 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-labeling with Keyword Refining for Few-Supervised Video Captioning
Nov 06, 2024



Video captioning generate a sentence that describes the video content. Existing methods always require a number of captions (\eg, 10 or 20) per video to train the model, which is quite costly. In this work, we explore the possibility of using only one or very few ground-truth sentences, and introduce a new task named few-supervised video captioning. Specifically, we propose a few-supervised video captioning framework that consists of lexically constrained pseudo-labeling module and keyword-refined captioning module. Unlike the random sampling in natural language processing that may cause invalid modifications (\ie, edit words), the former module guides the model to edit words using some actions (\eg, copy, replace, insert, and delete) by a pretrained token-level classifier, and then fine-tunes candidate sentences by a pretrained language model. Meanwhile, the former employs the repetition penalized sampling to encourage the model to yield concise pseudo-labeled sentences with less repetition, and selects the most relevant sentences upon a pretrained video-text model. Moreover, to keep semantic consistency between pseudo-labeled sentences and video content, we develop the transformer-based keyword refiner with the video-keyword gated fusion strategy to emphasize more on relevant words. Extensive experiments on several benchmarks demonstrate the advantages of the proposed approach in both few-supervised and fully-supervised scenarios. The code implementation is available at https://github.com/mlvccn/PKG_VidCap
Pair-wise Layer Attention with Spatial Masking for Video Prediction
Nov 19, 2023Video prediction yields future frames by employing the historical frames and has exhibited its great potential in many applications, e.g., meteorological prediction, and autonomous driving. Previous works often decode the ultimate high-level semantic features to future frames without texture details, which deteriorates the prediction quality. Motivated by this, we develop a Pair-wise Layer Attention (PLA) module to enhance the layer-wise semantic dependency of the feature maps derived from the U-shape structure in Translator, by coupling low-level visual cues and high-level features. Hence, the texture details of predicted frames are enriched. Moreover, most existing methods capture the spatiotemporal dynamics by Translator, but fail to sufficiently utilize the spatial features of Encoder. This inspires us to design a Spatial Masking (SM) module to mask partial encoding features during pretraining, which adds the visibility of remaining feature pixels by Decoder. To this end, we present a Pair-wise Layer Attention with Spatial Masking (PLA-SM) framework for video prediction to capture the spatiotemporal dynamics, which reflect the motion trend. Extensive experiments and rigorous ablation studies on five benchmarks demonstrate the advantages of the proposed approach. The code is available at GitHub.
Adversarial Attacks on Video Object Segmentation with Hard Region Discovery
Sep 25, 2023Video object segmentation has been applied to various computer vision tasks, such as video editing, autonomous driving, and human-robot interaction. However, the methods based on deep neural networks are vulnerable to adversarial examples, which are the inputs attacked by almost human-imperceptible perturbations, and the adversary (i.e., attacker) will fool the segmentation model to make incorrect pixel-level predictions. This will rise the security issues in highly-demanding tasks because small perturbations to the input video will result in potential attack risks. Though adversarial examples have been extensively used for classification, it is rarely studied in video object segmentation. Existing related methods in computer vision either require prior knowledge of categories or cannot be directly applied due to the special design for certain tasks, failing to consider the pixel-wise region attack. Hence, this work develops an object-agnostic adversary that has adversarial impacts on VOS by first-frame attacking via hard region discovery. Particularly, the gradients from the segmentation model are exploited to discover the easily confused region, in which it is difficult to identify the pixel-wise objects from the background in a frame. This provides a hardness map that helps to generate perturbations with a stronger adversarial power for attacking the first frame. Empirical studies on three benchmarks indicate that our attacker significantly degrades the performance of several state-of-the-art video object segmentation models.
Triple-View Knowledge Distillation for Semi-Supervised Semantic Segmentation
Sep 22, 2023To alleviate the expensive human labeling, semi-supervised semantic segmentation employs a few labeled images and an abundant of unlabeled images to predict the pixel-level label map with the same size. Previous methods often adopt co-training using two convolutional networks with the same architecture but different initialization, which fails to capture the sufficiently diverse features. This motivates us to use tri-training and develop the triple-view encoder to utilize the encoders with different architectures to derive diverse features, and exploit the knowledge distillation skill to learn the complementary semantics among these encoders. Moreover, existing methods simply concatenate the features from both encoder and decoder, resulting in redundant features that require large memory cost. This inspires us to devise a dual-frequency decoder that selects those important features by projecting the features from the spatial domain to the frequency domain, where the dual-frequency channel attention mechanism is introduced to model the feature importance. Therefore, we propose a Triple-view Knowledge Distillation framework, termed TriKD, for semi-supervised semantic segmentation, including the triple-view encoder and the dual-frequency decoder. Extensive experiments were conducted on two benchmarks, \ie, Pascal VOC 2012 and Cityscapes, whose results verify the superiority of the proposed method with a good tradeoff between precision and inference speed.
Fully Transformer-Equipped Architecture for End-to-End Referring Video Object Segmentation
Sep 21, 2023Referring Video Object Segmentation (RVOS) requires segmenting the object in video referred by a natural language query. Existing methods mainly rely on sophisticated pipelines to tackle such cross-modal task, and do not explicitly model the object-level spatial context which plays an important role in locating the referred object. Therefore, we propose an end-to-end RVOS framework completely built upon transformers, termed \textit{Fully Transformer-Equipped Architecture} (FTEA), which treats the RVOS task as a mask sequence learning problem and regards all the objects in video as candidate objects. Given a video clip with a text query, the visual-textual features are yielded by encoder, while the corresponding pixel-level and word-level features are aligned in terms of semantic similarity. To capture the object-level spatial context, we have developed the Stacked Transformer, which individually characterizes the visual appearance of each candidate object, whose feature map is decoded to the binary mask sequence in order directly. Finally, the model finds the best matching between mask sequence and text query. In addition, to diversify the generated masks for candidate objects, we impose a diversity loss on the model for capturing more accurate mask of the referred object. Empirical studies have shown the superiority of the proposed method on three benchmarks, e.g., FETA achieves 45.1% and 38.7% in terms of mAP on A2D Sentences (3782 videos) and J-HMDB Sentences (928 videos), respectively; it achieves 56.6% in terms of $\mathcal{J\&F}$ on Ref-YouTube-VOS (3975 videos and 7451 objects). Particularly, compared to the best candidate method, it has a gain of 2.1% and 3.2% in terms of P$@$0.5 on the former two, respectively, while it has a gain of 2.9% in terms of $\mathcal{J}$ on the latter one.
Efficient Long-Short Temporal Attention Network for Unsupervised Video Object Segmentation
Sep 21, 2023Unsupervised Video Object Segmentation (VOS) aims at identifying the contours of primary foreground objects in videos without any prior knowledge. However, previous methods do not fully use spatial-temporal context and fail to tackle this challenging task in real-time. This motivates us to develop an efficient Long-Short Temporal Attention network (termed LSTA) for unsupervised VOS task from a holistic view. Specifically, LSTA consists of two dominant modules, i.e., Long Temporal Memory and Short Temporal Attention. The former captures the long-term global pixel relations of the past frames and the current frame, which models constantly present objects by encoding appearance pattern. Meanwhile, the latter reveals the short-term local pixel relations of one nearby frame and the current frame, which models moving objects by encoding motion pattern. To speedup the inference, the efficient projection and the locality-based sliding window are adopted to achieve nearly linear time complexity for the two light modules, respectively. Extensive empirical studies on several benchmarks have demonstrated promising performances of the proposed method with high efficiency.
Fast Fourier Inception Networks for Occluded Video Prediction
Jun 17, 2023Video prediction is a pixel-level task that generates future frames by employing the historical frames. There often exist continuous complex motions, such as object overlapping and scene occlusion in video, which poses great challenges to this task. Previous works either fail to well capture the long-term temporal dynamics or do not handle the occlusion masks. To address these issues, we develop the fully convolutional Fast Fourier Inception Networks for video prediction, termed \textit{FFINet}, which includes two primary components, \ie, the occlusion inpainter and the spatiotemporal translator. The former adopts the fast Fourier convolutions to enlarge the receptive field, such that the missing areas (occlusion) with complex geometric structures are filled by the inpainter. The latter employs the stacked Fourier transform inception module to learn the temporal evolution by group convolutions and the spatial movement by channel-wise Fourier convolutions, which captures both the local and the global spatiotemporal features. This encourages generating more realistic and high-quality future frames. To optimize the model, the recovery loss is imposed to the objective, \ie, minimizing the mean square error between the ground-truth frame and the recovery frame. Both quantitative and qualitative experimental results on five benchmarks, including Moving MNIST, TaxiBJ, Human3.6M, Caltech Pedestrian, and KTH, have demonstrated the superiority of the proposed approach. Our code is available at GitHub.
Residual Spatial Fusion Network for RGB-Thermal Semantic Segmentation
Jun 17, 2023Semantic segmentation plays an important role in widespread applications such as autonomous driving and robotic sensing. Traditional methods mostly use RGB images which are heavily affected by lighting conditions, \eg, darkness. Recent studies show thermal images are robust to the night scenario as a compensating modality for segmentation. However, existing works either simply fuse RGB-Thermal (RGB-T) images or adopt the encoder with the same structure for both the RGB stream and the thermal stream, which neglects the modality difference in segmentation under varying lighting conditions. Therefore, this work proposes a Residual Spatial Fusion Network (RSFNet) for RGB-T semantic segmentation. Specifically, we employ an asymmetric encoder to learn the compensating features of the RGB and the thermal images. To effectively fuse the dual-modality features, we generate the pseudo-labels by saliency detection to supervise the feature learning, and develop the Residual Spatial Fusion (RSF) module with structural re-parameterization to learn more promising features by spatially fusing the cross-modality features. RSF employs a hierarchical feature fusion to aggregate multi-level features, and applies the spatial weights with the residual connection to adaptively control the multi-spectral feature fusion by the confidence gate. Extensive experiments were carried out on two benchmarks, \ie, MFNet database and PST900 database. The results have shown the state-of-the-art segmentation performance of our method, which achieves a good balance between accuracy and speed.
Exploring global diverse attention via pairwise temporal relation for video summarization
Sep 23, 2020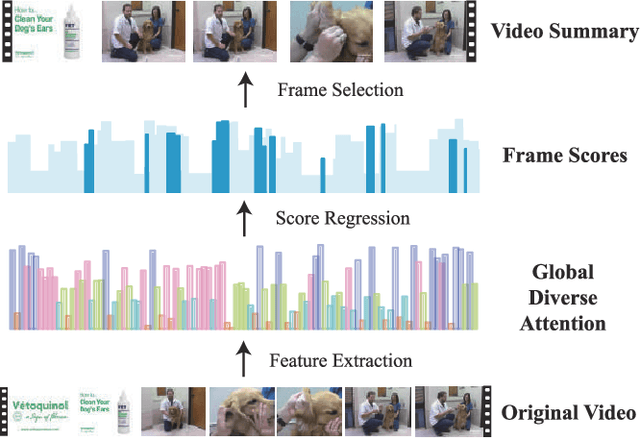
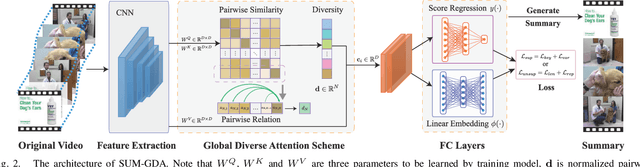
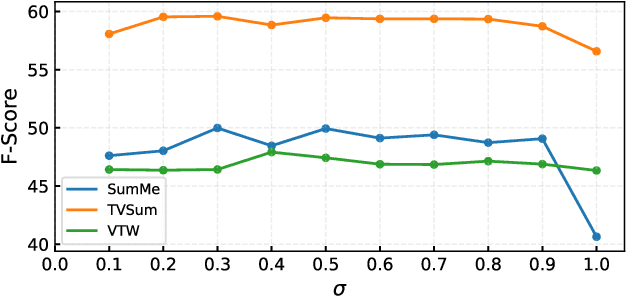
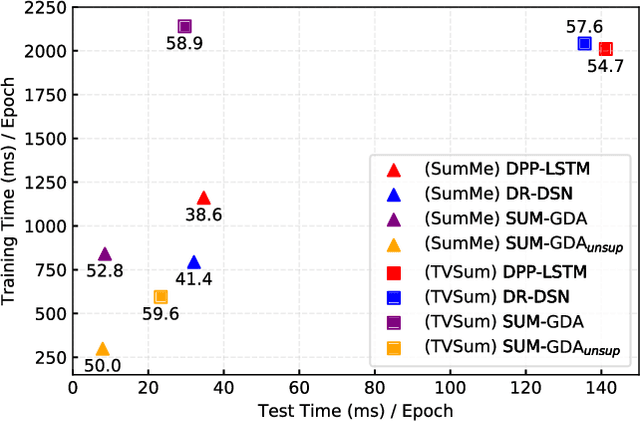
Video summarization is an effective way to facilitate video searching and browsing. Most of existing systems employ encoder-decoder based recurrent neural networks, which fail to explicitly diversify the system-generated summary frames while requiring intensive computations. In this paper, we propose an efficient convolutional neural network architecture for video SUMmarization via Global Diverse Attention called SUM-GDA, which adapts attention mechanism in a global perspective to consider pairwise temporal relations of video frames. Particularly, the GDA module has two advantages: 1) it models the relations within paired frames as well as the relations among all pairs, thus capturing the global attention across all frames of one video; 2) it reflects the importance of each frame to the whole video, leading to diverse attention on these frames. Thus, SUM-GDA is beneficial for generating diverse frames to form satisfactory video summary. Extensive experiments on three data sets, i.e., SumMe, TVSum, and VTW, have demonstrated that SUM-GDA and its extension outperform other competing state-of-the-art methods with remarkable improvements. In addition, the proposed models can be run in parallel with significantly less computational costs, which helps the deployment in highly demanding applications.
* 12 pages, 8 figures