 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Environment Asr
Papers and Code
TG-ASR: Translation-Guided Learning with Parallel Gated Cross Attention for Low-Resource Automatic Speech Recognition
Feb 25, 2026Low-resource automatic speech recognition (ASR) continues to pose significant challenges, primarily due to the limited availability of transcribed data for numerous languages. While a wealth of spoken content is accessible in television dramas and online videos, Taiwanese Hokkien exemplifies this issue, with transcriptions often being scarce and the majority of available subtitles provided only in Mandarin. To address this deficiency, we introduce TG-ASR for Taiwanese Hokkien drama speech recognition, a translation-guided ASR framework that utilizes multilingual translation embeddings to enhance recognition performance in low-resource environments. The framework is centered around the parallel gated cross-attention (PGCA) mechanism, which adaptively integrates embeddings from various auxiliary languages into the ASR decoder. This mechanism facilitates robust cross-linguistic semantic guidance while ensuring stable optimization and minimizing interference between languages. To support ongoing research initiatives, we present YT-THDC, a 30-hour corpus of Taiwanese Hokkien drama speech with aligned Mandarin subtitles and manually verified Taiwanese Hokkien transcriptions. Comprehensive experiments and analyses identify the auxiliary languages that most effectively enhance ASR performance, achieving a 14.77% relative reduction in character error rate and demonstrating the efficacy of translation-guided learning for underrepresented languages in practical applications.
DBMIF: a deep balanced multimodal iterative fusion framework for air- and bone-conduction speech enhancement
Mar 03, 2026The performance of conventional speech enhancement systems degrades sharply in extremely low signal-to-noise ratio (SNR) environments where air-conduction (AC) microphones are overwhelmed by ambient noise. Although bone-conduction (BC) sensors offer complementary, noise-tolerant information, existing fusion approaches struggle to maintain consistent performance across a wide range of SNR conditions. To address this limitation, we propose the Deep Balanced Multimodal Iterative Fusion Framework (DBMIF), a three-branch architecture designed to reconstruct high-fidelity speech through rigorous cross-modal interaction. Specifically, grounded in a multi-scale interactive encoder-decoder backbone, the framework orchestrates an iterative attention module and a cross-branch gated module to facilitate adaptive weighting and bidirectional exchange. To complement this dynamic interaction, a balanced-interaction bottleneck is further integrated to learn a compact, stable fused representation. Extensive experiments demonstrate that DBMIF achieves competitive performance compared with recent unimodal and multimodal baselines in both speech quality and intelligibility across diverse noise types. In downstream ASR tasks, the proposed method reduces the character error rate by at least 2.5 percent compared to competing approaches. These results confirm that DBMIF effectively harnesses the robustness of BC speech while preserving the naturalness of AC speech, ensuring reliability in real-world scenarios. The source code is publicly available at github.com/wyl516w/dbmif.
SE-DiCoW: Self-Enrolled Diarization-Conditioned Whisper
Jan 27, 2026Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a major challenge. While some approaches achieve strong performance when fine-tuned on specific domains, few systems generalize well across out-of-domain datasets. Our prior work, Diarization-Conditioned Whisper (DiCoW), leverages speaker diarization outputs as conditioning information and, with minimal fine-tuning, demonstrated strong multilingual and multi-domain performance. In this paper, we address a key limitation of DiCoW: ambiguity in Silence-Target-Non-target-Overlap (STNO) masks, where two or more fully overlapping speakers may have nearly identical conditioning despite differing transcriptions. We introduce SE-DiCoW (Self-Enrolled Diarization-Conditioned Whisper), which uses diarization output to locate an enrollment segment anywhere in the conversation where the target speaker is most active. This enrollment segment is used as fixed conditioning via cross-attention at each encoder layer. We further refine DiCoW with improved data segmentation, model initialization, and augmentation. Together, these advances yield substantial gains: SE-DiCoW reduces macro-averaged tcpWER by 52.4% relative to the original DiCoW on the EMMA MT-ASR benchmark.
Unifying Speech Recognition, Synthesis and Conversion with Autoregressive Transformers
Jan 15, 2026Traditional speech systems typically rely on separate, task-specific models for text-to-speech (TTS), automatic speech recognition (ASR), and voice conversion (VC), resulting in fragmented pipelines that limit scalability, efficiency, and cross-task generalization. In this paper, we present General-Purpose Audio (GPA), a unified audio foundation model that integrates multiple core speech tasks within a single large language model (LLM) architecture. GPA operates on a shared discrete audio token space and supports instruction-driven task induction, enabling a single autoregressive model to flexibly perform TTS, ASR, and VC without architectural modifications. This unified design combines a fully autoregressive formulation over discrete speech tokens, joint multi-task training across speech domains, and a scalable inference pipeline that achieves high concurrency and throughput. The resulting model family supports efficient multi-scale deployment, including a lightweight 0.3B-parameter variant optimized for edge and resource-constrained environments. Together, these design choices demonstrate that a unified autoregressive architecture can achieve competitive performance across diverse speech tasks while remaining viable for low-latency, practical deployment.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025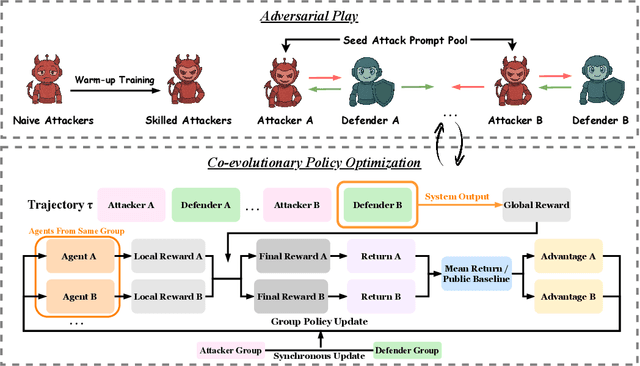

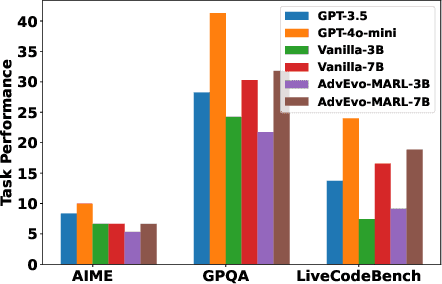
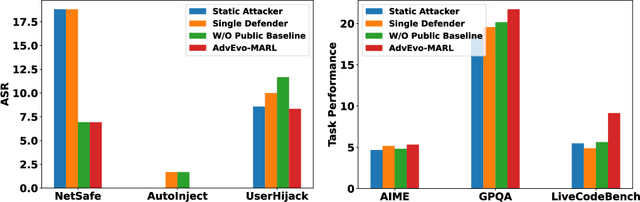
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
The Tower of Babel Revisited: Multilingual Jailbreak Prompts on Closed-Source Large Language Models
May 18, 2025



Large language models (LLMs) have seen widespread applications across various domains, yet remain vulnerable to adversarial prompt injections. While most existing research on jailbreak attacks and hallucination phenomena has focused primarily on open-source models, we investigate the frontier of closed-source LLMs under multilingual attack scenarios. We present a first-of-its-kind integrated adversarial framework that leverages diverse attack techniques to systematically evaluate frontier proprietary solutions, including GPT-4o, DeepSeek-R1, Gemini-1.5-Pro, and Qwen-Max. Our evaluation spans six categories of security contents in both English and Chinese, generating 38,400 responses across 32 types of jailbreak attacks. Attack success rate (ASR) is utilized as the quantitative metric to assess performance from three dimensions: prompt design, model architecture, and language environment. Our findings suggest that Qwen-Max is the most vulnerable, while GPT-4o shows the strongest defense. Notably, prompts in Chinese consistently yield higher ASRs than their English counterparts, and our novel Two-Sides attack technique proves to be the most effective across all models. This work highlights a dire need for language-aware alignment and robust cross-lingual defenses in LLMs, and we hope it will inspire researchers, developers, and policymakers toward more robust and inclusive AI systems.
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Nov 21, 2024



The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users' personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50\%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
IndicVoices-R: Unlocking a Massive Multilingual Multi-speaker Speech Corpus for Scaling Indian TTS
Sep 09, 2024



Recent advancements in text-to-speech (TTS) synthesis show that large-scale models trained with extensive web data produce highly natural-sounding output. However, such data is scarce for Indian languages due to the lack of high-quality, manually subtitled data on platforms like LibriVox or YouTube. To address this gap, we enhance existing large-scale ASR datasets containing natural conversations collected in low-quality environments to generate high-quality TTS training data. Our pipeline leverages the cross-lingual generalization of denoising and speech enhancement models trained on English and applied to Indian languages. This results in IndicVoices-R (IV-R), the largest multilingual Indian TTS dataset derived from an ASR dataset, with 1,704 hours of high-quality speech from 10,496 speakers across 22 Indian languages. IV-R matches the quality of gold-standard TTS datasets like LJSpeech, LibriTTS, and IndicTTS. We also introduce the IV-R Benchmark, the first to assess zero-shot, few-shot, and many-shot speaker generalization capabilities of TTS models on Indian voices, ensuring diversity in age, gender, and style. We demonstrate that fine-tuning an English pre-trained model on a combined dataset of high-quality IndicTTS and our IV-R dataset results in better zero-shot speaker generalization compared to fine-tuning on the IndicTTS dataset alone. Further, our evaluation reveals limited zero-shot generalization for Indian voices in TTS models trained on prior datasets, which we improve by fine-tuning the model on our data containing diverse set of speakers across language families. We open-source all data and code, releasing the first TTS model for all 22 official Indian languages.
LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition
Jun 06, 2024



Visual cues, like lip motion, have been shown to improve the performance of Automatic Speech Recognition (ASR) systems in noisy environments. We propose LipGER (Lip Motion aided Generative Error Correction), a novel framework for leveraging visual cues for noise-robust ASR. Instead of learning the cross-modal correlation between the audio and visual modalities, we make an LLM learn the task of visually-conditioned (generative) ASR error correction. Specifically, we instruct an LLM to predict the transcription from the N-best hypotheses generated using ASR beam-search. This is further conditioned on lip motions. This approach addresses key challenges in traditional AVSR learning, such as the lack of large-scale paired datasets and difficulties in adapting to new domains. We experiment on 4 datasets in various settings and show that LipGER improves the Word Error Rate in the range of 1.1%-49.2%. We also release LipHyp, a large-scale dataset with hypothesis-transcription pairs that is additionally equipped with lip motion cues to promote further research in this space
Dynamical Embedding of Single Channel Electroencephalogram for Artifact Subspace Reconstruction
Jun 28, 2024



This study introduces a novel framework to apply Artifact Subspace Reconstruction (ASR) algorithm on single-channel Electroencephalogram (EEG) data. ASR, renowned for its automated capability to effectively eliminate various artifacts like eye-blinks and eye movements from EEG signals. Importantly it has been implemented on android smartphones, but relied on multiple channels for principal component subspace calculations. To overcome this limitation, we incorporate the established dynamical embedding approach into the algorithm, naming it Embedded-ASR (E-ASR). In our proposed method, an embedded matrix is first constructed from a single-channel EEG data using series of delay vectors. ASR is then applied to this embedded matrix, and the resulting cleaned single-channel EEG is reconstructed by removing the time lag and concatenating the rows of the embedded matrix. Data was collected from four subjects in resting states with eyes open from pre-frontal (Fp1 and Fp2) electrodes using CameraEEG app. To assess the effectiveness of the E-ASR algorithm on an EEG dataset with artifacts, we employed performance metrics such as relative root mean square error (RRMSE), correlation coefficient (CC), average power ratio as well as estimated the number of eye-blinks with and without the E-ASR approach. E-ASR was able to reduce artifacts from the semi-simulated EEG data, with an RRMSE of 45.45% and a CC of 0.91. For real EEG data, the counted eye-blinks were manually cross-checked with ground truth obtained from CameraEEG video data across all subjects for individual Fp1 and Fp2 electrodes. In conclusion, our study suggests E-ASR framework can remove artifacts from single channel EEG data. This promising algorithm might have potential for smartphone-based natural environment EEG applications, where minimal number of electrodes is a critical factor.