 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta-CoMe: Training-Free Delta-Compression with Mixed-Precision for Large Language Models
Jun 13, 2024



Fine-tuning is a crucial process for adapting large language models (LLMs) to diverse applications. In certain scenarios, such as multi-tenant serving, deploying multiple LLMs becomes necessary to meet complex demands. Recent studies suggest decomposing a fine-tuned LLM into a base model and corresponding delta weights, which are then compressed using low-rank or low-bit approaches to reduce costs. In this work, we observe that existing low-rank and low-bit compression methods can significantly harm the model performance for task-specific fine-tuned LLMs (e.g., WizardMath for math problems). Motivated by the long-tail distribution of singular values in the delta weights, we propose a delta quantization approach using mixed-precision. This method employs higher-bit representation for singular vectors corresponding to larger singular values. We evaluate our approach on various fine-tuned LLMs, including math LLMs, code LLMs, chat LLMs, and even VLMs. Experimental results demonstrate that our approach performs comparably to full fine-tuned LLMs, surpassing both low-rank and low-bit baselines by a considerable margin. Additionally, we show that our method is compatible with various backbone LLMs, such as Llama-2, Llama-3, and Mistral, highlighting its generalizability.
Scaling Large-Language-Model-based Multi-Agent Collaboration
Jun 11, 2024



Pioneering advancements in large language model-powered agents have underscored the design pattern of multi-agent collaboration, demonstrating that collective intelligence can surpass the capabilities of each individual. Inspired by the neural scaling law, which posits that increasing neurons leads to emergent abilities, this study investigates whether a similar principle applies to increasing agents in multi-agent collaboration. Technically, we propose multi-agent collaboration networks (MacNet), which utilize directed acyclic graphs to organize agents and streamline their interactive reasoning via topological ordering, with solutions derived from their dialogues. Extensive experiments show that MacNet consistently outperforms baseline models, enabling effective agent collaboration across various network topologies and supporting cooperation among more than a thousand agents. Notably, we observed a small-world collaboration phenomenon, where topologies resembling small-world properties achieved superior performance. Additionally, we identified a collaborative scaling law, indicating that normalized solution quality follows a logistic growth pattern as scaling agents, with collaborative emergence occurring much earlier than previously observed instances of neural emergence. The code and data will be available at https://github.com/OpenBMB/ChatDev.
Revisiting Non-Autoregressive Transformers for Efficient Image Synthesis
Jun 08, 2024



The field of image synthesis is currently flourishing due to the advancements in diffusion models. While diffusion models have been successful, their computational intensity has prompted the pursuit of more efficient alternatives. As a representative work, non-autoregressive Transformers (NATs) have been recognized for their rapid generation. However, a major drawback of these models is their inferior performance compared to diffusion models. In this paper, we aim to re-evaluate the full potential of NATs by revisiting the design of their training and inference strategies. Specifically, we identify the complexities in properly configuring these strategies and indicate the possible sub-optimality in existing heuristic-driven designs. Recognizing this, we propose to go beyond existing methods by directly solving the optimal strategies in an automatic framework. The resulting method, named AutoNAT, advances the performance boundaries of NATs notably, and is able to perform comparably with the latest diffusion models at a significantly reduced inference cost. The effectiveness of AutoNAT is validated on four benchmark datasets, i.e., ImageNet-256 & 512, MS-COCO, and CC3M. Our code is available at https://github.com/LeapLabTHU/ImprovedNAT.
UltraMedical: Building Specialized Generalists in Biomedicine
Jun 06, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains and are moving towards more specialized areas. Recent advanced proprietary models such as GPT-4 and Gemini have achieved significant advancements in biomedicine, which have also raised privacy and security challenges. The construction of specialized generalists hinges largely on high-quality datasets, enhanced by techniques like supervised fine-tuning and reinforcement learning from human or AI feedback, and direct preference optimization. However, these leading technologies (e.g., preference learning) are still significantly limited in the open source community due to the scarcity of specialized data. In this paper, we present the UltraMedical collections, which consist of high-quality manual and synthetic datasets in the biomedicine domain, featuring preference annotations across multiple advanced LLMs. By utilizing these datasets, we fine-tune a suite of specialized medical models based on Llama-3 series, demonstrating breathtaking capabilities across various medical benchmarks. Moreover, we develop powerful reward models skilled in biomedical and general reward benchmark, enhancing further online preference learning within the biomedical LLM community.
RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness
May 27, 2024



Learning from feedback reduces the hallucination of multimodal large language models (MLLMs) by aligning them with human preferences. While traditional methods rely on labor-intensive and time-consuming manual labeling, recent approaches employing models as automatic labelers have shown promising results without human intervention. However, these methods heavily rely on costly proprietary models like GPT-4V, resulting in scalability issues. Moreover, this paradigm essentially distills the proprietary models to provide a temporary solution to quickly bridge the performance gap. As this gap continues to shrink, the community is soon facing the essential challenge of aligning MLLMs using labeler models of comparable capability. In this work, we introduce RLAIF-V, a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. RLAIF-V maximally exploits the open-source feedback from two perspectives, including high-quality feedback data and online feedback learning algorithm. Extensive experiments on seven benchmarks in both automatic and human evaluation show that RLAIF-V substantially enhances the trustworthiness of models without sacrificing performance on other tasks. Using a 34B model as labeler, RLAIF-V 7B model reduces object hallucination by 82.9\% and overall hallucination by 42.1\%, outperforming the labeler model. Remarkably, RLAIF-V also reveals the self-alignment potential of open-source MLLMs, where a 12B model can learn from the feedback of itself to achieve less than 29.5\% overall hallucination rate, surpassing GPT-4V (45.9\%) by a large margin. The results shed light on a promising route to enhance the efficacy of leading-edge MLLMs.
ReactXT: Understanding Molecular "Reaction-ship" via Reaction-Contextualized Molecule-Text Pretraining
May 23, 2024



Molecule-text modeling, which aims to facilitate molecule-relevant tasks with a textual interface and textual knowledge, is an emerging research direction. Beyond single molecules, studying reaction-text modeling holds promise for helping the synthesis of new materials and drugs. However, previous works mostly neglect reaction-text modeling: they primarily focus on modeling individual molecule-text pairs or learning chemical reactions without texts in context. Additionally, one key task of reaction-text modeling -- experimental procedure prediction -- is less explored due to the absence of an open-source dataset. The task is to predict step-by-step actions of conducting chemical experiments and is crucial to automating chemical synthesis. To resolve the challenges above, we propose a new pretraining method, ReactXT, for reaction-text modeling, and a new dataset, OpenExp, for experimental procedure prediction. Specifically, ReactXT features three types of input contexts to incrementally pretrain LMs. Each of the three input contexts corresponds to a pretraining task to improve the text-based understanding of either reactions or single molecules. ReactXT demonstrates consistent improvements in experimental procedure prediction and molecule captioning and offers competitive results in retrosynthesis. Our code is available at https://github.com/syr-cn/ReactXT.
ProtT3: Protein-to-Text Generation for Text-based Protein Understanding
May 21, 2024


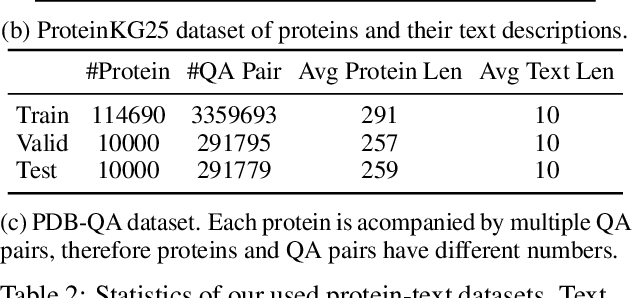
Language Models (LMs) excel in understanding textual descriptions of proteins, as evident in biomedical question-answering tasks. However, their capability falters with raw protein data, such as amino acid sequences, due to a deficit in pretraining on such data. Conversely, Protein Language Models (PLMs) can understand and convert protein data into high-quality representations, but struggle to process texts. To address their limitations, we introduce ProtT3, a framework for Protein-to-Text Generation for Text-based Protein Understanding. ProtT3 empowers an LM to understand protein sequences of amino acids by incorporating a PLM as its protein understanding module, enabling effective protein-to-text generation. This collaboration between PLM and LM is facilitated by a cross-modal projector (i.e., Q-Former) that bridges the modality gap between the PLM's representation space and the LM's input space. Unlike previous studies focusing on protein property prediction and protein-text retrieval, we delve into the largely unexplored field of protein-to-text generation. To facilitate comprehensive benchmarks and promote future research, we establish quantitative evaluations for protein-text modeling tasks, including protein captioning, protein question-answering, and protein-text retrieval. Our experiments show that ProtT3 substantially surpasses current baselines, with ablation studies further highlighting the efficacy of its core components. Our code is available at https://github.com/acharkq/ProtT3.
Iterative Experience Refinement of Software-Developing Agents
May 07, 2024



Autonomous agents powered by large language models (LLMs) show significant potential for achieving high autonomy in various scenarios such as software development. Recent research has shown that LLM agents can leverage past experiences to reduce errors and enhance efficiency. However, the static experience paradigm, reliant on a fixed collection of past experiences acquired heuristically, lacks iterative refinement and thus hampers agents' adaptability. In this paper, we introduce the Iterative Experience Refinement framework, enabling LLM agents to refine experiences iteratively during task execution. We propose two fundamental patterns: the successive pattern, refining based on nearest experiences within a task batch, and the cumulative pattern, acquiring experiences across all previous task batches. Augmented with our heuristic experience elimination, the method prioritizes high-quality and frequently-used experiences, effectively managing the experience space and enhancing efficiency. Extensive experiments show that while the successive pattern may yield superior results, the cumulative pattern provides more stable performance. Moreover, experience elimination facilitates achieving better performance using just 11.54% of a high-quality subset.
LEGENT: Open Platform for Embodied Agents
Apr 28, 2024



Despite advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), their integration into language-grounded, human-like embodied agents remains incomplete, hindering complex real-life task performance in physical environments. Existing integrations often feature limited open sourcing, challenging collective progress in this field. We introduce LEGENT, an open, scalable platform for developing embodied agents using LLMs and LMMs. LEGENT offers a dual approach: a rich, interactive 3D environment with communicable and actionable agents, paired with a user-friendly interface, and a sophisticated data generation pipeline utilizing advanced algorithms to exploit supervision from simulated worlds at scale. In our experiments, an embryonic vision-language-action model trained on LEGENT-generated data surpasses GPT-4V in embodied tasks, showcasing promising generalization capabilities.
PreGSU-A Generalized Traffic Scene Understanding Model for Autonomous Driving based on Pre-trained Graph Attention Network
Apr 16, 2024



Scene understanding, defined as learning, extraction, and representation of interactions among traffic elements, is one of the critical challenges toward high-level autonomous driving (AD). Current scene understanding methods mainly focus on one concrete single task, such as trajectory prediction and risk level evaluation. Although they perform well on specific metrics, the generalization ability is insufficient to adapt to the real traffic complexity and downstream demand diversity. In this study, we propose PreGSU, a generalized pre-trained scene understanding model based on graph attention network to learn the universal interaction and reasoning of traffic scenes to support various downstream tasks. After the feature engineering and sub-graph module, all elements are embedded as nodes to form a dynamic weighted graph. Then, four graph attention layers are applied to learn the relationships among agents and lanes. In the pre-train phase, the understanding model is trained on two self-supervised tasks: Virtual Interaction Force (VIF) modeling and Masked Road Modeling (MRM). Based on the artificial potential field theory, VIF modeling enables PreGSU to capture the agent-to-agent interactions while MRM extracts agent-to-road connections. In the fine-tuning process, the pre-trained parameters are loaded to derive detailed understanding outputs. We conduct validation experiments on two downstream tasks, i.e., trajectory prediction in urban scenario, and intention recognition in highway scenario, to verify the generalized ability and understanding ability. Results show that compared with the baselines, PreGSU achieves better accuracy on both tasks, indicating the potential to be generalized to various scenes and targets. Ablation study shows the effectiveness of pre-train task design.