 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2d
Papers and Code
GroPrompt: Efficient Grounded Prompting and Adaptation for Referring Video Object Segmentation
Jun 18, 2024



Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence throughout the entire video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we aim to efficiently adapt foundation segmentation models for addressing RVOS from weak supervision with the proposed Grounded Prompting (GroPrompt) framework. More specifically, we propose Text-Aware Prompt Contrastive Learning (TAP-CL) to enhance the association between the position prompts and the referring sentences with only box supervisions, including Text-Contrastive Prompt Learning (TextCon) and Modality-Contrastive Prompt Learning (ModalCon) at frame level and video level, respectively. With the proposed TAP-CL, our GroPrompt framework can generate temporal-consistent yet text-aware position prompts describing locations and movements for the referred object from the video. The experimental results in the standard RVOS benchmarks (Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, and JHMDB-Sentences) demonstrate the competitive performance of our proposed GroPrompt framework given only bounding box weak supervisions.
MultiOOD: Scaling Out-of-Distribution Detection for Multiple Modalities
May 27, 2024Detecting out-of-distribution (OOD) samples is important for deploying machine learning models in safety-critical applications such as autonomous driving and robot-assisted surgery. Existing research has mainly focused on unimodal scenarios on image data. However, real-world applications are inherently multimodal, which makes it essential to leverage information from multiple modalities to enhance the efficacy of OOD detection. To establish a foundation for more realistic Multimodal OOD Detection, we introduce the first-of-its-kind benchmark, MultiOOD, characterized by diverse dataset sizes and varying modality combinations. We first evaluate existing unimodal OOD detection algorithms on MultiOOD, observing that the mere inclusion of additional modalities yields substantial improvements. This underscores the importance of utilizing multiple modalities for OOD detection. Based on the observation of Modality Prediction Discrepancy between in-distribution (ID) and OOD data, and its strong correlation with OOD performance, we propose the Agree-to-Disagree (A2D) algorithm to encourage such discrepancy during training. Moreover, we introduce a novel outlier synthesis method, NP-Mix, which explores broader feature spaces by leveraging the information from nearest neighbor classes and complements A2D to strengthen OOD detection performance. Extensive experiments on MultiOOD demonstrate that training with A2D and NP-Mix improves existing OOD detection algorithms by a large margin. Our source code and MultiOOD benchmark are available at https://github.com/donghao51/MultiOOD.
Align-to-Distill: Trainable Attention Alignment for Knowledge Distillation in Neural Machine Translation
Mar 03, 2024The advent of scalable deep models and large datasets has improved the performance of Neural Machine Translation. Knowledge Distillation (KD) enhances efficiency by transferring knowledge from a teacher model to a more compact student model. However, KD approaches to Transformer architecture often rely on heuristics, particularly when deciding which teacher layers to distill from. In this paper, we introduce the 'Align-to-Distill' (A2D) strategy, designed to address the feature mapping problem by adaptively aligning student attention heads with their teacher counterparts during training. The Attention Alignment Module in A2D performs a dense head-by-head comparison between student and teacher attention heads across layers, turning the combinatorial mapping heuristics into a learning problem. Our experiments show the efficacy of A2D, demonstrating gains of up to +3.61 and +0.63 BLEU points for WMT-2022 De->Dsb and WMT-2014 En->De, respectively, compared to Transformer baselines.
Fully Transformer-Equipped Architecture for End-to-End Referring Video Object Segmentation
Sep 21, 2023Referring Video Object Segmentation (RVOS) requires segmenting the object in video referred by a natural language query. Existing methods mainly rely on sophisticated pipelines to tackle such cross-modal task, and do not explicitly model the object-level spatial context which plays an important role in locating the referred object. Therefore, we propose an end-to-end RVOS framework completely built upon transformers, termed \textit{Fully Transformer-Equipped Architecture} (FTEA), which treats the RVOS task as a mask sequence learning problem and regards all the objects in video as candidate objects. Given a video clip with a text query, the visual-textual features are yielded by encoder, while the corresponding pixel-level and word-level features are aligned in terms of semantic similarity. To capture the object-level spatial context, we have developed the Stacked Transformer, which individually characterizes the visual appearance of each candidate object, whose feature map is decoded to the binary mask sequence in order directly. Finally, the model finds the best matching between mask sequence and text query. In addition, to diversify the generated masks for candidate objects, we impose a diversity loss on the model for capturing more accurate mask of the referred object. Empirical studies have shown the superiority of the proposed method on three benchmarks, e.g., FETA achieves 45.1% and 38.7% in terms of mAP on A2D Sentences (3782 videos) and J-HMDB Sentences (928 videos), respectively; it achieves 56.6% in terms of $\mathcal{J\&F}$ on Ref-YouTube-VOS (3975 videos and 7451 objects). Particularly, compared to the best candidate method, it has a gain of 2.1% and 3.2% in terms of P$@$0.5 on the former two, respectively, while it has a gain of 2.9% in terms of $\mathcal{J}$ on the latter one.
OnlineRefer: A Simple Online Baseline for Referring Video Object Segmentation
Jul 18, 2023



Referring video object segmentation (RVOS) aims at segmenting an object in a video following human instruction. Current state-of-the-art methods fall into an offline pattern, in which each clip independently interacts with text embedding for cross-modal understanding. They usually present that the offline pattern is necessary for RVOS, yet model limited temporal association within each clip. In this work, we break up the previous offline belief and propose a simple yet effective online model using explicit query propagation, named OnlineRefer. Specifically, our approach leverages target cues that gather semantic information and position prior to improve the accuracy and ease of referring predictions for the current frame. Furthermore, we generalize our online model into a semi-online framework to be compatible with video-based backbones. To show the effectiveness of our method, we evaluate it on four benchmarks, \ie, Refer-Youtube-VOS, Refer-DAVIS17, A2D-Sentences, and JHMDB-Sentences. Without bells and whistles, our OnlineRefer with a Swin-L backbone achieves 63.5 J&F and 64.8 J&F on Refer-Youtube-VOS and Refer-DAVIS17, outperforming all other offline methods.
LoSh: Long-Short Text Joint Prediction Network for Referring Video Object Segmentation
Jun 14, 2023



Referring video object segmentation (RVOS) aims to segment the target instance referred by a given text expression in a video clip. The text expression normally contains sophisticated descriptions of the instance's appearance, actions, and relations with others. It is therefore rather difficult for an RVOS model to capture all these attributes correspondingly in the video; in fact, the model often favours more on the action- and relation-related visual attribute of the instance. This can end up with incomplete or even incorrect mask prediction of the target instance. In this paper, we tackle this problem by taking a subject-centric short text expression from the original long text expression. The short one retains only the appearance-related information of the target instance so that we can use it to focus the model's attention on the instance's appearance. We let the model make joint predictions using both long and short text expressions and introduce a long-short predictions intersection loss to align the joint predictions. Besides the improvement on the linguistic part, we also introduce a forward-backward visual consistency loss, which utilizes optical flows to warp visual features between the annotated frames and their temporal neighbors for consistency. We build our method on top of two state of the art transformer-based pipelines for end-to-end training. Extensive experiments on A2D-Sentences and JHMDB-Sentences datasets show impressive improvements of our method.
A2D: Anywhere Anytime Drumming
Apr 04, 2023



The drum kit, which has only been around for around 100 years, is a popular instrument in many music genres such as pop, rock, and jazz. However, the road to owning a kit is expensive, both financially and space-wise. Also, drums are more difficult to move around compared to other instruments, as they do not fit into a single bag. We propose a no-drums approach that uses only two sticks and a smartphone or a webcam to provide an air-drumming experience. The detection algorithm combines deep learning tools with tracking methods for an enhanced user experience. Based on both quantitative and qualitative testing with humans-in-the-loop, we show that our system has zero misses for beginner level play and negligible misses for advanced level play. Additionally, our limited human trials suggest potential directions for future research.
Language-Bridged Spatial-Temporal Interaction for Referring Video Object Segmentation
Jun 08, 2022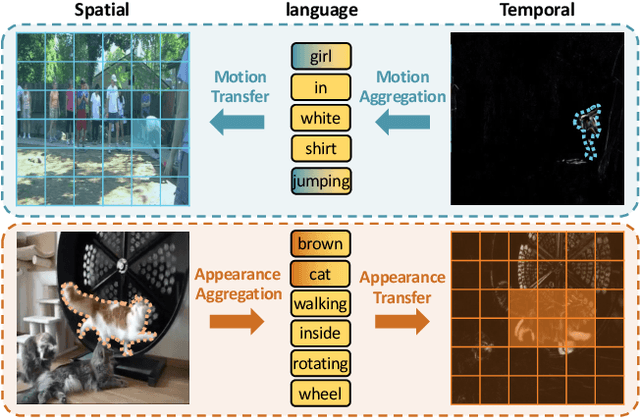
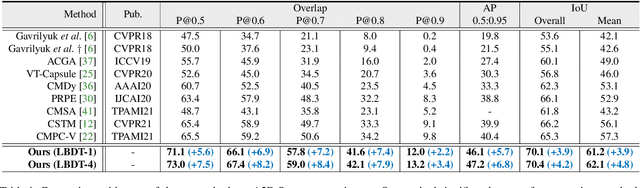
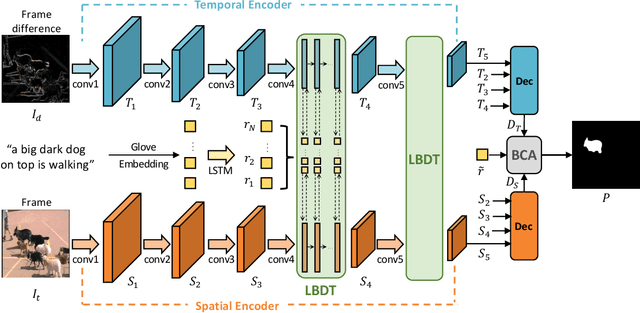
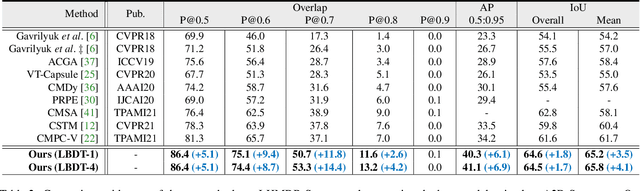
Referring video object segmentation aims to predict foreground labels for objects referred by natural language expressions in videos. Previous methods either depend on 3D ConvNets or incorporate additional 2D ConvNets as encoders to extract mixed spatial-temporal features. However, these methods suffer from spatial misalignment or false distractors due to delayed and implicit spatial-temporal interaction occurring in the decoding phase. To tackle these limitations, we propose a Language-Bridged Duplex Transfer (LBDT) module which utilizes language as an intermediary bridge to accomplish explicit and adaptive spatial-temporal interaction earlier in the encoding phase. Concretely, cross-modal attention is performed among the temporal encoder, referring words and the spatial encoder to aggregate and transfer language-relevant motion and appearance information. In addition, we also propose a Bilateral Channel Activation (BCA) module in the decoding phase for further denoising and highlighting the spatial-temporal consistent features via channel-wise activation. Extensive experiments show our method achieves new state-of-the-art performances on four popular benchmarks with 6.8% and 6.9% absolute AP gains on A2D Sentences and J-HMDB Sentences respectively, while consuming around 7x less computational overhead.
Modeling Motion with Multi-Modal Features for Text-Based Video Segmentation
Apr 06, 2022
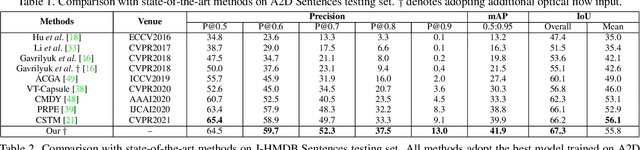
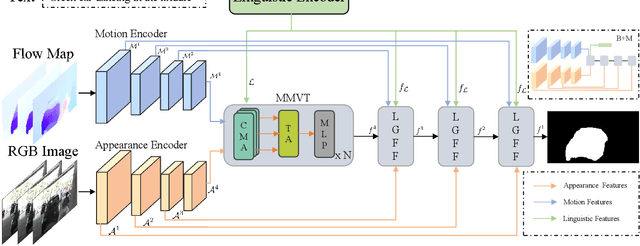
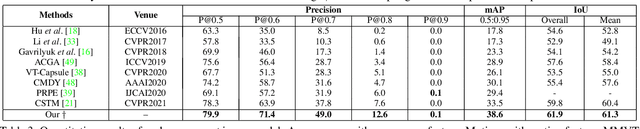
Text-based video segmentation aims to segment the target object in a video based on a describing sentence. Incorporating motion information from optical flow maps with appearance and linguistic modalities is crucial yet has been largely ignored by previous work. In this paper, we design a method to fuse and align appearance, motion, and linguistic features to achieve accurate segmentation. Specifically, we propose a multi-modal video transformer, which can fuse and aggregate multi-modal and temporal features between frames. Furthermore, we design a language-guided feature fusion module to progressively fuse appearance and motion features in each feature level with guidance from linguistic features. Finally, a multi-modal alignment loss is proposed to alleviate the semantic gap between features from different modalities. Extensive experiments on A2D Sentences and J-HMDB Sentences verify the performance and the generalization ability of our method compared to the state-of-the-art methods.
Local-Global Context Aware Transformer for Language-Guided Video Segmentation
Mar 18, 2022



We explore the task of language-guided video segmentation (LVS). Previous algorithms mostly adopt 3D CNNs to learn video representation, struggling to capture long-term context and easily suffering from visual-linguistic misalignment. In light of this, we present Locater (local-global context aware Transformer), which augments the Transformer architecture with a finite memory so as to query the entire video with the language expression in an efficient manner. The memory is designed to involve two components -- one for persistently preserving global video content, and one for dynamically gathering local temporal context and segmentation history. Based on the memorized local-global context and the particular content of each frame, Locater holistically and flexibly comprehends the expression as an adaptive query vector for each frame. The vector is used to query the corresponding frame for mask generation. The memory also allows Locater to process videos with linear time complexity and constant size memory, while Transformer-style self-attention computation scales quadratically with sequence length. To thoroughly examine the visual grounding capability of LVS models, we contribute a new LVS dataset, A2D-S+, which is built upon A2D-S dataset but poses increased challenges in disambiguating among similar objects. Experiments on three LVS datasets and our A2D-S+ show that Locater outperforms previous state-of-the-arts. Further, our Locater based solution achieved the 1st place in the Referring Video Object Segmentation Track of the 3rd Large-scale Video Object Segmentation Challenge. Our code and dataset are available at: https://github.com/leonnnop/Locater