 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment and Caption Anything
Dec 01, 2023



We propose a method to efficiently equip the Segment Anything Model (SAM) with the ability to generate regional captions. SAM presents strong generalizability to segment anything while is short for semantic understanding. By introducing a lightweight query-based feature mixer, we align the region-specific features with the embedding space of language models for later caption generation. As the number of trainable parameters is small (typically in the order of tens of millions), it costs less computation, less memory usage, and less communication bandwidth, resulting in both fast and scalable training. To address the scarcity problem of regional caption data, we propose to first pre-train our model on objection detection and segmentation tasks. We call this step weak supervision pretraining since the pre-training data only contains category names instead of full-sentence descriptions. The weak supervision pretraining allows us to leverage many publicly available object detection and segmentation datasets. We conduct extensive experiments to demonstrate the superiority of our method and validate each design choice. This work serves as a stepping stone towards scaling up regional captioning data and sheds light on exploring efficient ways to augment SAM with regional semantics. The project page, along with the associated code, can be accessed via the following https://xk-huang.github.io/segment-caption-anything/.
MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning
Nov 29, 2023
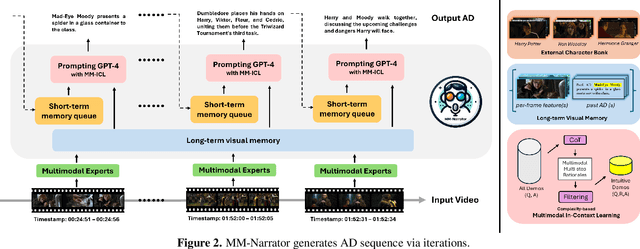


We present MM-Narrator, a novel system leveraging GPT-4 with multimodal in-context learning for the generation of audio descriptions (AD). Unlike previous methods that primarily focused on downstream fine-tuning with short video clips, MM-Narrator excels in generating precise audio descriptions for videos of extensive lengths, even beyond hours, in an autoregressive manner. This capability is made possible by the proposed memory-augmented generation process, which effectively utilizes both the short-term textual context and long-term visual memory through an efficient register-and-recall mechanism. These contextual memories compile pertinent past information, including storylines and character identities, ensuring an accurate tracking and depicting of story-coherent and character-centric audio descriptions. Maintaining the training-free design of MM-Narrator, we further propose a complexity-based demonstration selection strategy to largely enhance its multi-step reasoning capability via few-shot multimodal in-context learning (MM-ICL). Experimental results on MAD-eval dataset demonstrate that MM-Narrator consistently outperforms both the existing fine-tuning-based approaches and LLM-based approaches in most scenarios, as measured by standard evaluation metrics. Additionally, we introduce the first segment-based evaluator for recurrent text generation. Empowered by GPT-4, this evaluator comprehensively reasons and marks AD generation performance in various extendable dimensions.
GPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation
Nov 13, 2023



We present MM-Navigator, a GPT-4V-based agent for the smartphone graphical user interface (GUI) navigation task. MM-Navigator can interact with a smartphone screen as human users, and determine subsequent actions to fulfill given instructions. Our findings demonstrate that large multimodal models (LMMs), specifically GPT-4V, excel in zero-shot GUI navigation through its advanced screen interpretation, action reasoning, and precise action localization capabilities. We first benchmark MM-Navigator on our collected iOS screen dataset. According to human assessments, the system exhibited a 91\% accuracy rate in generating reasonable action descriptions and a 75\% accuracy rate in executing the correct actions for single-step instructions on iOS. Additionally, we evaluate the model on a subset of an Android screen navigation dataset, where the model outperforms previous GUI navigators in a zero-shot fashion. Our benchmark and detailed analyses aim to lay a robust groundwork for future research into the GUI navigation task. The project page is at https://github.com/zzxslp/MM-Navigator.
MM-VID: Advancing Video Understanding with GPT-4V
Oct 30, 2023



We present MM-VID, an integrated system that harnesses the capabilities of GPT-4V, combined with specialized tools in vision, audio, and speech, to facilitate advanced video understanding. MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. Experimental results demonstrate the effectiveness of MM-VID in handling distinct video genres with various video lengths. Additionally, we showcase its potential when applied to interactive environments, such as video games and graphic user interfaces.
On the Hidden Waves of Image
Oct 19, 2023



In this paper, we introduce an intriguing phenomenon-the successful reconstruction of images using a set of one-way wave equations with hidden and learnable speeds. Each individual image corresponds to a solution with a unique initial condition, which can be computed from the original image using a visual encoder (e.g., a convolutional neural network). Furthermore, the solution for each image exhibits two noteworthy mathematical properties: (a) it can be decomposed into a collection of special solutions of the same one-way wave equations that are first-order autoregressive, with shared coefficient matrices for autoregression, and (b) the product of these coefficient matrices forms a diagonal matrix with the speeds of the wave equations as its diagonal elements. We term this phenomenon hidden waves, as it reveals that, although the speeds of the set of wave equations and autoregressive coefficient matrices are latent, they are both learnable and shared across images. This represents a mathematical invariance across images, providing a new mathematical perspective to understand images.
Idea2Img: Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation
Oct 12, 2023We introduce ``Idea to Image,'' a system that enables multimodal iterative self-refinement with GPT-4V(ision) for automatic image design and generation. Humans can quickly identify the characteristics of different text-to-image (T2I) models via iterative explorations. This enables them to efficiently convert their high-level generation ideas into effective T2I prompts that can produce good images. We investigate if systems based on large multimodal models (LMMs) can develop analogous multimodal self-refinement abilities that enable exploring unknown models or environments via self-refining tries. Idea2Img cyclically generates revised T2I prompts to synthesize draft images, and provides directional feedback for prompt revision, both conditioned on its memory of the probed T2I model's characteristics. The iterative self-refinement brings Idea2Img various advantages over vanilla T2I models. Notably, Idea2Img can process input ideas with interleaved image-text sequences, follow ideas with design instructions, and generate images of better semantic and visual qualities. The user preference study validates the efficacy of multimodal iterative self-refinement on automatic image design and generation.
OpenLEAF: Open-Domain Interleaved Image-Text Generation and Evaluation
Oct 11, 2023



This work investigates a challenging task named open-domain interleaved image-text generation, which generates interleaved texts and images following an input query. We propose a new interleaved generation framework based on prompting large-language models (LLMs) and pre-trained text-to-image (T2I) models, namely OpenLEAF. In OpenLEAF, the LLM generates textual descriptions, coordinates T2I models, creates visual prompts for generating images, and incorporates global contexts into the T2I models. This global context improves the entity and style consistencies of images in the interleaved generation. For model assessment, we first propose to use large multi-modal models (LMMs) to evaluate the entity and style consistencies of open-domain interleaved image-text sequences. According to the LMM evaluation on our constructed evaluation set, the proposed interleaved generation framework can generate high-quality image-text content for various domains and applications, such as how-to question answering, storytelling, graphical story rewriting, and webpage/poster generation tasks. Moreover, we validate the effectiveness of the proposed LMM evaluation technique with human assessment. We hope our proposed framework, benchmark, and LMM evaluation could help establish the intriguing interleaved image-text generation task.
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Oct 11, 2023Large multimodal models (LMMs) extend large language models (LLMs) with multi-sensory skills, such as visual understanding, to achieve stronger generic intelligence. In this paper, we analyze the latest model, GPT-4V(ision), to deepen the understanding of LMMs. The analysis focuses on the intriguing tasks that GPT-4V can perform, containing test samples to probe the quality and genericity of GPT-4V's capabilities, its supported inputs and working modes, and the effective ways to prompt the model. In our approach to exploring GPT-4V, we curate and organize a collection of carefully designed qualitative samples spanning a variety of domains and tasks. Observations from these samples demonstrate that GPT-4V's unprecedented ability in processing arbitrarily interleaved multimodal inputs and the genericity of its capabilities together make GPT-4V a powerful multimodal generalist system. Furthermore, GPT-4V's unique capability of understanding visual markers drawn on input images can give rise to new human-computer interaction methods such as visual referring prompting. We conclude the report with in-depth discussions on the emerging application scenarios and the future research directions for GPT-4V-based systems. We hope that this preliminary exploration will inspire future research on the next-generation multimodal task formulation, new ways to exploit and enhance LMMs to solve real-world problems, and gaining better understanding of multimodal foundation models. Finally, we acknowledge that the model under our study is solely the product of OpenAI's innovative work, and they should be fully credited for its development. Please see the GPT-4V contributions paper for the authorship and credit attribution: https://cdn.openai.com/contributions/gpt-4v.pdf
SemiReward: A General Reward Model for Semi-supervised Learning
Oct 04, 2023



Semi-supervised learning (SSL) has witnessed great progress with various improvements in the self-training framework with pseudo labeling. The main challenge is how to distinguish high-quality pseudo labels against the confirmation bias. However, existing pseudo-label selection strategies are limited to pre-defined schemes or complex hand-crafted policies specially designed for classification, failing to achieve high-quality labels, fast convergence, and task versatility simultaneously. To these ends, we propose a Semi-supervised Reward framework (SemiReward) that predicts reward scores to evaluate and filter out high-quality pseudo labels, which is pluggable to mainstream SSL methods in wide task types and scenarios. To mitigate confirmation bias, SemiReward is trained online in two stages with a generator model and subsampling strategy. With classification and regression tasks on 13 standard SSL benchmarks of three modalities, extensive experiments verify that SemiReward achieves significant performance gains and faster convergence speeds upon Pseudo Label, FlexMatch, and Free/SoftMatch.
Completing Visual Objects via Bridging Generation and Segmentation
Oct 01, 2023



This paper presents a novel approach to object completion, with the primary goal of reconstructing a complete object from its partially visible components. Our method, named MaskComp, delineates the completion process through iterative stages of generation and segmentation. In each iteration, the object mask is provided as an additional condition to boost image generation, and, in return, the generated images can lead to a more accurate mask by fusing the segmentation of images. We demonstrate that the combination of one generation and one segmentation stage effectively functions as a mask denoiser. Through alternation between the generation and segmentation stages, the partial object mask is progressively refined, providing precise shape guidance and yielding superior object completion results. Our experiments demonstrate the superiority of MaskComp over existing approaches, e.g., ControlNet and Stable Diffusion, establishing it as an effective solution for object completion.