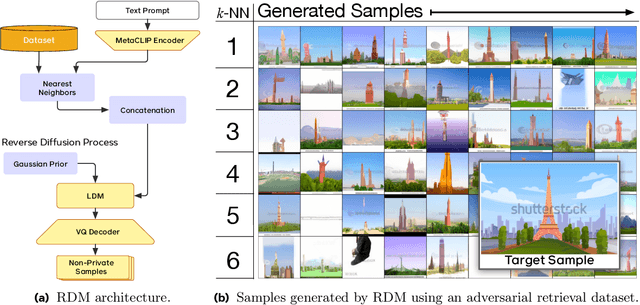
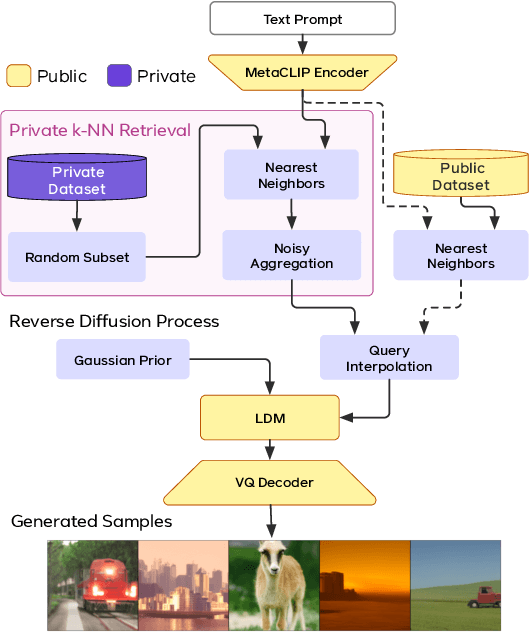

Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
Discriminative Probing and Tuning for Text-to-Image Generation
Mar 07, 2024
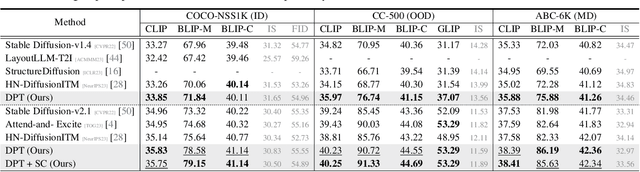
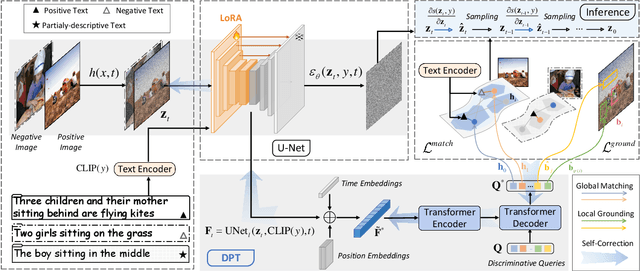
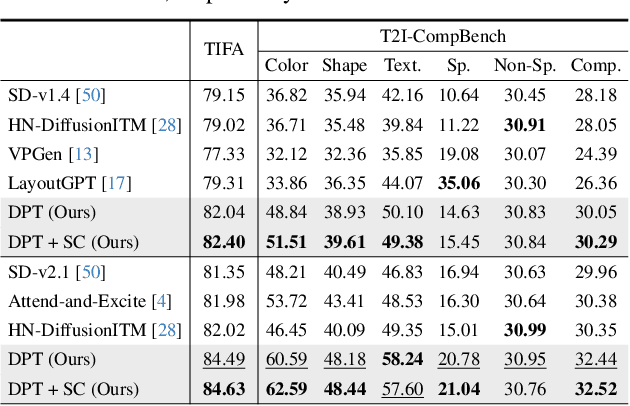
Despite advancements in text-to-image generation (T2I), prior methods often face text-image misalignment problems such as relation confusion in generated images. Existing solutions involve cross-attention manipulation for better compositional understanding or integrating large language models for improved layout planning. However, the inherent alignment capabilities of T2I models are still inadequate. By reviewing the link between generative and discriminative modeling, we posit that T2I models' discriminative abilities may reflect their text-image alignment proficiency during generation. In this light, we advocate bolstering the discriminative abilities of T2I models to achieve more precise text-to-image alignment for generation. We present a discriminative adapter built on T2I models to probe their discriminative abilities on two representative tasks and leverage discriminative fine-tuning to improve their text-image alignment. As a bonus of the discriminative adapter, a self-correction mechanism can leverage discriminative gradients to better align generated images to text prompts during inference. Comprehensive evaluations across three benchmark datasets, including both in-distribution and out-of-distribution scenarios, demonstrate our method's superior generation performance. Meanwhile, it achieves state-of-the-art discriminative performance on the two discriminative tasks compared to other generative models.
DreamFlow: High-Quality Text-to-3D Generation by Approximating Probability Flow
Mar 22, 2024Recent progress in text-to-3D generation has been achieved through the utilization of score distillation methods: they make use of the pre-trained text-to-image (T2I) diffusion models by distilling via the diffusion model training objective. However, such an approach inevitably results in the use of random timesteps at each update, which increases the variance of the gradient and ultimately prolongs the optimization process. In this paper, we propose to enhance the text-to-3D optimization by leveraging the T2I diffusion prior in the generative sampling process with a predetermined timestep schedule. To this end, we interpret text-to3D optimization as a multi-view image-to-image translation problem, and propose a solution by approximating the probability flow. By leveraging the proposed novel optimization algorithm, we design DreamFlow, a practical three-stage coarseto-fine text-to-3D optimization framework that enables fast generation of highquality and high-resolution (i.e., 1024x1024) 3D contents. For example, we demonstrate that DreamFlow is 5 times faster than the existing state-of-the-art text-to-3D method, while producing more photorealistic 3D contents. Visit our project page (https://kyungmnlee.github.io/dreamflow.github.io/) for visualizations.
Holo-Relighting: Controllable Volumetric Portrait Relighting from a Single Image
Mar 14, 2024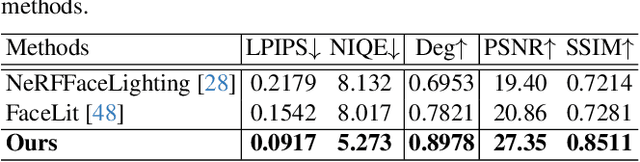
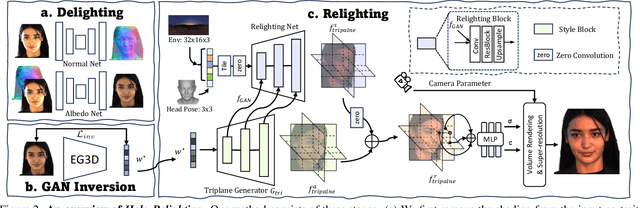
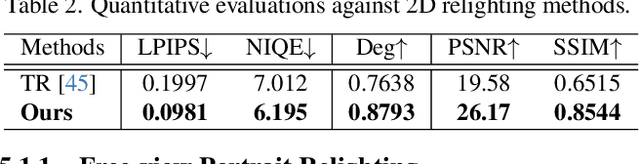
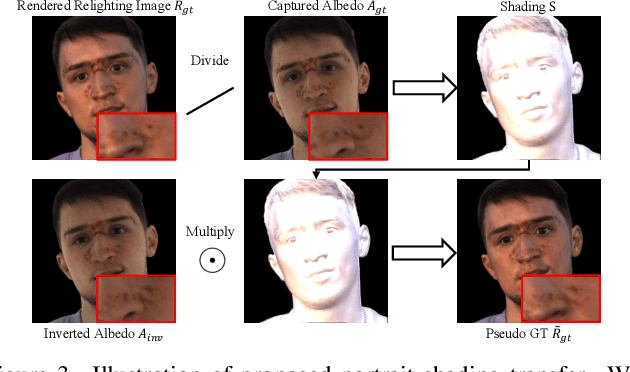
At the core of portrait photography is the search for ideal lighting and viewpoint. The process often requires advanced knowledge in photography and an elaborate studio setup. In this work, we propose Holo-Relighting, a volumetric relighting method that is capable of synthesizing novel viewpoints, and novel lighting from a single image. Holo-Relighting leverages the pretrained 3D GAN (EG3D) to reconstruct geometry and appearance from an input portrait as a set of 3D-aware features. We design a relighting module conditioned on a given lighting to process these features, and predict a relit 3D representation in the form of a tri-plane, which can render to an arbitrary viewpoint through volume rendering. Besides viewpoint and lighting control, Holo-Relighting also takes the head pose as a condition to enable head-pose-dependent lighting effects. With these novel designs, Holo-Relighting can generate complex non-Lambertian lighting effects (e.g., specular highlights and cast shadows) without using any explicit physical lighting priors. We train Holo-Relighting with data captured with a light stage, and propose two data-rendering techniques to improve the data quality for training the volumetric relighting system. Through quantitative and qualitative experiments, we demonstrate Holo-Relighting can achieve state-of-the-arts relighting quality with better photorealism, 3D consistency and controllability.
Grad-CAMO: Learning Interpretable Single-Cell Morphological Profiles from 3D Cell Painting Images
Mar 26, 2024Despite their black-box nature, deep learning models are extensively used in image-based drug discovery to extract feature vectors from single cells in microscopy images. To better understand how these networks perform representation learning, we employ visual explainability techniques (e.g., Grad-CAM). Our analyses reveal several mechanisms by which supervised models cheat, exploiting biologically irrelevant pixels when extracting morphological features from images, such as noise in the background. This raises doubts regarding the fidelity of learned single-cell representations and their relevance when investigating downstream biological questions. To address this misalignment between researcher expectations and machine behavior, we introduce Grad-CAMO, a novel single-cell interpretability score for supervised feature extractors. Grad-CAMO measures the proportion of a model's attention that is concentrated on the cell of interest versus the background. This metric can be assessed per-cell or averaged across a validation set, offering a tool to audit individual features vectors or guide the improved design of deep learning architectures. Importantly, Grad-CAMO seamlessly integrates into existing workflows, requiring no dataset or model modifications, and is compatible with both 2D and 3D Cell Painting data. Additional results are available at https://github.com/eigenvivek/Grad-CAMO.