 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient On-Policy Distillation for Automatic Speech Recognition
May 27, 2026Building competitive automatic speech recognition (ASR) models usually requires large-scale au- dio supervision, which makes reproduction and specialization expensive. We study Ark-ASR, a 0.6B- parameter audio-conditioned language model trained with 100k hours of speech, and examine whether a strong Qwen-ASR teacher can transfer additional recognition capability through on-policy distillation. Across Mandarin and English ASR benchmarks, the proposed training recipe consistently improves over supervised fine-tuning alone and outperforms the same-scale Qwen3-ASR-0.6B baseline on four of five evaluation sets. This is achieved with only 100k hours of speech, compared with the 20M hours of super- vised audio reported for the Qwen3-Omni AuT encoder. The larger Qwen3-ASR-1.7B remains stronger, but the results show that teacher-guided on-policy training can substantially close the gap for compact ASR models under a much smaller audio budget. A support-overlap diagnostic further suggests that the teacher-data stage improves local student-teacher compatibility, matching recent analyses of when on-policy distillation is effective.
Tiny-Engram: Trigger-Indexed Concept Tables for Generative Vision
May 19, 2026Current personalization methods for generative vision models typically encode new concepts through continuous adapters or weight updates, yet provide limited control over whether and when a concept should be retrieved. In this work, we introduce Tiny-Engram, a compact trigger-indexed concept table that gives visual memories an explicit lexical address and activation boundary inside frozen image and video generators. Tiny-Engram parameterizes each concept as a small set of memory entries indexed by registered n-gram matches, which modulate text-encoder hidden states only within the matched trigger region. Outside this lexical support, the conditioning pathway is identical to that of the frozen base model. Across both single-encoder latent diffusion and multi-encoder diffusion-transformer backbones, this formulation binds a rare trigger phrase to a target identity while preserving compositional control from the surrounding prompt. We further evaluate the same table-based memory in a text-conditioned video generation setting, where the trigger path reliably alters the generated subject but fine-grained identity persistence across held-out video prompts remains limited. Taken together, these results suggest that small, explicitly addressed concept tables are a practical route to modular visual personalization, with strongest evidence in image generation. For video diffusion, the remaining gap points to a broader requirement: temporally stable identity likely depends on tighter coupling between text-side memory and the evolving visual state, motivating future work on memory injection beyond the text-conditioning interface.
Unifying Speech Recognition, Synthesis and Conversion with Autoregressive Transformers
Jan 15, 2026Traditional speech systems typically rely on separate, task-specific models for text-to-speech (TTS), automatic speech recognition (ASR), and voice conversion (VC), resulting in fragmented pipelines that limit scalability, efficiency, and cross-task generalization. In this paper, we present General-Purpose Audio (GPA), a unified audio foundation model that integrates multiple core speech tasks within a single large language model (LLM) architecture. GPA operates on a shared discrete audio token space and supports instruction-driven task induction, enabling a single autoregressive model to flexibly perform TTS, ASR, and VC without architectural modifications. This unified design combines a fully autoregressive formulation over discrete speech tokens, joint multi-task training across speech domains, and a scalable inference pipeline that achieves high concurrency and throughput. The resulting model family supports efficient multi-scale deployment, including a lightweight 0.3B-parameter variant optimized for edge and resource-constrained environments. Together, these design choices demonstrate that a unified autoregressive architecture can achieve competitive performance across diverse speech tasks while remaining viable for low-latency, practical deployment.
FreqNet: A Frequency-domain Image Super-Resolution Network with Dicrete Cosine Transform
Nov 21, 2021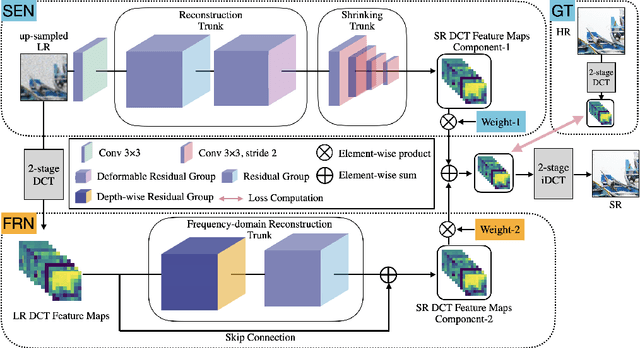
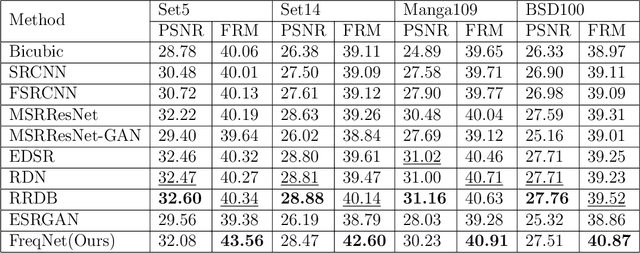

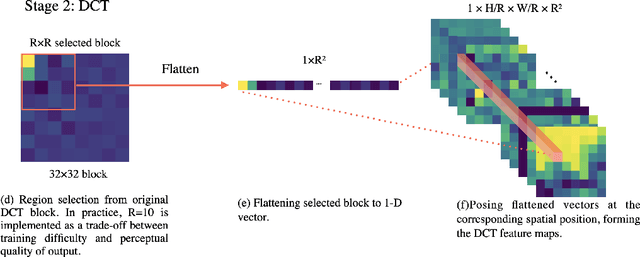
Single image super-resolution(SISR) is an ill-posed problem that aims to obtain high-resolution (HR) output from low-resolution (LR) input, during which extra high-frequency information is supposed to be added to improve the perceptual quality. Existing SISR works mainly operate in the spatial domain by minimizing the mean squared reconstruction error. Despite the high peak signal-to-noise ratios(PSNR) results, it is difficult to determine whether the model correctly adds desired high-frequency details. Some residual-based structures are proposed to guide the model to focus on high-frequency features implicitly. However, how to verify the fidelity of those artificial details remains a problem since the interpretation from spatial-domain metrics is limited. In this paper, we propose FreqNet, an intuitive pipeline from the frequency domain perspective, to solve this problem. Inspired by existing frequency-domain works, we convert images into discrete cosine transform (DCT) blocks, then reform them to obtain the DCT feature maps, which serve as the input and target of our model. A specialized pipeline is designed, and we further propose a frequency loss function to fit the nature of our frequency-domain task. Our SISR method in the frequency domain can learn the high-frequency information explicitly, provide fidelity and good perceptual quality for the SR images. We further observe that our model can be merged with other spatial super-resolution models to enhance the quality of their original SR output.