 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Mar 17, 2026We present V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding. The approach combines four key components. First, a dense predictive loss uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding. Second, deep self-supervision applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality. Third, multi-modal tokenizers enable unified training across images and videos. Finally, the model benefits from effective scaling in both model capacity and training data. Together, these design choices produce representations that are spatially structured, semantically coherent, and temporally consistent. Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks, including 7.71 mAP on Ego4D for short-term object-interaction anticipation and 40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation, as well as a 20-point improvement in real-robot grasping success rate over V-JEPA-2 AC. The model also demonstrates strong performance in robotic navigation (5.687 ATE on TartanDrive), depth estimation (0.307 RMSE on NYUv2 with a linear probe), and global recognition (77.7 on Something-Something-V2). These results show that V-JEPA 2.1 significantly advances the state of the art in dense visual understanding and world modeling.
Interpreting Physics in Video World Models
Feb 04, 2026A long-standing question in physical reasoning is whether video-based models need to rely on factorized representations of physical variables in order to make physically accurate predictions, or whether they can implicitly represent such variables in a task-specific, distributed manner. While modern video world models achieve strong performance on intuitive physics benchmarks, it remains unclear which of these representational regimes they implement internally. Here, we present the first interpretability study to directly examine physical representations inside large-scale video encoders. Using layerwise probing, subspace geometry, patch-level decoding, and targeted attention ablations, we characterize where physical information becomes accessible and how it is organized within encoder-based video transformers. Across architectures, we identify a sharp intermediate-depth transition -- which we call the Physics Emergence Zone -- at which physical variables become accessible. Physics-related representations peak shortly after this transition and degrade toward the output layers. Decomposing motion into explicit variables, we find that scalar quantities such as speed and acceleration are available from early layers onwards, whereas motion direction becomes accessible only at the Physics Emergence Zone. Notably, we find that direction is encoded through a high-dimensional population structure with circular geometry, requiring coordinated multi-feature intervention to control. These findings suggest that modern video models do not use factorized representations of physical variables like a classical physics engine. Instead, they use a distributed representation that is nonetheless sufficient for making physical predictions.
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
Feb 03, 2026We present EB-JEPA, an open-source library for learning representations and world models using Joint-Embedding Predictive Architectures (JEPAs). JEPAs learn to predict in representation space rather than pixel space, avoiding the pitfalls of generative modeling while capturing semantically meaningful features suitable for downstream tasks. Our library provides modular, self-contained implementations that illustrate how representation learning techniques developed for image-level self-supervised learning can transfer to video, where temporal dynamics add complexity, and ultimately to action-conditioned world models, where the model must additionally learn to predict the effects of control inputs. Each example is designed for single-GPU training within a few hours, making energy-based self-supervised learning accessible for research and education. We provide ablations of JEA components on CIFAR-10. Probing these representations yields 91% accuracy, indicating that the model learns useful features. Extending to video, we include a multi-step prediction example on Moving MNIST that demonstrates how the same principles scale to temporal modeling. Finally, we show how these representations can drive action-conditioned world models, achieving a 97% planning success rate on the Two Rooms navigation task. Comprehensive ablations reveal the critical importance of each regularization component for preventing representation collapse. Code is available at https://github.com/facebookresearch/eb_jepa.
EvalGIM: A Library for Evaluating Generative Image Models
Dec 18, 2024



As the use of text-to-image generative models increases, so does the adoption of automatic benchmarking methods used in their evaluation. However, while metrics and datasets abound, there are few unified benchmarking libraries that provide a framework for performing evaluations across many datasets and metrics. Furthermore, the rapid introduction of increasingly robust benchmarking methods requires that evaluation libraries remain flexible to new datasets and metrics. Finally, there remains a gap in synthesizing evaluations in order to deliver actionable takeaways about model performance. To enable unified, flexible, and actionable evaluations, we introduce EvalGIM (pronounced ''EvalGym''), a library for evaluating generative image models. EvalGIM contains broad support for datasets and metrics used to measure quality, diversity, and consistency of text-to-image generative models. In addition, EvalGIM is designed with flexibility for user customization as a top priority and contains a structure that allows plug-and-play additions of new datasets and metrics. To enable actionable evaluation insights, we introduce ''Evaluation Exercises'' that highlight takeaways for specific evaluation questions. The Evaluation Exercises contain easy-to-use and reproducible implementations of two state-of-the-art evaluation methods of text-to-image generative models: consistency-diversity-realism Pareto Fronts and disaggregated measurements of performance disparities across groups. EvalGIM also contains Evaluation Exercises that introduce two new analysis methods for text-to-image generative models: robustness analyses of model rankings and balanced evaluations across different prompt styles. We encourage text-to-image model exploration with EvalGIM and invite contributions at https://github.com/facebookresearch/EvalGIM/.
Transformers Can Navigate Mazes With Multi-Step Prediction
Dec 06, 2024



Despite their remarkable success in language modeling, transformers trained to predict the next token in a sequence struggle with long-term planning. This limitation is particularly evident in tasks requiring foresight to plan multiple steps ahead such as maze navigation. The standard next single token prediction objective, however, offers no explicit mechanism to predict multiple steps ahead - or revisit the path taken so far. Consequently, in this work we study whether explicitly predicting multiple steps ahead (and backwards) can improve transformers' maze navigation. We train parameter-matched transformers from scratch, under identical settings, to navigate mazes of varying types and sizes with standard next token prediction and MLM-U, an objective explicitly predicting multiple steps ahead and backwards. We find that MLM-U considerably improves transformers' ability to navigate mazes compared to standard next token prediction across maze types and complexities. We also find MLM-U training is 4x more sample efficient and converges 2x faster in terms of GPU training hours relative to next token training. Finally, for more complex mazes we find MLM-U benefits from scaling to larger transformers. Remarkably, we find transformers trained with MLM-U outperform larger transformers trained with next token prediction using additional supervision from A* search traces. We hope these findings underscore the promise of learning objectives to advance transformers' capacity for long-term planning.
The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More
Jun 07, 2024



Today's best language models still struggle with hallucinations: factually incorrect generations, which impede their ability to reliably retrieve information seen during training. The reversal curse, where models cannot recall information when probed in a different order than was encountered during training, exemplifies this in information retrieval. We reframe the reversal curse as a factorization curse - a failure of models to learn the same joint distribution under different factorizations. Through a series of controlled experiments with increasing levels of realism including WikiReversal, a setting we introduce to closely simulate a knowledge intensive finetuning task, we find that the factorization curse is an inherent failure of the next-token prediction objective used in popular large language models. Moreover, we demonstrate reliable information retrieval cannot be solved with scale, reversed tokens, or even naive bidirectional-attention training. Consequently, various approaches to finetuning on specialized data would necessarily provide mixed results on downstream tasks, unless the model has already seen the right sequence of tokens. Across five tasks of varying levels of complexity, our results uncover a promising path forward: factorization-agnostic objectives can significantly mitigate the reversal curse and hint at improved knowledge storage and planning capabilities.
DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Mar 21, 2024



Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
The Interpolated MVU Mechanism For Communication-efficient Private Federated Learning
Nov 08, 2022



We consider private federated learning (FL), where a server aggregates differentially private gradient updates from a large number of clients in order to train a machine learning model. The main challenge is balancing privacy with both classification accuracy of the learned model as well as the amount of communication between the clients and server. In this work, we build on a recently proposed method for communication-efficient private FL -- the MVU mechanism -- by introducing a new interpolation mechanism that can accommodate a more efficient privacy analysis. The result is the new Interpolated MVU mechanism that provides SOTA results on communication-efficient private FL on a variety of datasets.
Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity
May 30, 2022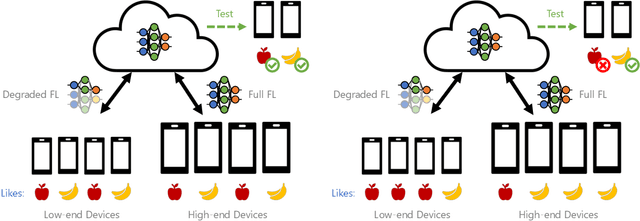
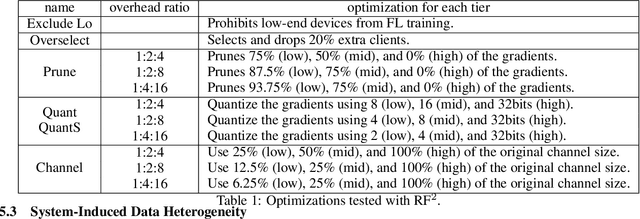
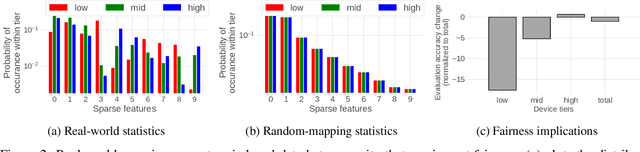
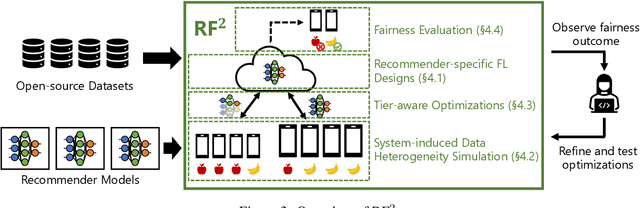
Federated learning (FL) is an effective mechanism for data privacy in recommender systems by running machine learning model training on-device. While prior FL optimizations tackled the data and system heterogeneity challenges faced by FL, they assume the two are independent of each other. This fundamental assumption is not reflective of real-world, large-scale recommender systems -- data and system heterogeneity are tightly intertwined. This paper takes a data-driven approach to show the inter-dependence of data and system heterogeneity in real-world data and quantifies its impact on the overall model quality and fairness. We design a framework, RF^2, to model the inter-dependence and evaluate its impact on state-of-the-art model optimization techniques for federated recommendation tasks. We demonstrate that the impact on fairness can be severe under realistic heterogeneity scenarios, by up to 15.8--41x compared to a simple setup assumed in most (if not all) prior work. It means when realistic system-induced data heterogeneity is not properly modeled, the fairness impact of an optimization can be downplayed by up to 41x. The result shows that modeling realistic system-induced data heterogeneity is essential to achieving fair federated recommendation learning. We plan to open-source RF^2 to enable future design and evaluation of FL innovations.