 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Reading Comprehension
Machine reading comprehension is one of the key problems in Natural Language Understanding, where the task is to read and comprehend a given text passage, and then answer questions based on it.
Papers and Code
JobResQA: A Benchmark for LLM Machine Reading Comprehension on Multilingual Résumés and JDs
Jan 30, 2026We introduce JobResQA, a multilingual Question Answering benchmark for evaluating Machine Reading Comprehension (MRC) capabilities of LLMs on HR-specific tasks involving résumés and job descriptions. The dataset comprises 581 QA pairs across 105 synthetic résumé-job description pairs in five languages (English, Spanish, Italian, German, and Chinese), with questions spanning three complexity levels from basic factual extraction to complex cross-document reasoning. We propose a data generation pipeline derived from real-world sources through de-identification and data synthesis to ensure both realism and privacy, while controlled demographic and professional attributes (implemented via placeholders) enable systematic bias and fairness studies. We also present a cost-effective, human-in-the-loop translation pipeline based on the TEaR methodology, incorporating MQM error annotations and selective post-editing to ensure an high-quality multi-way parallel benchmark. We provide a baseline evaluations across multiple open-weight LLM families using an LLM-as-judge approach revealing higher performances on English and Spanish but substantial degradation for other languages, highlighting critical gaps in multilingual MRC capabilities for HR applications. JobResQA provides a reproducible benchmark for advancing fair and reliable LLM-based HR systems. The benchmark is publicly available at: https://github.com/Avature/jobresqa-benchmark
FIN-bench-v2: A Unified and Robust Benchmark Suite for Evaluating Finnish Large Language Models
Dec 15, 2025



We introduce FIN-bench-v2, a unified benchmark suite for evaluating large language models in Finnish. FIN-bench-v2 consolidates Finnish versions of widely used benchmarks together with an updated and expanded version of the original FIN-bench into a single, consistently formatted collection, covering multiple-choice and generative tasks across reading comprehension, commonsense reasoning, sentiment analysis, world knowledge, and alignment. All datasets are converted to HuggingFace Datasets, which include both cloze and multiple-choice prompt formulations with five variants per task, and we incorporate human annotation or review for machine-translated resources such as GoldenSwag and XED. To select robust tasks, we pretrain a set of 2.15B-parameter decoder-only models and use their learning curves to compute monotonicity, signal-to-noise, non-random performance, and model ordering consistency, retaining only tasks that satisfy all criteria. We further evaluate a set of larger instruction-tuned models to characterize performance across tasks and prompt formulations. All datasets, prompts, and evaluation configurations are publicly available via our fork of the Language Model Evaluation Harness at https://github.com/LumiOpen/lm-evaluation-harness. Supplementary resources are released in a separate repository at https://github.com/TurkuNLP/FIN-bench-v2.
Machine Learning Algorithms: Detection Official Hajj and Umrah Travel Agency Based on Text and Metadata Analysis
Dec 18, 2025The rapid digitalization of Hajj and Umrah services in Indonesia has significantly facilitated pilgrims but has concurrently opened avenues for digital fraud through counterfeit mobile applications. These fraudulent applications not only inflict financial losses but also pose severe privacy risks by harvesting sensitive personal data. This research aims to address this critical issue by implementing and evaluating machine learning algorithms to verify application authenticity automatically. Using a comprehensive dataset comprising both official applications registered with the Ministry of Religious Affairs and unofficial applications circulating on app stores, we compare the performance of three robust classifiers: Support Vector Machine (SVM), Random Forest (RF), and Na"ive Bayes (NB). The study utilizes a hybrid feature extraction methodology that combines Textual Analysis (TF-IDF) of application descriptions with Metadata Analysis of sensitive access permissions. The experimental results indicate that the SVM algorithm achieves the highest performance with an accuracy of 92.3%, a precision of 91.5%, and an F1-score of 92.0%. Detailed feature analysis reveals that specific keywords related to legality and high-risk permissions (e.g., READ PHONE STATE) are the most significant discriminators. This system is proposed as a proactive, scalable solution to enhance digital trust in the religious tourism sector, potentially serving as a prototype for a national verification system.
Does This Look Familiar to You? Knowledge Analysis via Model Internal Representations
Sep 09, 2025Recent advances in large language models (LLMs) have been driven by pretraining, supervised fine tuning (SFT), and alignment tuning. Among these, SFT plays a crucial role in transforming a model 's general knowledge into structured responses tailored to specific tasks. However, there is no clearly established methodology for effective training data selection. Simply increasing the volume of data does not guarantee performance improvements, while preprocessing, sampling, and validation require substantial time and cost. To address this issue, a variety of data selection methods have been proposed. Among them, knowledge based selection approaches identify suitable training data by analyzing the model 's responses. Nevertheless, these methods typically rely on prompt engineering, making them sensitive to variations and incurring additional costs for prompt design. In this study, we propose Knowledge Analysis via Model Internal Representations (KAMIR), a novel approach that overcomes these limitations by analyzing data based on the model 's internal representations. KAMIR computes similarities between the hidden states of each layer (block) and the final hidden states for a given input to assess the data. Unlike prior methods that were largely limited to multiple choice tasks, KAMIR can be applied to a wide range of tasks such as machine reading comprehension and summarization. Moreover, it selects data useful for training based on the model 's familiarity with the input, even with a small dataset and a simple classifier architecture. Experiments across diverse task datasets demonstrate that training with less familiar data leads to better generalization performance.
Detecting Reading-Induced Confusion Using EEG and Eye Tracking
Aug 20, 2025


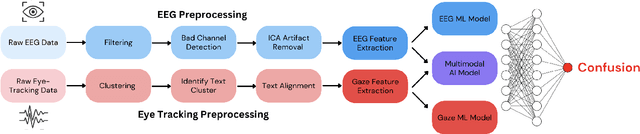
Humans regularly navigate an overwhelming amount of information via text media, whether reading articles, browsing social media, or interacting with chatbots. Confusion naturally arises when new information conflicts with or exceeds a reader's comprehension or prior knowledge, posing a challenge for learning. In this study, we present a multimodal investigation of reading-induced confusion using EEG and eye tracking. We collected neural and gaze data from 11 adult participants as they read short paragraphs sampled from diverse, real-world sources. By isolating the N400 event-related potential (ERP), a well-established neural marker of semantic incongruence, and integrating behavioral markers from eye tracking, we provide a detailed analysis of the neural and behavioral correlates of confusion during naturalistic reading. Using machine learning, we show that multimodal (EEG + eye tracking) models improve classification accuracy by 4-22% over unimodal baselines, reaching an average weighted participant accuracy of 77.3% and a best accuracy of 89.6%. Our results highlight the dominance of the brain's temporal regions in these neural signatures of confusion, suggesting avenues for wearable, low-electrode brain-computer interfaces (BCI) for real-time monitoring. These findings lay the foundation for developing adaptive systems that dynamically detect and respond to user confusion, with potential applications in personalized learning, human-computer interaction, and accessibility.
ViQA-COVID: COVID-19 Machine Reading Comprehension Dataset for Vietnamese
Apr 21, 2025After two years of appearance, COVID-19 has negatively affected people and normal life around the world. As in May 2022, there are more than 522 million cases and six million deaths worldwide (including nearly ten million cases and over forty-three thousand deaths in Vietnam). Economy and society are both severely affected. The variant of COVID-19, Omicron, has broken disease prevention measures of countries and rapidly increased number of infections. Resources overloading in treatment and epidemics prevention is happening all over the world. It can be seen that, application of artificial intelligence (AI) to support people at this time is extremely necessary. There have been many studies applying AI to prevent COVID-19 which are extremely useful, and studies on machine reading comprehension (MRC) are also in it. Realizing that, we created the first MRC dataset about COVID-19 for Vietnamese: ViQA-COVID and can be used to build models and systems, contributing to disease prevention. Besides, ViQA-COVID is also the first multi-span extraction MRC dataset for Vietnamese, we hope that it can contribute to promoting MRC studies in Vietnamese and multilingual.
Interpretable Traces, Unexpected Outcomes: Investigating the Disconnect in Trace-Based Knowledge Distillation
May 20, 2025Question Answering (QA) poses a challenging and critical problem, particularly in today's age of interactive dialogue systems such as ChatGPT, Perplexity, Microsoft Copilot, etc. where users demand both accuracy and transparency in the model's outputs. Since smaller language models (SLMs) are computationally more efficient but often under-perform compared to larger models, Knowledge Distillation (KD) methods allow for finetuning these smaller models to improve their final performance. Lately, the intermediate tokens or the so called `reasoning' traces produced by Chain-of-Thought (CoT) or by reasoning models such as DeepSeek R1 are used as a training signal for KD. However, these reasoning traces are often verbose and difficult to interpret or evaluate. In this work, we aim to address the challenge of evaluating the faithfulness of these reasoning traces and their correlation with the final performance. To this end, we employ a KD method leveraging rule-based problem decomposition. This approach allows us to break down complex queries into structured sub-problems, generating interpretable traces whose correctness can be readily evaluated, even at inference time. Specifically, we demonstrate this approach on Open Book QA, decomposing the problem into a Classification step and an Information Retrieval step, thereby simplifying trace evaluation. Our SFT experiments with correct and incorrect traces on the CoTemp QA, Microsoft Machine Reading Comprehension QA, and Facebook bAbI QA datasets reveal the striking finding that correct traces do not necessarily imply that the model outputs the correct final solution. Similarly, we find a low correlation between correct final solutions and intermediate trace correctness. These results challenge the implicit assumption behind utilizing reasoning traces for improving SLMs' final performance via KD.
MRCEval: A Comprehensive, Challenging and Accessible Machine Reading Comprehension Benchmark
Mar 10, 2025Machine Reading Comprehension (MRC) is an essential task in evaluating natural language understanding. Existing MRC datasets primarily assess specific aspects of reading comprehension (RC), lacking a comprehensive MRC benchmark. To fill this gap, we first introduce a novel taxonomy that categorizes the key capabilities required for RC. Based on this taxonomy, we construct MRCEval, an MRC benchmark that leverages advanced Large Language Models (LLMs) as both sample generators and selection judges. MRCEval is a comprehensive, challenging and accessible benchmark designed to assess the RC capabilities of LLMs thoroughly, covering 13 distinct RC skills with a total of 2.1K high-quality multi-choice questions. We perform an extensive evaluation of 28 widely used open-source and proprietary models, highlighting that MRC continues to present significant challenges even in the era of LLMs.
Understanding LLMs' Cross-Lingual Context Retrieval: How Good It Is And Where It Comes From
Apr 15, 2025



The ability of cross-lingual context retrieval is a fundamental aspect of cross-lingual alignment of large language models (LLMs), where the model extracts context information in one language based on requests in another language. Despite its importance in real-life applications, this ability has not been adequately investigated for state-of-the-art models. In this paper, we evaluate the cross-lingual context retrieval ability of over 40 LLMs across 12 languages to understand the source of this ability, using cross-lingual machine reading comprehension (xMRC) as a representative scenario. Our results show that several small, post-trained open LLMs show strong cross-lingual context retrieval ability, comparable to closed-source LLMs such as GPT-4o, and their estimated oracle performances greatly improve after post-training. Our interpretability analysis shows that the cross-lingual context retrieval process can be divided into two main phases: question encoding and answer retrieval, which are formed in pre-training and post-training, respectively. The phasing stability correlates with xMRC performance, and the xMRC bottleneck lies at the last model layers in the second phase, where the effect of post-training can be evidently observed. Our results also indicate that larger-scale pretraining cannot improve the xMRC performance. Instead, larger LLMs need further multilingual post-training to fully unlock their cross-lingual context retrieval potential. Our code and is available at https://github.com/NJUNLP/Cross-Lingual-Context-Retrieval
Pay Attention to Real World Perturbations! Natural Robustness Evaluation in Machine Reading Comprehension
Feb 23, 2025As neural language models achieve human-comparable performance on Machine Reading Comprehension (MRC) and see widespread adoption, ensuring their robustness in real-world scenarios has become increasingly important. Current robustness evaluation research, though, primarily develops synthetic perturbation methods, leaving unclear how well they reflect real life scenarios. Considering this, we present a framework to automatically examine MRC models on naturally occurring textual perturbations, by replacing paragraph in MRC benchmarks with their counterparts based on available Wikipedia edit history. Such perturbation type is natural as its design does not stem from an arteficial generative process, inherently distinct from the previously investigated synthetic approaches. In a large-scale study encompassing SQUAD datasets and various model architectures we observe that natural perturbations result in performance degradation in pre-trained encoder language models. More worryingly, these state-of-the-art Flan-T5 and Large Language Models (LLMs) inherit these errors. Further experiments demonstrate that our findings generalise to natural perturbations found in other more challenging MRC benchmarks. In an effort to mitigate these errors, we show that it is possible to improve the robustness to natural perturbations by training on naturally or synthetically perturbed examples, though a noticeable gap still remains compared to performance on unperturbed data.