 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Referring Video Object Segmentation through Text Supervision
Apr 21, 2026Referring video object segmentation (RVOS) aims to segment the target instance in a video, referred by a text expression. Conventional approaches are mostly supervised learning, requiring expensive pixel-level mask annotations. To tackle it, weakly-supervised RVOS has recently been proposed to replace mask annotations with bounding boxes or points, which are however still costly and labor-intensive. In this paper, we design a novel weakly-supervised RVOS method, namely WSRVOS, to train the model with only text expressions. Given an input video and the referring expression, we first design a contrastive referring expression augmentation scheme that leverages the captioning capabilities of a multimodal large language model to generate both positive and negative expressions. We extract visual and linguistic features from the input video and generated expressions, then perform bi-directional vision-language feature selection and interaction to enable fine-grained multimodal alignment. Next, we propose an instance-aware expression classification scheme to optimize the model in distinguishing positive from negative expressions. Also, we introduce a positive-prediction fusion strategy to generate high-quality pseudo-masks, which serve as additional supervision to the model. Last, we design a temporal segment ranking constraint such that the overlaps between mask predictions of temporally neighboring frames are required to conform to specific orders. Extensive experiments on four publicly available RVOS datasets, including A2D Sentences, J-HMDB Sentences, Ref-YouTube-VOS, and Ref-DAVIS17, demonstrate the superiority of our method. Code is available at https://github.com/viscom-tongji/WSRVOS.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
Bootstrapping MLLM for Weakly-Supervised Class-Agnostic Object Counting
Feb 13, 2026Object counting is a fundamental task in computer vision, with broad applicability in many real-world scenarios. Fully-supervised counting methods require costly point-level annotations per object. Few weakly-supervised methods leverage only image-level object counts as supervision and achieve fairly promising results. They are, however, often limited to counting a single category, e.g. person. In this paper, we propose WS-COC, the first MLLM-driven weakly-supervised framework for class-agnostic object counting. Instead of directly fine-tuning MLLMs to predict object counts, which can be challenging due to the modality gap, we incorporate three simple yet effective strategies to bootstrap the counting paradigm in both training and testing: First, a divide-and-discern dialogue tuning strategy is proposed to guide the MLLM to determine whether the object count falls within a specific range and progressively break down the range through multi-round dialogue. Second, a compare-and-rank count optimization strategy is introduced to train the MLLM to optimize the relative ranking of multiple images according to their object counts. Third, a global-and-local counting enhancement strategy aggregates and fuses local and global count predictions to improve counting performance in dense scenes. Extensive experiments on FSC-147, CARPK, PUCPR+, and ShanghaiTech show that WS-COC matches or even surpasses many state-of-art fully-supervised methods while significantly reducing annotation costs. Code is available at https://github.com/viscom-tongji/WS-COC.
Text-promptable Object Counting via Quantity Awareness Enhancement
Jul 09, 2025



Recent advances in large vision-language models (VLMs) have shown remarkable progress in solving the text-promptable object counting problem. Representative methods typically specify text prompts with object category information in images. This however is insufficient for training the model to accurately distinguish the number of objects in the counting task. To this end, we propose QUANet, which introduces novel quantity-oriented text prompts with a vision-text quantity alignment loss to enhance the model's quantity awareness. Moreover, we propose a dual-stream adaptive counting decoder consisting of a Transformer stream, a CNN stream, and a number of Transformer-to-CNN enhancement adapters (T2C-adapters) for density map prediction. The T2C-adapters facilitate the effective knowledge communication and aggregation between the Transformer and CNN streams. A cross-stream quantity ranking loss is proposed in the end to optimize the ranking orders of predictions from the two streams. Extensive experiments on standard benchmarks such as FSC-147, CARPK, PUCPR+, and ShanghaiTech demonstrate our model's strong generalizability for zero-shot class-agnostic counting. Code is available at https://github.com/viscom-tongji/QUANet
Bootstrapping Vision-language Models for Self-supervised Remote Physiological Measurement
Jul 11, 2024



Facial video-based remote physiological measurement is a promising research area for detecting human vital signs (e.g., heart rate, respiration frequency) in a non-contact way. Conventional approaches are mostly supervised learning, requiring extensive collections of facial videos and synchronously recorded photoplethysmography (PPG) signals. To tackle it, self-supervised learning has recently gained attentions; due to the lack of ground truth PPG signals, its performance is however limited. In this paper, we propose a novel self-supervised framework that successfully integrates the popular vision-language models (VLMs) into the remote physiological measurement task. Given a facial video, we first augment its positive and negative video samples with varying rPPG signal frequencies. Next, we introduce a frequency-oriented vision-text pair generation method by carefully creating contrastive spatio-temporal maps from positive and negative samples and designing proper text prompts to describe their relative ratios of signal frequencies. A pre-trained VLM is employed to extract features for these formed vision-text pairs and estimate rPPG signals thereafter. We develop a series of generative and contrastive learning mechanisms to optimize the VLM, including the text-guided visual map reconstruction task, the vision-text contrastive learning task, and the frequency contrastive and ranking task. Overall, our method for the first time adapts VLMs to digest and align the frequency-related knowledge in vision and text modalities. Extensive experiments on four benchmark datasets demonstrate that it significantly outperforms state of the art self-supervised methods.
Large Model driven Radiology Report Generation with Clinical Quality Reinforcement Learning
Mar 11, 2024



Radiology report generation (RRG) has attracted significant attention due to its potential to reduce the workload of radiologists. Current RRG approaches are still unsatisfactory against clinical standards. This paper introduces a novel RRG method, \textbf{LM-RRG}, that integrates large models (LMs) with clinical quality reinforcement learning to generate accurate and comprehensive chest X-ray radiology reports. Our method first designs a large language model driven feature extractor to analyze and interpret different regions of the chest X-ray image, emphasizing specific regions with medical significance. Next, based on the large model's decoder, we develop a multimodal report generator that leverages multimodal prompts from visual features and textual instruction to produce the radiology report in an auto-regressive way. Finally, to better reflect the clinical significant and insignificant errors that radiologists would normally assign in the report, we introduce a novel clinical quality reinforcement learning strategy. It utilizes the radiology report clinical quality (RadCliQ) metric as a reward function in the learning process. Extensive experiments on the MIMIC-CXR and IU-Xray datasets demonstrate the superiority of our method over the state of the art.
LoSh: Long-Short Text Joint Prediction Network for Referring Video Object Segmentation
Jun 14, 2023



Referring video object segmentation (RVOS) aims to segment the target instance referred by a given text expression in a video clip. The text expression normally contains sophisticated descriptions of the instance's appearance, actions, and relations with others. It is therefore rather difficult for an RVOS model to capture all these attributes correspondingly in the video; in fact, the model often favours more on the action- and relation-related visual attribute of the instance. This can end up with incomplete or even incorrect mask prediction of the target instance. In this paper, we tackle this problem by taking a subject-centric short text expression from the original long text expression. The short one retains only the appearance-related information of the target instance so that we can use it to focus the model's attention on the instance's appearance. We let the model make joint predictions using both long and short text expressions and introduce a long-short predictions intersection loss to align the joint predictions. Besides the improvement on the linguistic part, we also introduce a forward-backward visual consistency loss, which utilizes optical flows to warp visual features between the annotated frames and their temporal neighbors for consistency. We build our method on top of two state of the art transformer-based pipelines for end-to-end training. Extensive experiments on A2D-Sentences and JHMDB-Sentences datasets show impressive improvements of our method.
Video-based Remote Physiological Measurement via Self-supervised Learning
Oct 28, 2022



Video-based remote physiological measurement aims to estimate remote photoplethysmography (rPPG) signals from human face videos and then measure multiple vital signs (e.g. heart rate, respiration frequency) from rPPG signals. Recent approaches achieve it by training deep neural networks, which normally require abundant face videos and synchronously recorded photoplethysmography (PPG) signals for supervision. However, the collection of these annotated corpora is uneasy in practice. In this paper, we introduce a novel frequency-inspired self-supervised framework that learns to estimate rPPG signals from face videos without the need of ground truth PPG signals. Given a video sample, we first augment it into multiple positive/negative samples which contain similar/dissimilar signal frequencies to the original one. Specifically, positive samples are generated using spatial augmentation. Negative samples are generated via a learnable frequency augmentation module, which performs non-linear signal frequency transformation on the input without excessively changing its visual appearance. Next, we introduce a local rPPG expert aggregation module to estimate rPPG signals from augmented samples. It encodes complementary pulsation information from different face regions and aggregate them into one rPPG prediction. Finally, we propose a series of frequency-inspired losses, i.e. frequency contrastive loss, frequency ratio consistency loss, and cross-video frequency agreement loss, for the optimization of estimated rPPG signals from multiple augmented video samples and across temporally neighboring video samples. We conduct rPPG-based heart rate, heart rate variability and respiration frequency estimation on four standard benchmarks. The experimental results demonstrate that our method improves the state of the art by a large margin.
Enhancing Space-time Video Super-resolution via Spatial-temporal Feature Interaction
Jul 18, 2022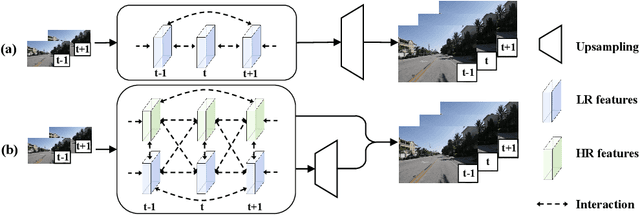
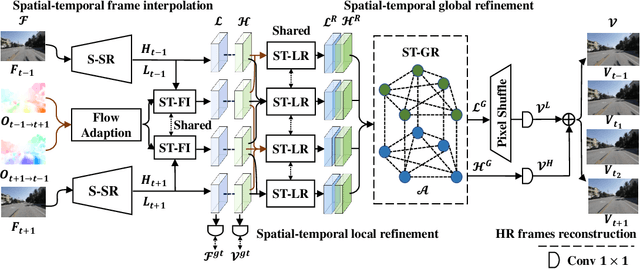
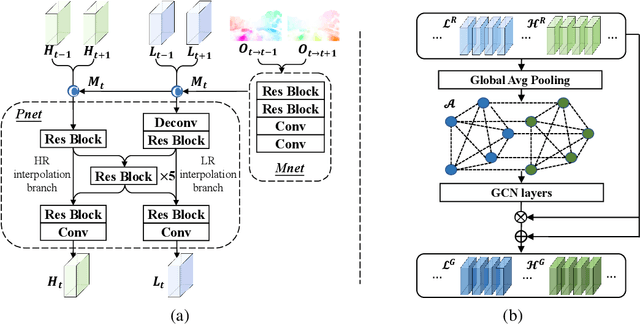
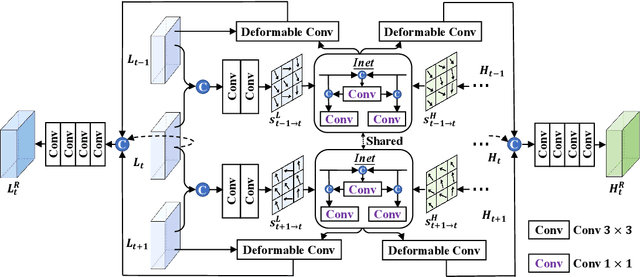
The target of space-time video super-resolution (STVSR) is to increase both the frame rate (also referred to as the temporal resolution) and the spatial resolution of a given video. Recent approaches solve STVSR with end-to-end deep neural networks. A popular solution is to first increase the frame rate of the video; then perform feature refinement among different frame features; and last increase the spatial resolutions of these features. The temporal correlation among features of different frames is carefully exploited in this process. The spatial correlation among features of different (spatial) resolutions, despite being also very important, is however not emphasized. In this paper, we propose a spatial-temporal feature interaction network to enhance STVSR by exploiting both spatial and temporal correlations among features of different frames and spatial resolutions. Specifically, the spatial-temporal frame interpolation module is introduced to interpolate low- and high-resolution intermediate frame features simultaneously and interactively. The spatial-temporal local and global refinement modules are respectively deployed afterwards to exploit the spatial-temporal correlation among different features for their refinement. Finally, a novel motion consistency loss is employed to enhance the motion continuity among reconstructed frames. We conduct experiments on three standard benchmarks, Vid4, Vimeo-90K and Adobe240, and the results demonstrate that our method improves the state of the art methods by a considerable margin. Our codes will be available at https://github.com/yuezijie/STINet-Space-time-Video-Super-resolution.