 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCE: A zero-cost hallucination mitigation method of LVLMs via visual contrastive editing
Apr 21, 2026Large vision-language models (LVLMs) frequently suffer from Object Hallucination (OH), wherein they generate descriptions containing objects that are not actually present in the input image. This phenomenon is particularly problematic in real-world applications such as medical imaging and autonomous driving, where accuracy is critical. Recent studies suggest that the hallucination problem may stem from language priors: biases learned during pretraining that cause LVLMs to generate words based on their statistical co-occurrence. To mitigate this problem, we propose Visual Contrastive Editing (VCE), a novel post-hoc method that identifies and suppresses hallucinatory tendencies by analyzing the model's response to contrastive visual perturbations. Using Singular Value Decomposition (SVD), we decompose the model's activation patterns to isolate hallucination subspaces and apply targeted parameter edits to attenuate its influence. Unlike existing approaches that require fine-tuning or labeled data, VCE operates as a label-free intervention, making it both scalable and practical for deployment in resource-constrained settings. Experimental results demonstrate that VCE effectively reduces object hallucination across multiple benchmarks while maintaining the model's original computational efficiency.
Boosting Robust AIGI Detection with LoRA-based Pairwise Training
Apr 14, 2026The proliferation of highly realistic AI-Generated Image (AIGI) has necessitated the development of practical detection methods. While current AIGI detectors perform admirably on clean datasets, their detection performance frequently decreases when deployed "in the wild", where images are subjected to unpredictable, complex distortions. To resolve the critical vulnerability, we propose a novel LoRA-based Pairwise Training (LPT) strategy designed specifically to achieve robust detection for AIGI under severe distortions. The core of our strategy involves the targeted finetuning of a visual foundation model, the deliberate simulation of data distribution during the training phase, and a unique pairwise training process. Specifically, we introduce distortion and size simulations to better fit the distribution from the validation and test sets. Based on the strong visual representation capability of the visual foundation model, we finetune the model to achieve AIGI detection. The pairwise training is utilized to improve the detection via decoupling the generalization and robustness optimization. Experiments show that our approach secured the 3th placement in the NTIRE Robust AI-Generated Image Detection in the Wild challenge
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
ForgeryNet -- Face Forgery Analysis Challenge 2021: Methods and Results
Dec 15, 2021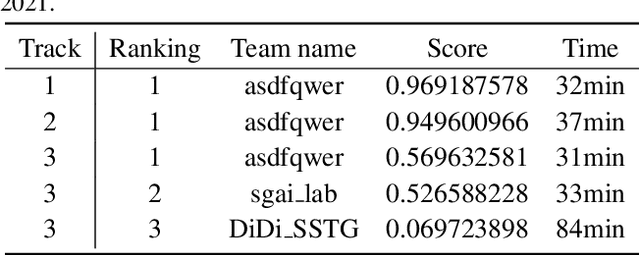
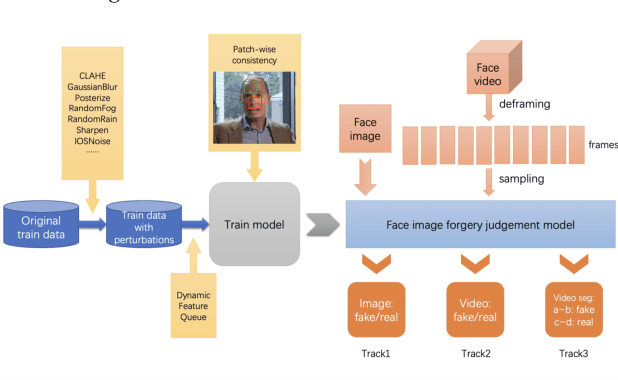
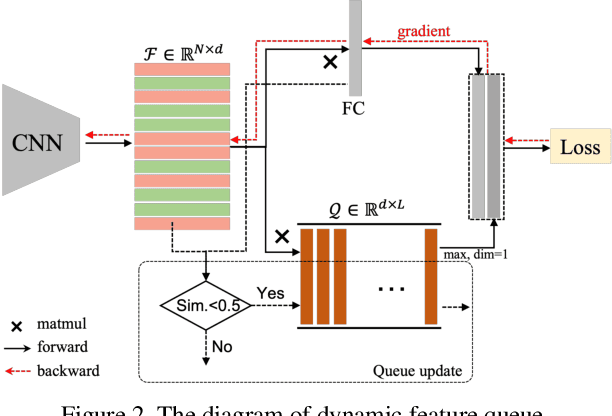
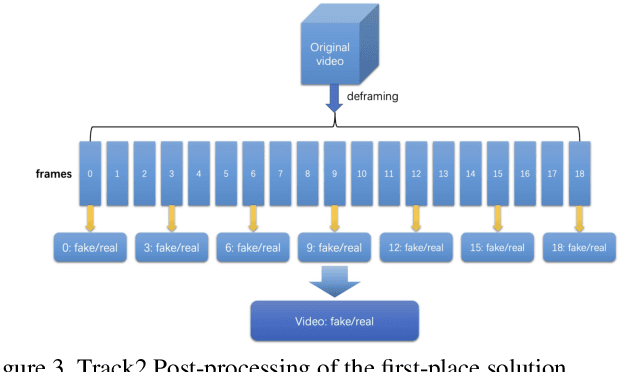
The rapid progress of photorealistic synthesis techniques has reached a critical point where the boundary between real and manipulated images starts to blur. Recently, a mega-scale deep face forgery dataset, ForgeryNet which comprised of 2.9 million images and 221,247 videos has been released. It is by far the largest publicly available in terms of data-scale, manipulations (7 image-level approaches, 8 video-level approaches), perturbations (36 independent and more mixed perturbations), and annotations (6.3 million classification labels, 2.9 million manipulated area annotations, and 221,247 temporal forgery segment labels). This paper reports methods and results in the ForgeryNet - Face Forgery Analysis Challenge 2021, which employs the ForgeryNet benchmark. The model evaluation is conducted offline on the private test set. A total of 186 participants registered for the competition, and 11 teams made valid submissions. We will analyze the top-ranked solutions and present some discussion on future work directions.