 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A tailored Handwritten-Text-Recognition System for Medieval Latin
Aug 18, 2023

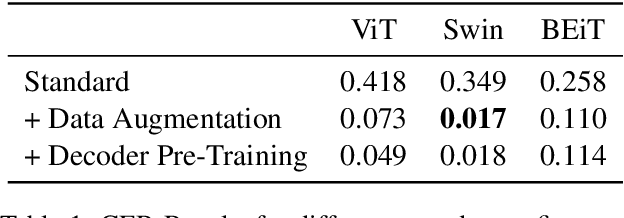

The Bavarian Academy of Sciences and Humanities aims to digitize its Medieval Latin Dictionary. This dictionary entails record cards referring to lemmas in medieval Latin, a low-resource language. A crucial step of the digitization process is the Handwritten Text Recognition (HTR) of the handwritten lemmas found on these record cards. In our work, we introduce an end-to-end pipeline, tailored to the medieval Latin dictionary, for locating, extracting, and transcribing the lemmas. We employ two state-of-the-art (SOTA) image segmentation models to prepare the initial data set for the HTR task. Furthermore, we experiment with different transformer-based models and conduct a set of experiments to explore the capabilities of different combinations of vision encoders with a GPT-2 decoder. Additionally, we also apply extensive data augmentation resulting in a highly competitive model. The best-performing setup achieved a Character Error Rate (CER) of 0.015, which is even superior to the commercial Google Cloud Vision model, and shows more stable performance.
A review of technical factors to consider when designing neural networks for semantic segmentation of Earth Observation imagery
Aug 18, 2023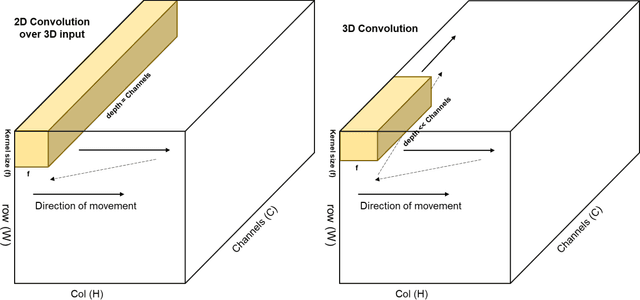
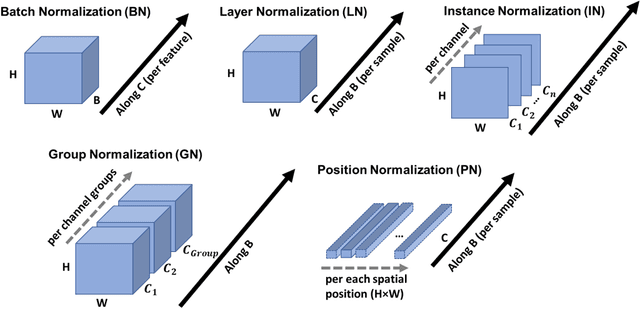
Semantic segmentation (classification) of Earth Observation imagery is a crucial task in remote sensing. This paper presents a comprehensive review of technical factors to consider when designing neural networks for this purpose. The review focuses on Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), Generative Adversarial Networks (GANs), and transformer models, discussing prominent design patterns for these ANN families and their implications for semantic segmentation. Common pre-processing techniques for ensuring optimal data preparation are also covered. These include methods for image normalization and chipping, as well as strategies for addressing data imbalance in training samples, and techniques for overcoming limited data, including augmentation techniques, transfer learning, and domain adaptation. By encompassing both the technical aspects of neural network design and the data-related considerations, this review provides researchers and practitioners with a comprehensive and up-to-date understanding of the factors involved in designing effective neural networks for semantic segmentation of Earth Observation imagery.
Label-noise-tolerant medical image classification via self-attention and self-supervised learning
Jun 16, 2023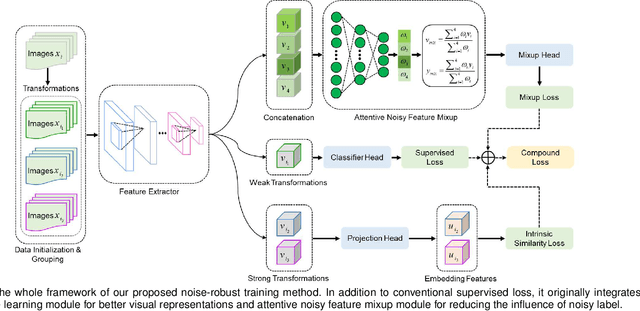
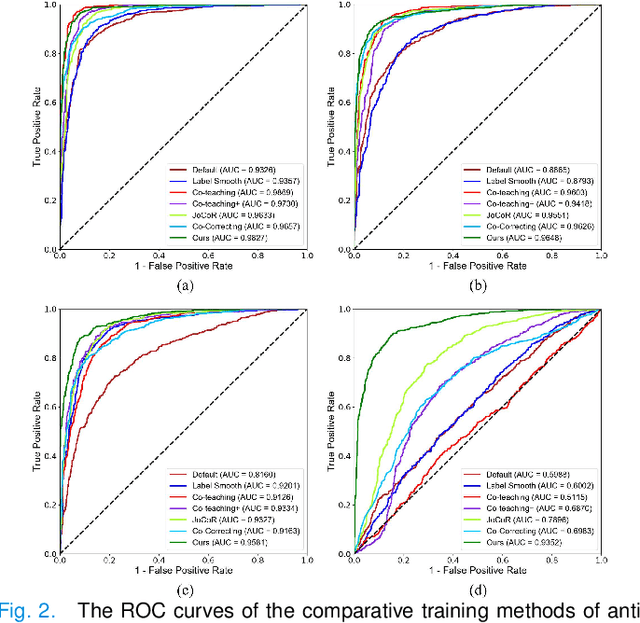
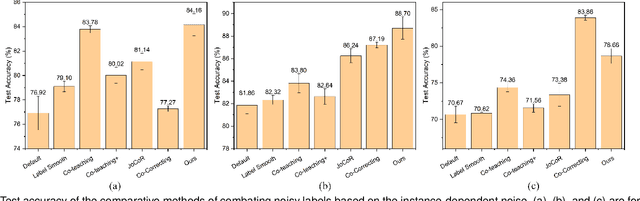
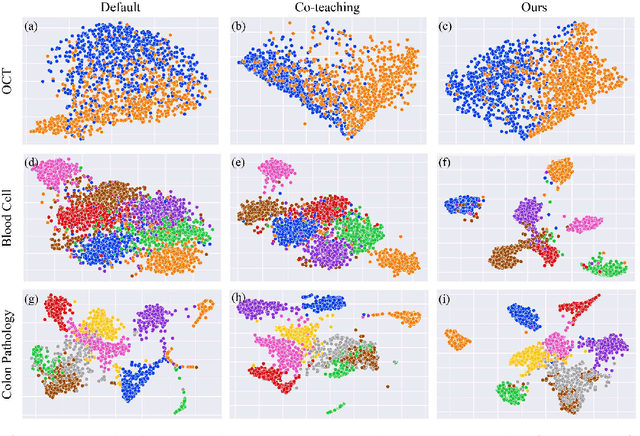
Deep neural networks (DNNs) have been widely applied in medical image classification and achieve remarkable classification performance. These achievements heavily depend on large-scale accurately annotated training data. However, label noise is inevitably introduced in the medical image annotation, as the labeling process heavily relies on the expertise and experience of annotators. Meanwhile, DNNs suffer from overfitting noisy labels, degrading the performance of models. Therefore, in this work, we innovatively devise noise-robust training approach to mitigate the adverse effects of noisy labels in medical image classification. Specifically, we incorporate contrastive learning and intra-group attention mixup strategies into the vanilla supervised learning. The contrastive learning for feature extractor helps to enhance visual representation of DNNs. The intra-group attention mixup module constructs groups and assigns self-attention weights for group-wise samples, and subsequently interpolates massive noisy-suppressed samples through weighted mixup operation. We conduct comparative experiments on both synthetic and real-world noisy medical datasets under various noise levels. Rigorous experiments validate that our noise-robust method with contrastive learning and attention mixup can effectively handle with label noise, and is superior to state-of-the-art methods. An ablation study also shows that both components contribute to boost model performance. The proposed method demonstrates its capability of curb label noise and has certain potential toward real-world clinic applications.
Protect Federated Learning Against Backdoor Attacks via Data-Free Trigger Generation
Aug 22, 2023
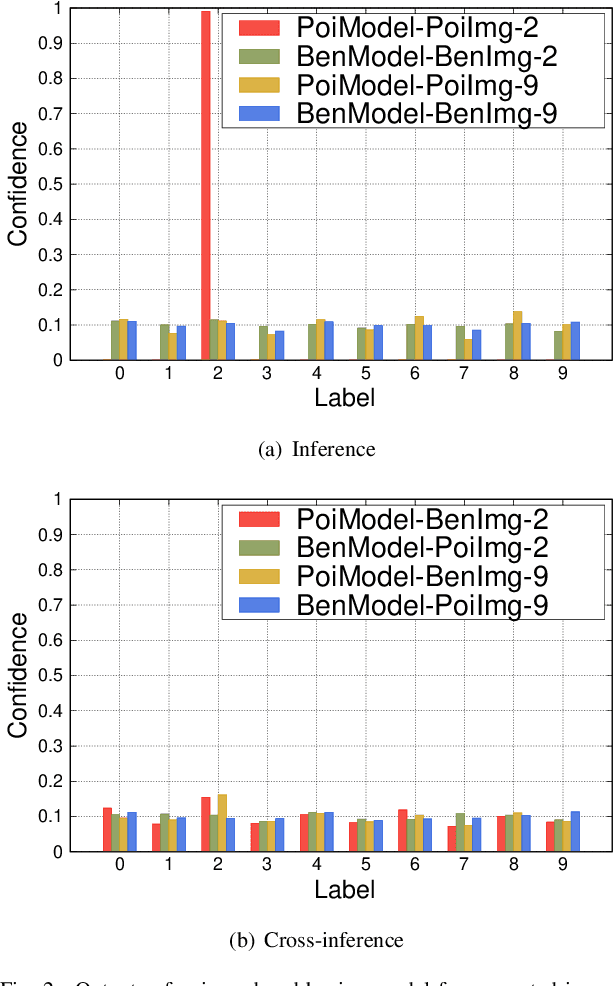
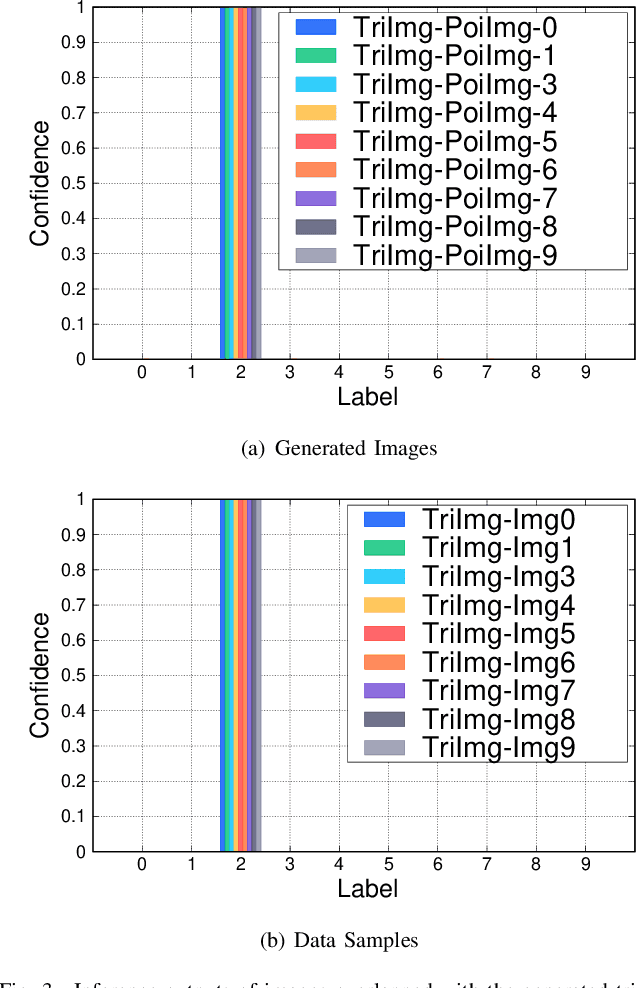
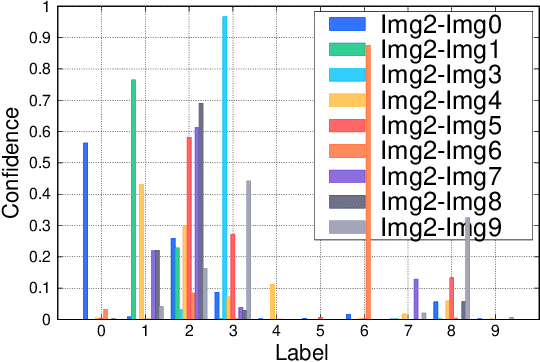
As a distributed machine learning paradigm, Federated Learning (FL) enables large-scale clients to collaboratively train a model without sharing their raw data. However, due to the lack of data auditing for untrusted clients, FL is vulnerable to poisoning attacks, especially backdoor attacks. By using poisoned data for local training or directly changing the model parameters, attackers can easily inject backdoors into the model, which can trigger the model to make misclassification of targeted patterns in images. To address these issues, we propose a novel data-free trigger-generation-based defense approach based on the two characteristics of backdoor attacks: i) triggers are learned faster than normal knowledge, and ii) trigger patterns have a greater effect on image classification than normal class patterns. Our approach generates the images with newly learned knowledge by identifying the differences between the old and new global models, and filters trigger images by evaluating the effect of these generated images. By using these trigger images, our approach eliminates poisoned models to ensure the updated global model is benign. Comprehensive experiments demonstrate that our approach can defend against almost all the existing types of backdoor attacks and outperform all the seven state-of-the-art defense methods with both IID and non-IID scenarios. Especially, our approach can successfully defend against the backdoor attack even when 80\% of the clients are malicious.
Improving Adversarial Robustness of Masked Autoencoders via Test-time Frequency-domain Prompting
Aug 22, 2023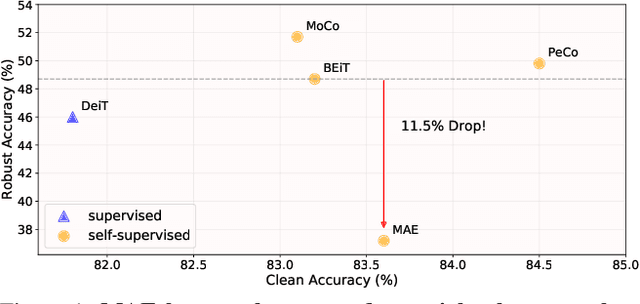
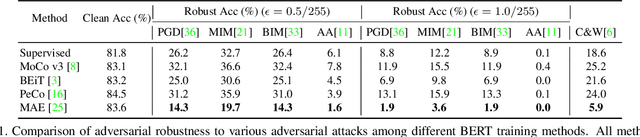
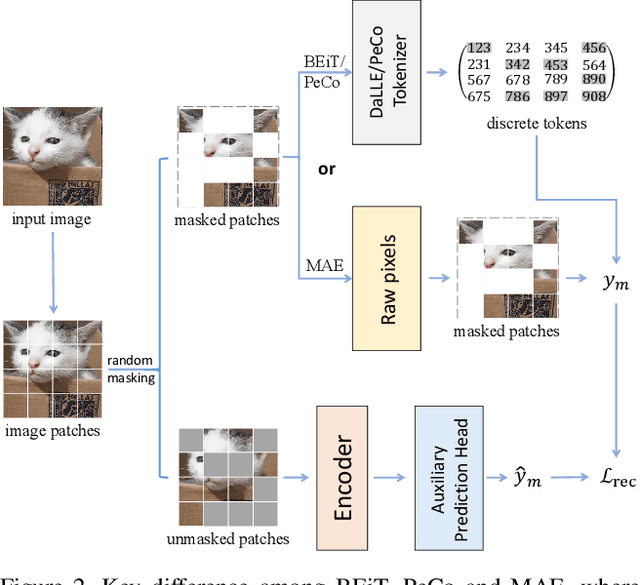

In this paper, we investigate the adversarial robustness of vision transformers that are equipped with BERT pretraining (e.g., BEiT, MAE). A surprising observation is that MAE has significantly worse adversarial robustness than other BERT pretraining methods. This observation drives us to rethink the basic differences between these BERT pretraining methods and how these differences affect the robustness against adversarial perturbations. Our empirical analysis reveals that the adversarial robustness of BERT pretraining is highly related to the reconstruction target, i.e., predicting the raw pixels of masked image patches will degrade more adversarial robustness of the model than predicting the semantic context, since it guides the model to concentrate more on medium-/high-frequency components of images. Based on our analysis, we provide a simple yet effective way to boost the adversarial robustness of MAE. The basic idea is using the dataset-extracted domain knowledge to occupy the medium-/high-frequency of images, thus narrowing the optimization space of adversarial perturbations. Specifically, we group the distribution of pretraining data and optimize a set of cluster-specific visual prompts on frequency domain. These prompts are incorporated with input images through prototype-based prompt selection during test period. Extensive evaluation shows that our method clearly boost MAE's adversarial robustness while maintaining its clean performance on ImageNet-1k classification. Our code is available at: https://github.com/shikiw/RobustMAE.
PatchBackdoor: Backdoor Attack against Deep Neural Networks without Model Modification
Aug 22, 2023Backdoor attack is a major threat to deep learning systems in safety-critical scenarios, which aims to trigger misbehavior of neural network models under attacker-controlled conditions. However, most backdoor attacks have to modify the neural network models through training with poisoned data and/or direct model editing, which leads to a common but false belief that backdoor attack can be easily avoided by properly protecting the model. In this paper, we show that backdoor attacks can be achieved without any model modification. Instead of injecting backdoor logic into the training data or the model, we propose to place a carefully-designed patch (namely backdoor patch) in front of the camera, which is fed into the model together with the input images. The patch can be trained to behave normally at most of the time, while producing wrong prediction when the input image contains an attacker-controlled trigger object. Our main techniques include an effective training method to generate the backdoor patch and a digital-physical transformation modeling method to enhance the feasibility of the patch in real deployments. Extensive experiments show that PatchBackdoor can be applied to common deep learning models (VGG, MobileNet, ResNet) with an attack success rate of 93% to 99% on classification tasks. Moreover, we implement PatchBackdoor in real-world scenarios and show that the attack is still threatening.
DiffCloth: Diffusion Based Garment Synthesis and Manipulation via Structural Cross-modal Semantic Alignment
Aug 22, 2023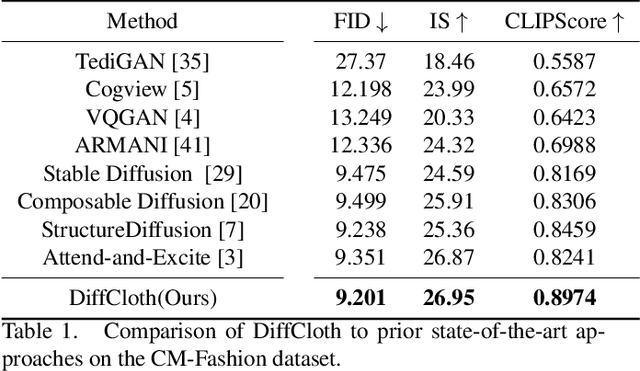

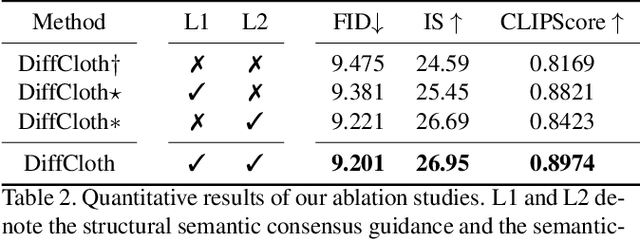
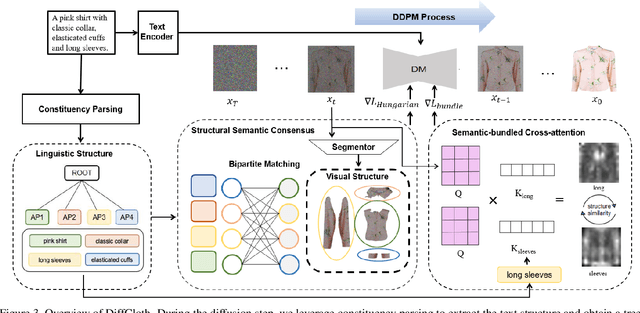
Cross-modal garment synthesis and manipulation will significantly benefit the way fashion designers generate garments and modify their designs via flexible linguistic interfaces.Current approaches follow the general text-to-image paradigm and mine cross-modal relations via simple cross-attention modules, neglecting the structural correspondence between visual and textual representations in the fashion design domain. In this work, we instead introduce DiffCloth, a diffusion-based pipeline for cross-modal garment synthesis and manipulation, which empowers diffusion models with flexible compositionality in the fashion domain by structurally aligning the cross-modal semantics. Specifically, we formulate the part-level cross-modal alignment as a bipartite matching problem between the linguistic Attribute-Phrases (AP) and the visual garment parts which are obtained via constituency parsing and semantic segmentation, respectively. To mitigate the issue of attribute confusion, we further propose a semantic-bundled cross-attention to preserve the spatial structure similarities between the attention maps of attribute adjectives and part nouns in each AP. Moreover, DiffCloth allows for manipulation of the generated results by simply replacing APs in the text prompts. The manipulation-irrelevant regions are recognized by blended masks obtained from the bundled attention maps of the APs and kept unchanged. Extensive experiments on the CM-Fashion benchmark demonstrate that DiffCloth both yields state-of-the-art garment synthesis results by leveraging the inherent structural information and supports flexible manipulation with region consistency.
Exemplar-Free Continual Transformer with Convolutions
Aug 22, 2023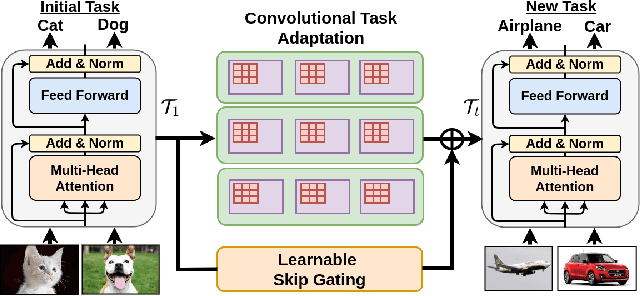
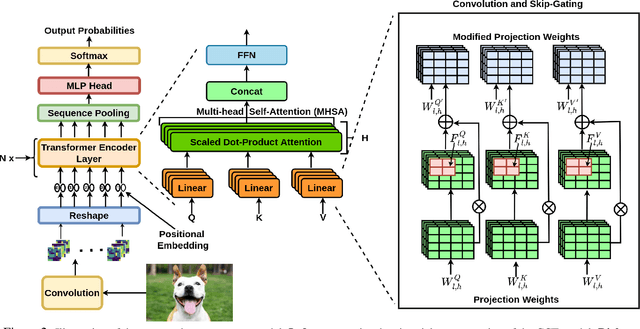
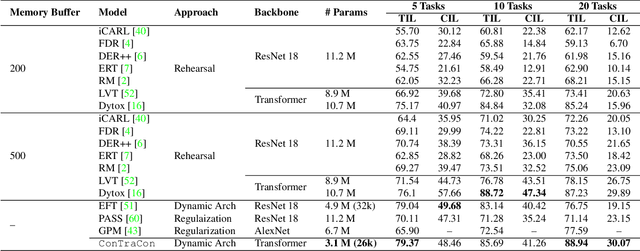
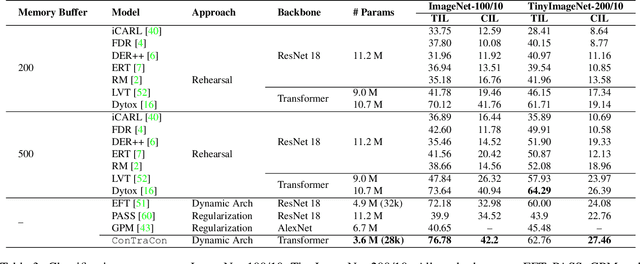
Continual Learning (CL) involves training a machine learning model in a sequential manner to learn new information while retaining previously learned tasks without the presence of previous training data. Although there has been significant interest in CL, most recent CL approaches in computer vision have focused on convolutional architectures only. However, with the recent success of vision transformers, there is a need to explore their potential for CL. Although there have been some recent CL approaches for vision transformers, they either store training instances of previous tasks or require a task identifier during test time, which can be limiting. This paper proposes a new exemplar-free approach for class/task incremental learning called ConTraCon, which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances. The proposed approach leverages the transformer architecture and involves re-weighting the key, query, and value weights of the multi-head self-attention layers of a transformer trained on a similar task. The re-weighting is done using convolution, which enables the approach to maintain low parameter requirements per task. Additionally, an image augmentation-based entropic task identification approach is used to predict tasks without requiring task-ids during inference. Experiments on four benchmark datasets demonstrate that the proposed approach outperforms several competitive approaches while requiring fewer parameters.
Data Curation for Image Captioning with Text-to-Image Generative Models
May 05, 2023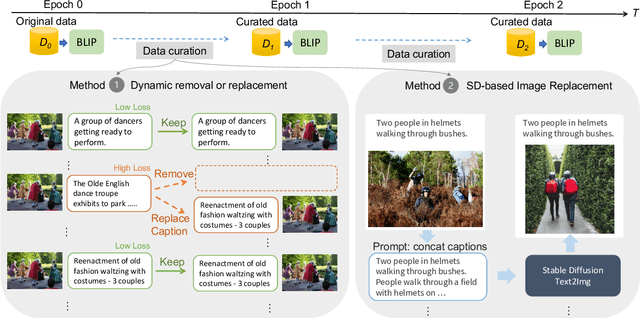
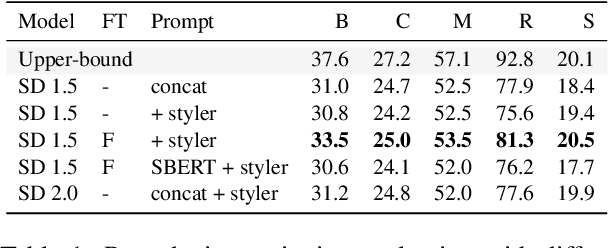
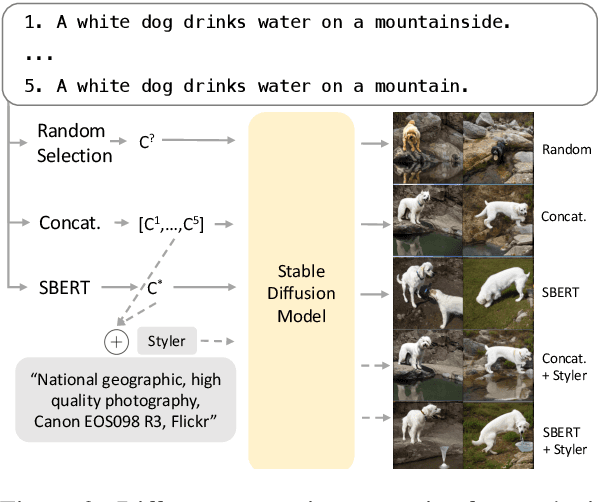
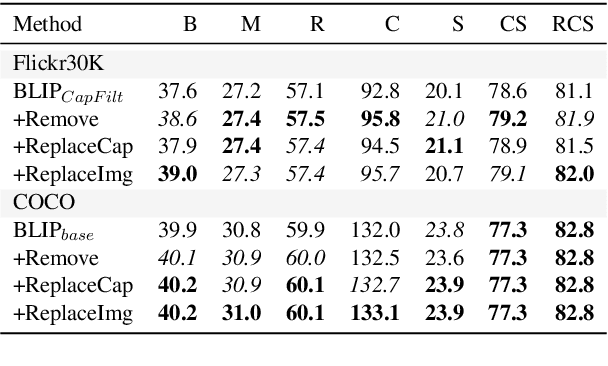
Recent advances in image captioning are mainly driven by large-scale vision-language pretraining, relying heavily on computational resources and increasingly large multimodal datasets. Instead of scaling up pretraining data, we ask whether it is possible to improve performance by improving the quality of the samples in existing datasets. We pursue this question through two approaches to data curation: one that assumes that some examples should be avoided due to mismatches between the image and caption, and one that assumes that the mismatch can be addressed by replacing the image, for which we use the state-of-the-art Stable Diffusion model. These approaches are evaluated using the BLIP model on MS COCO and Flickr30K in both finetuning and few-shot learning settings. Our simple yet effective approaches consistently outperform baselines, indicating that better image captioning models can be trained by curating existing resources. Finally, we conduct a human study to understand the errors made by the Stable Diffusion model and highlight directions for future work in text-to-image generation.
3D-Aware Neural Body Fitting for Occlusion Robust 3D Human Pose Estimation
Aug 19, 2023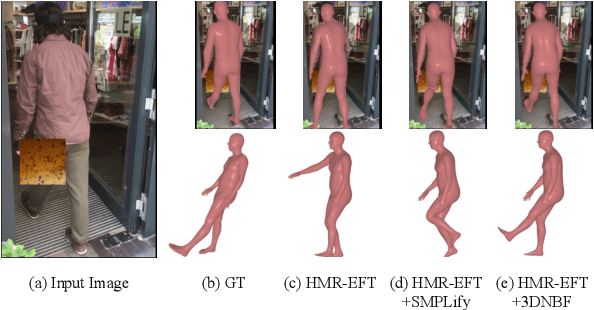

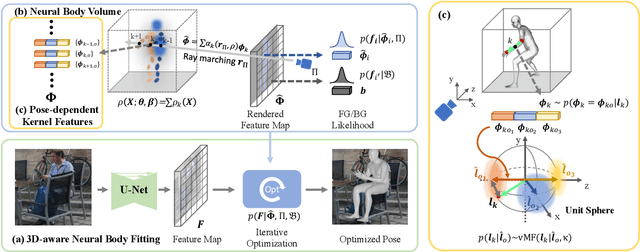
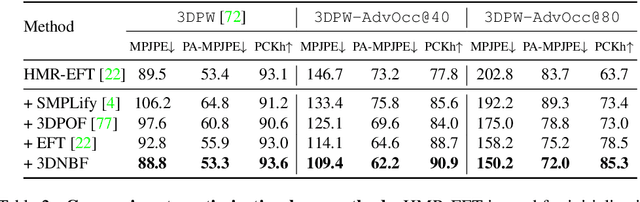
Regression-based methods for 3D human pose estimation directly predict the 3D pose parameters from a 2D image using deep networks. While achieving state-of-the-art performance on standard benchmarks, their performance degrades under occlusion. In contrast, optimization-based methods fit a parametric body model to 2D features in an iterative manner. The localized reconstruction loss can potentially make them robust to occlusion, but they suffer from the 2D-3D ambiguity. Motivated by the recent success of generative models in rigid object pose estimation, we propose 3D-aware Neural Body Fitting (3DNBF) - an approximate analysis-by-synthesis approach to 3D human pose estimation with SOTA performance and occlusion robustness. In particular, we propose a generative model of deep features based on a volumetric human representation with Gaussian ellipsoidal kernels emitting 3D pose-dependent feature vectors. The neural features are trained with contrastive learning to become 3D-aware and hence to overcome the 2D-3D ambiguity. Experiments show that 3DNBF outperforms other approaches on both occluded and standard benchmarks. Code is available at https://github.com/edz-o/3DNBF