 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCauTion: Knowing When to Trust LLMs for Ensemble Causal Discovery
Jun 02, 2026Causal discovery from observational data remains challenging due to the fundamental limitations of purely statistical methods, such as statistical distinguishability within equivalence classes and sensitivity to finite sample sizes. While large language models (LLMs) offer a promising source of domain knowledge to complement statistical inference, existing LLM-augmented methods are vulnerable to LLM errors and incur high token costs. Moreover, reliance on a single data-centric algorithm can make results sensitive to algorithm-specific biases. To address these limitations, we propose CauTion, a framework that reliably integrates LLM domain knowledge into an ensemble of statistical causal discovery algorithms through consensus filtering and LLM reliability estimation. CauTion proceeds in three stages. First, an algorithm ensemble utilizes a consensus voting to resolve up to 96% of edges on which algorithms agree, achieving near-perfect accuracy on the filtered consensus edges. Second, a trust-calibrated arbitration mechanism estimates the relative reliability of the LLM and the algorithms via an annotation-free trust calibration procedure, which is then utilized to govern a trust-weighted voting process that restricts LLM arbitration exclusively to edges with unreliable algorithmic evidence. Third, a cycle repair step is applied to guarantee the final causal graph is validly acyclic. Experiments on six datasets demonstrate that CauTion consistently outperforms both data-centric and LLM-augmented baselines, with larger gains on larger graphs and strong robustness to LLM errors. Code is available at https://github.com/OpenCausaLab/CauTion.
Visual-Advantage On-Policy Distillation for Vision-Language Models
May 21, 2026On-policy knowledge distillation has proven effective for language models, yet its application to vision-language models (VLMs) remains underexplored. We observe that standard on-policy distillation can improve a student's output quality while failing to strengthen its reliance on visual input: on vision-critical tokens, the student's predictions remain largely unchanged whether or not fine-grained visual detail is present, even though the teacher's predictions depend heavily on it.To make this difference observable, we introduce visual advantage (VA), the token-level log-probability difference when the teacher scores a student-generated rollout with versus without access to fine-grained visual detail. VA is concentrated in a small minority of tokens, and these high-VA tokens are the ones that actually carry the visual supervision signal. This motivates a distillation objective that treats them differently from language scaffolding, so their contribution is not diluted by the abundant surrounding language tokens.We propose Visual-Advantage On-Policy Distillation (VA-OPD), which uses VA at two granularities: rollout-level reweighting by trajectory-averaged VA, and token-level KL averaged within high-VA and low-VA groups separately. We train on two math datasets (Geometry3K and ViRL39K) and evaluate on eight benchmarks covering both mathematical reasoning and visual understanding, across three teacher sizes (4B, 8B, and 32B) on the Qwen3-VL family. VA-OPD improves over standard on-policy distillation on every benchmark, with the gain growing monotonically along both the teacher-size and data-scale axes, suggesting that these factors compound consistently.
Self-Contradiction as Self-Improvement: Mitigating the Generation-Understanding Gap in MLLMs
Jul 22, 2025



Despite efforts to unify multimodal generation and understanding tasks in a single model, we show these MLLMs exhibit self-contradiction where generation produces images deemed misaligned with input prompts based on the model's own understanding. We define a Nonunified score that quantifies such self-contradiction. Our empirical results reveal that the self-contradiction mainly arises from weak generation that fails to align with prompts, rather than misunderstanding. This capability asymmetry indicates the potential of leveraging self-contradiction for self-improvement, where the stronger model understanding guides the weaker generation to mitigate the generation-understanding gap. Applying standard post-training methods (e.g., SFT, DPO) with such internal supervision successfully improves both generation and unification. We discover a co-improvement effect on both generation and understanding when only fine-tuning the generation branch, a phenomenon known in pre-training but underexplored in post-training. Our analysis shows improvements stem from better detection of false positives that are previously incorrectly identified as prompt-aligned. Theoretically, we show the aligned training dynamics between generation and understanding allow reduced prompt-misaligned generations to also improve mismatch detection in the understanding branch. Additionally, the framework reveals a potential risk of co-degradation under poor supervision-an overlooked phenomenon that is empirically validated in our experiments. Notably, we find intrinsic metrics like Nonunified score cannot distinguish co-degradation from co-improvement, which highlights the necessity of data quality check. Finally, we propose a curriculum-based strategy based on our findings that gradually introduces harder samples as the model improves, leading to better unification and improved MLLM generation and understanding.
One-Shot Multilingual Font Generation Via ViT
Dec 15, 2024



Font design poses unique challenges for logographic languages like Chinese, Japanese, and Korean (CJK), where thousands of unique characters must be individually crafted. This paper introduces a novel Vision Transformer (ViT)-based model for multi-language font generation, effectively addressing the complexities of both logographic and alphabetic scripts. By leveraging ViT and pretraining with a strong visual pretext task (Masked Autoencoding, MAE), our model eliminates the need for complex design components in prior frameworks while achieving comprehensive results with enhanced generalizability. Remarkably, it can generate high-quality fonts across multiple languages for unseen, unknown, and even user-crafted characters. Additionally, we integrate a Retrieval-Augmented Guidance (RAG) module to dynamically retrieve and adapt style references, improving scalability and real-world applicability. We evaluated our approach in various font generation tasks, demonstrating its effectiveness, adaptability, and scalability.
Content Popularity Prediction in Fog-RANs: A Clustered Federated Learning Based Approach
Jun 13, 2022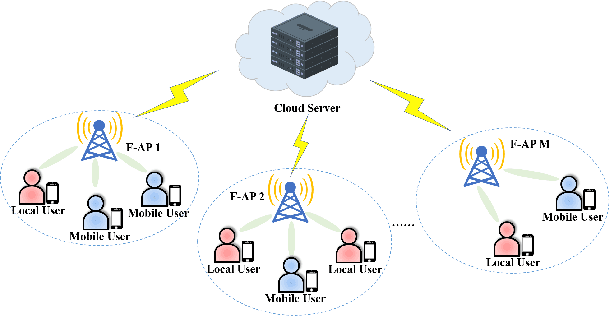
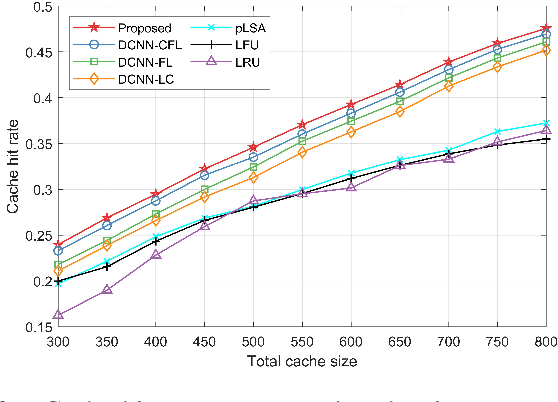
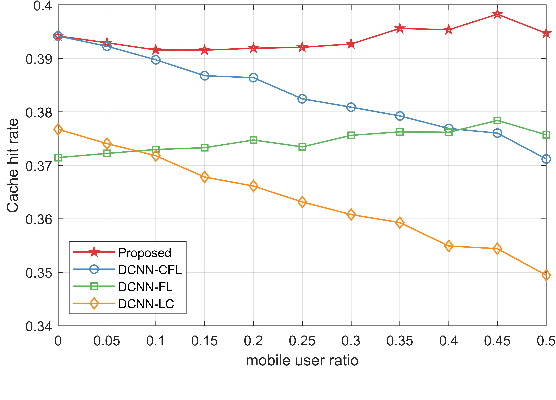
In this paper, the content popularity prediction problem in fog radio access networks (F-RANs) is investigated. Based on clustered federated learning, we propose a novel mobility-aware popularity prediction policy, which integrates content popularities in terms of local users and mobile users. For local users, the content popularity is predicted by learning the hidden representations of local users and contents. Initial features of local users and contents are generated by incorporating neighbor information with self information. Then, dual-channel neural network (DCNN) model is introduced to learn the hidden representations by producing deep latent features from initial features. For mobile users, the content popularity is predicted via user preference learning. In order to distinguish regional variations of content popularity, clustered federated learning (CFL) is employed, which enables fog access points (F-APs) with similar regional types to benefit from one another and provides a more specialized DCNN model for each F-AP. Simulation results show that our proposed policy achieves significant performance improvement over the traditional policies.
ForgeryNet -- Face Forgery Analysis Challenge 2021: Methods and Results
Dec 15, 2021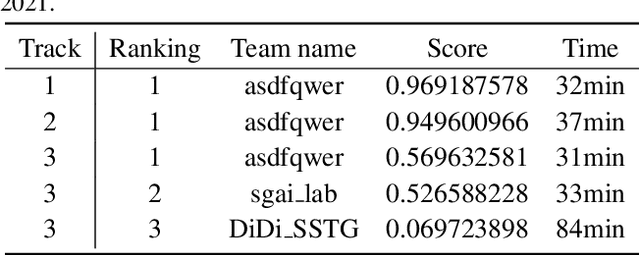
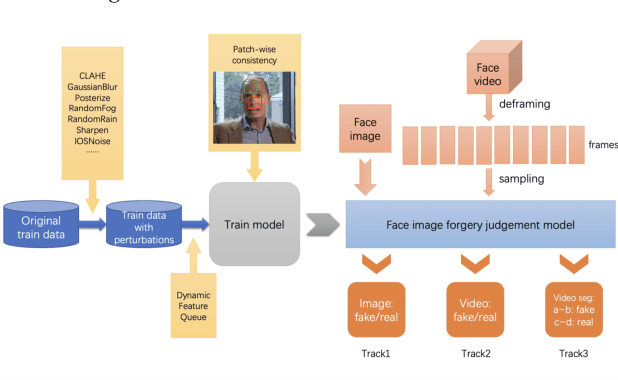
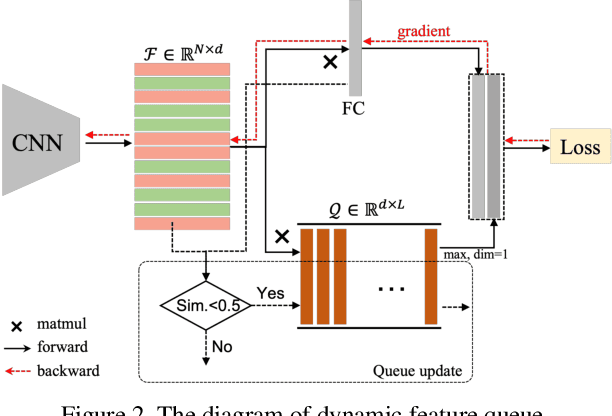
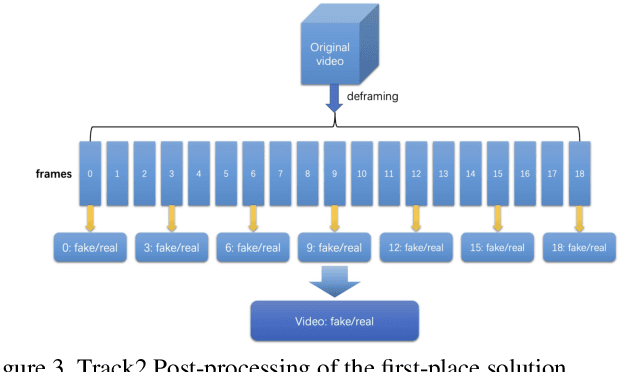
The rapid progress of photorealistic synthesis techniques has reached a critical point where the boundary between real and manipulated images starts to blur. Recently, a mega-scale deep face forgery dataset, ForgeryNet which comprised of 2.9 million images and 221,247 videos has been released. It is by far the largest publicly available in terms of data-scale, manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations), and annotations (6.3 million classification labels, 2.9 million manipulated area annotations, and 221,247 temporal forgery segment labels). This paper reports methods and results in the ForgeryNet - Face Forgery Analysis Challenge 2021, which employs the ForgeryNet benchmark. The model evaluation is conducted offline on the private test set. A total of 186 participants registered for the competition, and 11 teams made valid submissions. We will analyze the top-ranked solutions and present some discussion on future work directions.
Tips and Tricks for Webly-Supervised Fine-Grained Recognition: Learning from the WebFG 2020 Challenge
Dec 29, 2020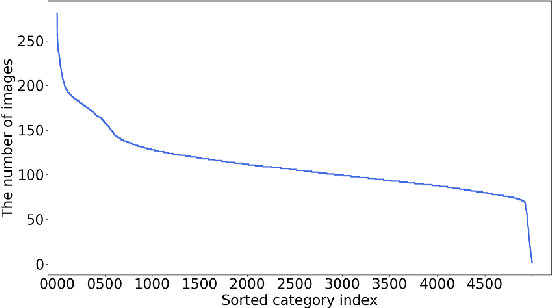
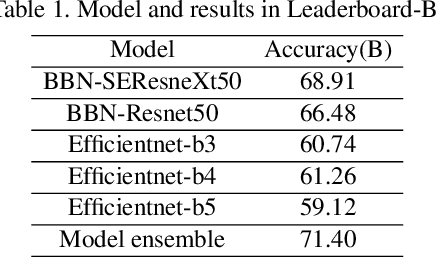

WebFG 2020 is an international challenge hosted by Nanjing University of Science and Technology, University of Edinburgh, Nanjing University, The University of Adelaide, Waseda University, etc. This challenge mainly pays attention to the webly-supervised fine-grained recognition problem. In the literature, existing deep learning methods highly rely on large-scale and high-quality labeled training data, which poses a limitation to their practicability and scalability in real world applications. In particular, for fine-grained recognition, a visual task that requires professional knowledge for labeling, the cost of acquiring labeled training data is quite high. It causes extreme difficulties to obtain a large amount of high-quality training data. Therefore, utilizing free web data to train fine-grained recognition models has attracted increasing attentions from researchers in the fine-grained community. This challenge expects participants to develop webly-supervised fine-grained recognition methods, which leverages web images in training fine-grained recognition models to ease the extreme dependence of deep learning methods on large-scale manually labeled datasets and to enhance their practicability and scalability. In this technical report, we have pulled together the top WebFG 2020 solutions of total 54 competing teams, and discuss what methods worked best across the set of winning teams, and what surprisingly did not help.
Progressive Multi-Stage Learning for Discriminative Tracking
Apr 01, 2020



Visual tracking is typically solved as a discriminative learning problem that usually requires high-quality samples for online model adaptation. It is a critical and challenging problem to evaluate the training samples collected from previous predictions and employ sample selection by their quality to train the model. To tackle the above problem, we propose a joint discriminative learning scheme with the progressive multi-stage optimization policy of sample selection for robust visual tracking. The proposed scheme presents a novel time-weighted and detection-guided self-paced learning strategy for easy-to-hard sample selection, which is capable of tolerating relatively large intra-class variations while maintaining inter-class separability. Such a self-paced learning strategy is jointly optimized in conjunction with the discriminative tracking process, resulting in robust tracking results. Experiments on the benchmark datasets demonstrate the effectiveness of the proposed learning framework.
Complete Scene Reconstruction by Merging Images and Laser Scans
May 17, 2019



Image based modeling and laser scanning are two commonly used approaches in large-scale architectural scene reconstruction nowadays. In order to generate a complete scene reconstruction, an effective way is to completely cover the scene using ground and aerial images, supplemented by laser scanning on certain regions with low texture and complicated structure. Thus, the key issue is to accurately calibrate cameras and register laser scans in a unified framework. To this end, we proposed a three-step pipeline for complete scene reconstruction by merging images and laser scans. First, images are captured around the architecture in a multi-view and multi-scale way and are feed into a structure-from-motion (SfM) pipeline to generate SfM points. Then, based on the SfM result, the laser scanning locations are automatically planned by considering textural richness, structural complexity of the scene and spatial layout of the laser scans. Finally, the images and laser scans are accurately merged in a coarse-to-fine manner. Experimental evaluations on two ancient Chinese architecture datasets demonstrate the effectiveness of our proposed complete scene reconstruction pipeline.
A Performance Evaluation of Local Features for Image Based 3D Reconstruction
Dec 14, 2017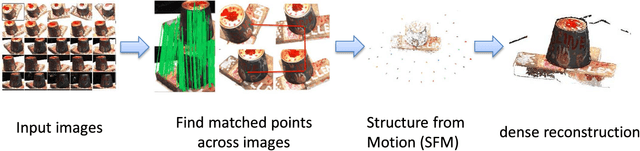

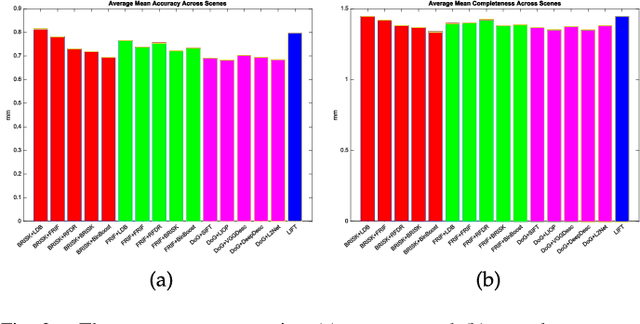
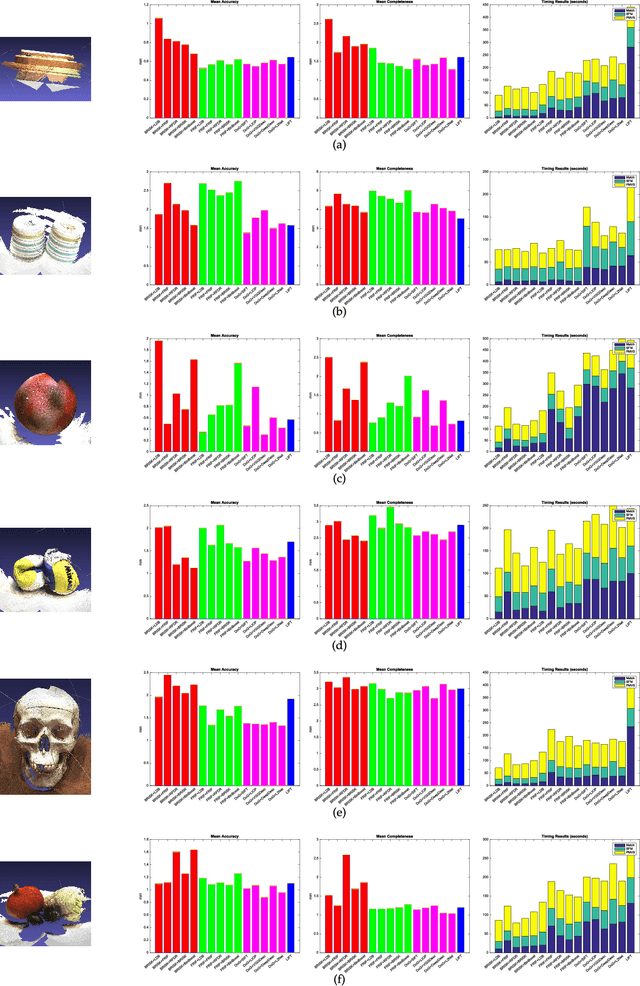
This paper performs a comprehensive and comparative evaluation of the state of the art local features for the task of image based 3D reconstruction. The evaluated local features cover the recently developed ones by using powerful machine learning techniques and the elaborately designed handcrafted features. To obtain a comprehensive evaluation, we choose to include both float type features and binary ones. Meanwhile, two kinds of datasets have been used in this evaluation. One is a dataset of many different scene types with groundtruth 3D points, containing images of different scenes captured at fixed positions, for quantitative performance evaluation of different local features in the controlled image capturing situations. The other dataset contains Internet scale image sets of several landmarks with a lot of unrelated images, which is used for qualitative performance evaluation of different local features in the free image collection situations. Our experimental results show that binary features are competent to reconstruct scenes from controlled image sequences with only a fraction of processing time compared to use float type features. However, for the case of large scale image set with many distracting images, float type features show a clear advantage over binary ones.