 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Spoken LLMs in Multi-Speaker Audio via Diarization Conditioning
Jun 16, 2026We propose diarization-conditioned spoken language models (SLMs), a strategy for extending SLMs to far-field multi-talker audio. Rather than adapting the decoder via Serialized Output Training, which risks catastrophic forgetting, we condition the acoustic encoder on diarization masks to extract target-speaker representations, keeping the decoder frozen. We instantiate this as Dixtral, integrating a Diarization Conditioned Whisper (DiCoW) encoder into the Voxtral SLM. On AMI, NOTSOFAR-1, LibriSpeechMix, and Mixer6, Dixtral outperforms Gemini 3.0 Flash, VibeVoice, and Voxtral Mini Transcribe V2 on speaker-attributed transcription by 29.0%, 19.8%, and 16.0% absolute cpWER respectively. On a novel long-form multi-speaker QA benchmark, zero-shot Dixtral matches Gemini on far-field content understanding, and when fine-tuned surpasses both Gemini and Voxtral operating on close-talk across all tasks.
SpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
SE-DiCoW: Self-Enrolled Diarization-Conditioned Whisper
Jan 27, 2026Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a major challenge. While some approaches achieve strong performance when fine-tuned on specific domains, few systems generalize well across out-of-domain datasets. Our prior work, Diarization-Conditioned Whisper (DiCoW), leverages speaker diarization outputs as conditioning information and, with minimal fine-tuning, demonstrated strong multilingual and multi-domain performance. In this paper, we address a key limitation of DiCoW: ambiguity in Silence-Target-Non-target-Overlap (STNO) masks, where two or more fully overlapping speakers may have nearly identical conditioning despite differing transcriptions. We introduce SE-DiCoW (Self-Enrolled Diarization-Conditioned Whisper), which uses diarization output to locate an enrollment segment anywhere in the conversation where the target speaker is most active. This enrollment segment is used as fixed conditioning via cross-attention at each encoder layer. We further refine DiCoW with improved data segmentation, model initialization, and augmentation. Together, these advances yield substantial gains: SE-DiCoW reduces macro-averaged tcpWER by 52.4% relative to the original DiCoW on the EMMA MT-ASR benchmark.
DeCRED: Decoder-Centric Regularization for Encoder-Decoder Based Speech Recognition
Aug 12, 2025



This paper presents a simple yet effective regularization for the internal language model induced by the decoder in encoder-decoder ASR models, thereby improving robustness and generalization in both in- and out-of-domain settings. The proposed method, Decoder-Centric Regularization in Encoder-Decoder (DeCRED), adds auxiliary classifiers to the decoder, enabling next token prediction via intermediate logits. Empirically, DeCRED reduces the mean internal LM BPE perplexity by 36.6% relative to 11 test sets. Furthermore, this translates into actual WER improvements over the baseline in 5 of 7 in-domain and 3 of 4 out-of-domain test sets, reducing macro WER from 6.4% to 6.3% and 18.2% to 16.2%, respectively. On TEDLIUM3, DeCRED achieves 7.0% WER, surpassing the baseline and encoder-centric InterCTC regularization by 0.6% and 0.5%, respectively. Finally, we compare DeCRED with OWSM v3.1 and Whisper-medium, showing competitive WERs despite training on much less data with fewer parameters.
BUT System for the MLC-SLM Challenge
Jun 16, 2025



We present a two-speaker automatic speech recognition (ASR) system that combines DiCoW -- a diarization-conditioned variant of Whisper -- with DiariZen, a diarization pipeline built on top of Pyannote. We first evaluate both systems in out-of-domain (OOD) multilingual scenarios without any fine-tuning. In this scenario, DiariZen consistently outperforms the baseline Pyannote diarization model, demonstrating strong generalization. Despite being fine-tuned on English-only data for target-speaker ASR, DiCoW retains solid multilingual performance, indicating that encoder modifications preserve Whisper's multilingual capabilities. We then fine-tune both DiCoW and DiariZen on the MLC-SLM challenge data. The fine-tuned DiariZen continues to outperform the fine-tuned Pyannote baseline, while DiCoW sees further gains from domain adaptation. Our final system achieves a micro-average tcpWER/CER of 16.75% and ranks second in Task 2 of the MLC-SLM challenge. Lastly, we identify several labeling inconsistencies in the training data -- such as missing speech segments and incorrect silence annotations -- which can hinder diarization fine-tuning. We propose simple mitigation strategies to address these issues and improve system robustness.
Factors affecting the in-context learning abilities of LLMs for dialogue state tracking
Jun 10, 2025This study explores the application of in-context learning (ICL) to the dialogue state tracking (DST) problem and investigates the factors that influence its effectiveness. We use a sentence embedding based k-nearest neighbour method to retrieve the suitable demonstrations for ICL. The selected demonstrations, along with the test samples, are structured within a template as input to the LLM. We then conduct a systematic study to analyse the impact of factors related to demonstration selection and prompt context on DST performance. This work is conducted using the MultiWoZ2.4 dataset and focuses primarily on the OLMo-7B-instruct, Mistral-7B-Instruct-v0.3, and Llama3.2-3B-Instruct models. Our findings provide several useful insights on in-context learning abilities of LLMs for dialogue state tracking.
Approaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025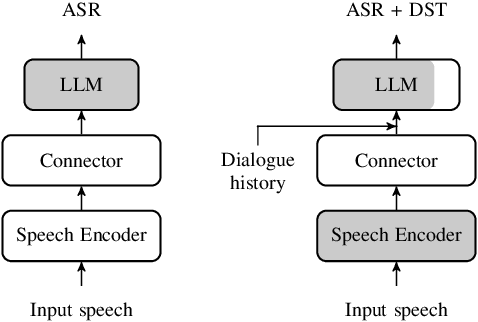
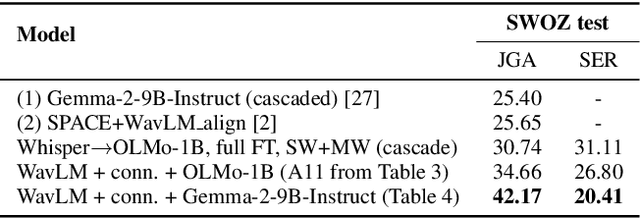
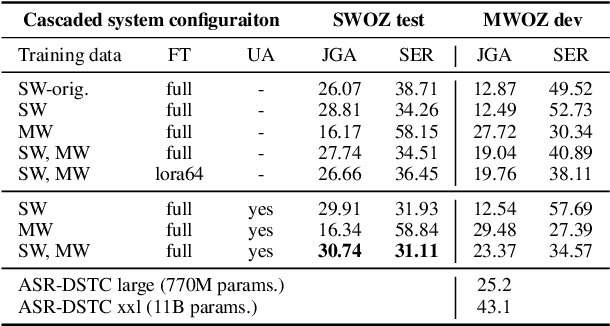
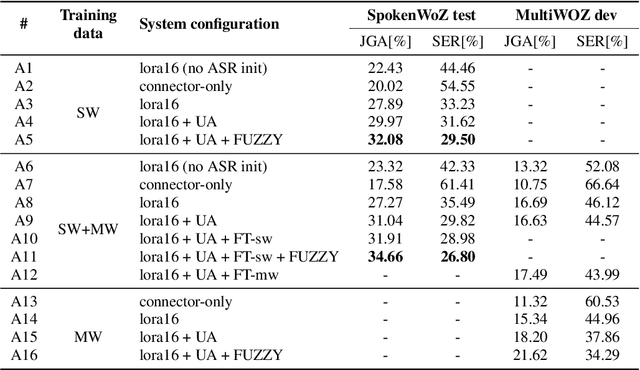
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
TS-SUPERB: A Target Speech Processing Benchmark for Speech Self-Supervised Learning Models
May 10, 2025



Self-supervised learning (SSL) models have significantly advanced speech processing tasks, and several benchmarks have been proposed to validate their effectiveness. However, previous benchmarks have primarily focused on single-speaker scenarios, with less exploration of target-speaker tasks in noisy, multi-talker conditions -- a more challenging yet practical case. In this paper, we introduce the Target-Speaker Speech Processing Universal Performance Benchmark (TS-SUPERB), which includes four widely recognized target-speaker processing tasks that require identifying the target speaker and extracting information from the speech mixture. In our benchmark, the speaker embedding extracted from enrollment speech is used as a clue to condition downstream models. The benchmark result reveals the importance of evaluating SSL models in target speaker scenarios, demonstrating that performance cannot be easily inferred from related single-speaker tasks. Moreover, by using a unified SSL-based target speech encoder, consisting of a speaker encoder and an extractor module, we also investigate joint optimization across TS tasks to leverage mutual information and demonstrate its effectiveness.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024



Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
Aligning Pre-trained Models for Spoken Language Translation
Nov 27, 2024This paper investigates a novel approach to end-to-end speech translation (ST) based on aligning frozen pre-trained automatic speech recognition (ASR) and machine translation (MT) models via a small connector module (Q-Former, our Subsampler-Transformer Encoder). This connector bridges the gap between the speech and text modalities, transforming ASR encoder embeddings into the latent representation space of the MT encoder while being the only part of the system optimized during training. Experiments are conducted on the How2 English-Portuguese dataset as we investigate the alignment approach in a small-scale scenario focusing on ST. While keeping the size of the connector module constant and small in comparison ( < 5% of the size of the larger aligned models), increasing the size and capability of the foundation ASR and MT models universally improves translation results. We also find that the connectors can serve as domain adapters for the foundation MT models, significantly improving translation performance in the aligned ST setting. We conclude that this approach represents a viable and scalable approach to training end-to-end ST systems.