 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
May 25, 2026Multi-view 3D reconstruction has achieved remarkable progress with the advent of feed-forward 3D reconstruction models. However, these models are typically trained and evaluated under ideal, degradation-free imaging conditions, whereas real-world observations often contain degradations that differ significantly from such settings. Improving robustness for multi-view 3D reconstruction under degraded conditions therefore remains an important challenge. We present Geometry-Aware Representation Denoising (GARD), a novel framework that performs diffusion-based multi-view restoration directly in the feature space of a feed-forward 3D reconstruction model. This design exploits the geometry-aware feature representations of the 3D reconstructor to effectively recover accurate scene geometry. Furthermore, by employing an additional RGB image decoder, the refined representations can also be used to restore high-quality RGB images, thereby enabling the simultaneous recovery of 3D scene geometry and high-quality imagery. Comprehensive experiments on the Depth Anything 3 (DA3) benchmark demonstrate the effectiveness of the proposed GARD framework.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
PerTouch: VLM-Driven Agent for Personalized and Semantic Image Retouching
Nov 17, 2025Image retouching aims to enhance visual quality while aligning with users' personalized aesthetic preferences. To address the challenge of balancing controllability and subjectivity, we propose a unified diffusion-based image retouching framework called PerTouch. Our method supports semantic-level image retouching while maintaining global aesthetics. Using parameter maps containing attribute values in specific semantic regions as input, PerTouch constructs an explicit parameter-to-image mapping for fine-grained image retouching. To improve semantic boundary perception, we introduce semantic replacement and parameter perturbation mechanisms in the training process. To connect natural language instructions with visual control, we develop a VLM-driven agent that can handle both strong and weak user instructions. Equipped with mechanisms of feedback-driven rethinking and scene-aware memory, PerTouch better aligns with user intent and captures long-term preferences. Extensive experiments demonstrate each component's effectiveness and the superior performance of PerTouch in personalized image retouching. Code is available at: https://github.com/Auroral703/PerTouch.
Text-Aware Image Restoration with Diffusion Models
Jun 11, 2025

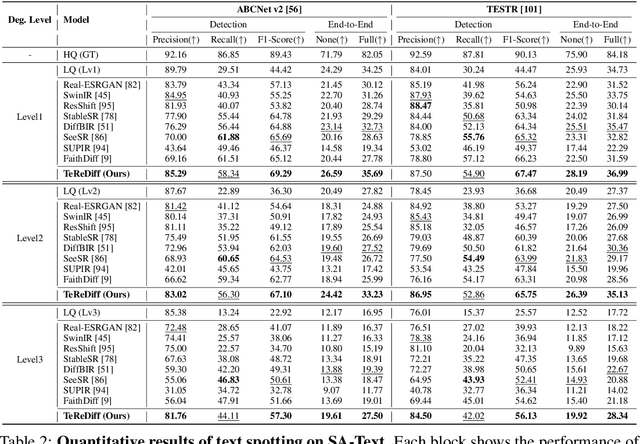

Image restoration aims to recover degraded images. However, existing diffusion-based restoration methods, despite great success in natural image restoration, often struggle to faithfully reconstruct textual regions in degraded images. Those methods frequently generate plausible but incorrect text-like patterns, a phenomenon we refer to as text-image hallucination. In this paper, we introduce Text-Aware Image Restoration (TAIR), a novel restoration task that requires the simultaneous recovery of visual contents and textual fidelity. To tackle this task, we present SA-Text, a large-scale benchmark of 100K high-quality scene images densely annotated with diverse and complex text instances. Furthermore, we propose a multi-task diffusion framework, called TeReDiff, that integrates internal features from diffusion models into a text-spotting module, enabling both components to benefit from joint training. This allows for the extraction of rich text representations, which are utilized as prompts in subsequent denoising steps. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art restoration methods, achieving significant gains in text recognition accuracy. See our project page: https://cvlab-kaist.github.io/TAIR/
NTIRE 2025 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results
May 17, 2025



This paper reviews the NTIRE 2025 Efficient Burst HDR and Restoration Challenge, which aims to advance efficient multi-frame high dynamic range (HDR) and restoration techniques. The challenge is based on a novel RAW multi-frame fusion dataset, comprising nine noisy and misaligned RAW frames with various exposure levels per scene. Participants were tasked with developing solutions capable of effectively fusing these frames while adhering to strict efficiency constraints: fewer than 30 million model parameters and a computational budget under 4.0 trillion FLOPs. A total of 217 participants registered, with six teams finally submitting valid solutions. The top-performing approach achieved a PSNR of 43.22 dB, showcasing the potential of novel methods in this domain. This paper provides a comprehensive overview of the challenge, compares the proposed solutions, and serves as a valuable reference for researchers and practitioners in efficient burst HDR and restoration.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
Iterative Predictor-Critic Code Decoding for Real-World Image Dehazing
Mar 17, 2025



We propose a novel Iterative Predictor-Critic Code Decoding framework for real-world image dehazing, abbreviated as IPC-Dehaze, which leverages the high-quality codebook prior encapsulated in a pre-trained VQGAN. Apart from previous codebook-based methods that rely on one-shot decoding, our method utilizes high-quality codes obtained in the previous iteration to guide the prediction of the Code-Predictor in the subsequent iteration, improving code prediction accuracy and ensuring stable dehazing performance. Our idea stems from the observations that 1) the degradation of hazy images varies with haze density and scene depth, and 2) clear regions play crucial cues in restoring dense haze regions. However, it is non-trivial to progressively refine the obtained codes in subsequent iterations, owing to the difficulty in determining which codes should be retained or replaced at each iteration. Another key insight of our study is to propose Code-Critic to capture interrelations among codes. The Code-Critic is used to evaluate code correlations and then resample a set of codes with the highest mask scores, i.e., a higher score indicates that the code is more likely to be rejected, which helps retain more accurate codes and predict difficult ones. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods in real-world dehazing.
FaceMe: Robust Blind Face Restoration with Personal Identification
Jan 10, 2025



Blind face restoration is a highly ill-posed problem due to the lack of necessary context. Although existing methods produce high-quality outputs, they often fail to faithfully preserve the individual's identity. In this paper, we propose a personalized face restoration method, FaceMe, based on a diffusion model. Given a single or a few reference images, we use an identity encoder to extract identity-related features, which serve as prompts to guide the diffusion model in restoring high-quality and identity-consistent facial images. By simply combining identity-related features, we effectively minimize the impact of identity-irrelevant features during training and support any number of reference image inputs during inference. Additionally, thanks to the robustness of the identity encoder, synthesized images can be used as reference images during training, and identity changing during inference does not require fine-tuning the model. We also propose a pipeline for constructing a reference image training pool that simulates the poses and expressions that may appear in real-world scenarios. Experimental results demonstrate that our FaceMe can restore high-quality facial images while maintaining identity consistency, achieving excellent performance and robustness.