 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified MRI Brain Image Translation via Hierarchical Tumor Structure Comparison
Jun 11, 2026Multi-modal MRI brain image translation via available modalities holds significant practical importance in modern medicine, providing robust support for early diagnosis, treatment planning, and outcome assessment of diseases. For this purpose, it is important to ensure the fidelity of the tumor regions after translation. However, existing brain image translation methods ignore the structure information of different tumor regions, which could assist translation models in enhancing the quality and clinical applicability of the translated images. In this work, we propose a novel translation model called HTSCGAN, which is a unified multi-modal brain image translation generative adversarial model integrating the structural information within tumor regions with the aim of improving the quality of brain image translation. Specifically, the generator employs three Patch Contrast Module (PCM) with different patch sizes to capture the hierarchical structural information of the tumor regions. In addition, a pretrained Patch Classifier (PC) and a pretrained Structure-Aware Encoder (SAE) are employed to derive the generated image containing the same tumor region structure as the ground truth image via patch classification loss and tumor perceptual loss, respectively. The experiments on BraTS2020 and BraTS2021 demonstrate strong performance of our model in both translation tasks and down stream segmentation tasks, highlighting its effectiveness in enhancing the quality and clinical relevance of the translated brain images. Our code is available at https://anonymous.4open.science/r/HTSCGAN.
FAME: Forecastability-Aware Mixture of Experts for Heterogeneous Time Series Forecasting
Jun 08, 2026Large-scale retail and industrial forecasting systems contain many heterogeneous time series whose lifecycle, sparsity, volatility, seasonality, spectral patterns, and contextual sensitivity differ substantially. A single forecasting model rarely performs well across all regimes, while dense ensembles increase inference cost and provide limited insight into expert suitability. This paper studies forecastability-aware expert routing: learning how data characteristics determine the suitability of forecasting experts. We propose \method{}, a sparse mixture-of-experts framework that represents each series with a multidimensional forecastability fingerprint, mines expert-suitability targets from validation performance, and trains a cost-aware sparse router to activate a small budgeted set of experts for each series. Using a production-scale vending-machine sales dataset from Shandong New Beiyang (SNBC), where the forecasting component has been integrated into the replenishment-planning pipeline, together with public retail benchmarks, we show that expert suitability varies systematically across data regimes. On the industrial dataset with 5,000+ machines and 60M+ transactions, \method{} Top-2 reduces MSE by 12.4\% over the strongest single expert, LightGBM, while executing 1.92 experts per series on average. The deployed component produces demand forecasts, while inventory-oriented gains are estimated by an offline replay simulator under a fixed replenishment policy rather than by online intervention. The framework turns heterogeneous sales forecasting from heuristic model selection into data mining of forecastability patterns and expert specialization. Code is available at https://github.com/hit636/FAME
Segmentation-Assisted Brain MRI Synthesis with Cross-Image Multi-Contrast Feature Memory Bank Retrieval Augmentation
Jun 07, 2026Multi-contrast brain MRI provide complementary soft-tissue characteristics that aid in the screening and diagnosis of diseases. However, limited scanning time, image corruption and various imaging protocols often result in incomplete multi-contrast images. While current approaches excel in image synthesis, they often struggle to synthesize critical tumor regions and exploit contextual information in multi-contrast brain MRI effectively. To address this issue, we propose a synthesis-centric, segmentation-assisted closed-loop framework with retrieval augmentation synthesis. Our method overall takes a generative adversarial architecture, which aims to synthesize missing contrasts from any combination of available ones with a single model. To explicitly capture tumor semantics and focus synthesis on tumor regions, we add an auxiliary segmentation branch that predicts tumor masks and feeds them back as semantic conditioning in synthesis branch, thereby learning tumor-aware representations in the model and improving synthesis fidelity. Furthermore, we propose a dual-bank retrieval augmentation strategy. It dynamically queries two external knowledge bases, namely a tumor masks memory bank for crucial tumor context and cross-image contrast feature memory bank for global style information, to augment synthesis. Verified on two public multi-contrast magnetic resonance brain datasets: BraTs2020 and UCSF-BMSR, the proposed method is effective in handling medical brain images synthesis tasks and shows superior performance compared to previous methods. Code is available at:https://github.com/iBizzard/SSCF.git
COLLAR: Cascaded Object-Level Latent Refinement for High-Fidelity Conditional Generation
May 31, 2026Achieving high-fidelity object-level control in Diffusion Transformers remains a significant challenge despite the introduction of structural priors like depth and Canny maps. Current object-level conditional generation methods frequently suffer from visual artifacts and struggle to maintain precise control over objects within small localized regions. To address these limitations, we propose Cascaded Object-Level Latent Refinement (COLLAR), a training-free framework that progressively optimizes object-level features via the Field-of-View (FoV) expansion. First, we propose the Cross-Scale Semantic Alignment (CSSA) module to address spatial-semantic gaps by injecting object-level features into extended-FoV branches via attention mechanisms. To further optimize these features, the Cyclic Feature Injection (CFI) module introduces a reciprocal background feedback mechanism. It leverages a frequency-based adaptive strategy to selectively update the global backbone with context-aligned local information. Finally, the extended-FoV branch serves as a hub for feature optimization, ensuring that object-level features are integrated into the global generation process without compromising final image quality. Extensive experiments on the COCO-MIG and COCO-POS benchmarks demonstrate that our approach consistently outperforms state-of-the-art methods across semantic alignment, image quality, and spatial fidelity.
Prior Knowledge-enhanced Spatio-temporal Epidemic Forecasting
Feb 25, 2026Spatio-temporal epidemic forecasting is critical for public health management, yet existing methods often struggle with insensitivity to weak epidemic signals, over-simplified spatial relations, and unstable parameter estimation. To address these challenges, we propose the Spatio-Temporal priOr-aware Epidemic Predictor (STOEP), a novel hybrid framework that integrates implicit spatio-temporal priors and explicit expert priors. STOEP consists of three key components: (1) Case-aware Adjacency Learning (CAL), which dynamically adjusts mobility-based regional dependencies using historical infection patterns; (2) Space-informed Parameter Estimating (SPE), which employs learnable spatial priors to amplify weak epidemic signals; and (3) Filter-based Mechanistic Forecasting (FMF), which uses an expert-guided adaptive thresholding strategy to regularize epidemic parameters. Extensive experiments on real-world COVID-19 and influenza datasets demonstrate that STOEP outperforms the best baseline by 11.1% in RMSE. The system has been deployed at one provincial CDC in China to facilitate downstream applications.
ASGMamba: Adaptive Spectral Gating Mamba for Multivariate Time Series Forecasting
Feb 02, 2026Long-term multivariate time series forecasting (LTSF) plays a crucial role in various high-performance computing applications, including real-time energy grid management and large-scale traffic flow simulation. However, existing solutions face a dilemma: Transformer-based models suffer from quadratic complexity, limiting their scalability on long sequences, while linear State Space Models (SSMs) often struggle to distinguish valuable signals from high-frequency noise, leading to wasted state capacity. To bridge this gap, we propose ASGMamba, an efficient forecasting framework designed for resource-constrained supercomputing environments. ASGMamba integrates a lightweight Adaptive Spectral Gating (ASG) mechanism that dynamically filters noise based on local spectral energy, enabling the Mamba backbone to focus its state evolution on robust temporal dynamics. Furthermore, we introduce a hierarchical multi-scale architecture with variable-specific Node Embeddings to capture diverse physical characteristics. Extensive experiments on nine benchmarks demonstrate that ASGMamba achieves state-of-the-art accuracy. While keeping strictly $$\mathcal{O}(L)$$ complexity we significantly reduce the memory usage on long-horizon tasks, thus establishing ASGMamba as a scalable solution for high-throughput forecasting in resource limited environments.The code is available at https://github.com/hit636/ASGMamba
AWEMixer: Adaptive Wavelet-Enhanced Mixer Network for Long-Term Time Series Forecasting
Nov 06, 2025



Forecasting long-term time series in IoT environments remains a significant challenge due to the non-stationary and multi-scale characteristics of sensor signals. Furthermore, error accumulation causes a decrease in forecast quality when predicting further into the future. Traditional methods are restricted to operate in time-domain, while the global frequency information achieved by Fourier transform would be regarded as stationary signals leading to blur the temporal patterns of transient events. We propose AWEMixer, an Adaptive Wavelet-Enhanced Mixer Network including two innovative components: 1) a Frequency Router designs to utilize the global periodicity pattern achieved by Fast Fourier Transform to adaptively weight localized wavelet subband, and 2) a Coherent Gated Fusion Block to achieve selective integration of prominent frequency features with multi-scale temporal representation through cross-attention and gating mechanism, which realizes accurate time-frequency localization while remaining robust to noise. Seven public benchmarks validate that our model is more effective than recent state-of-the-art models. Specifically, our model consistently achieves performance improvement compared with transformer-based and MLP-based state-of-the-art models in long-sequence time series forecasting. Code is available at https://github.com/hit636/AWEMixer
DPANet: Dual Pyramid Attention Network for Multivariate Time Series Forecasting
Sep 18, 2025We conducted rigorous ablation studies to validate DPANet's key components (Table \ref{tab:ablation-study}). The full model consistently outperforms all variants. To test our dual-domain hypothesis, we designed two specialized versions: a Temporal-Only model (fusing two identical temporal pyramids) and a Frequency-Only model (fusing two spectral pyramids). Both variants underperformed significantly, confirming that the fusion of heterogeneous temporal and frequency information is critical. Furthermore, replacing the cross-attention mechanism with a simpler method (w/o Cross-Fusion) caused the most severe performance degradation. This result underscores that our interactive fusion block is the most essential component.
SageAttention2++: A More Efficient Implementation of SageAttention2
May 28, 2025
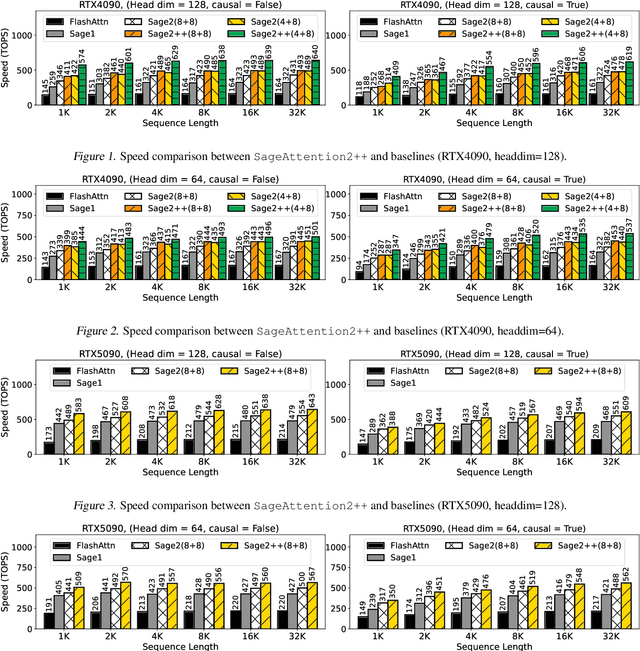
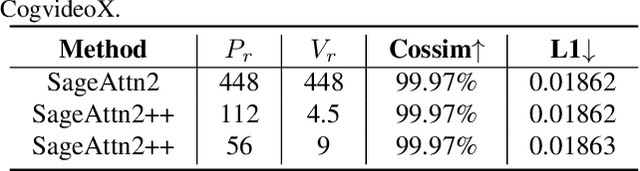
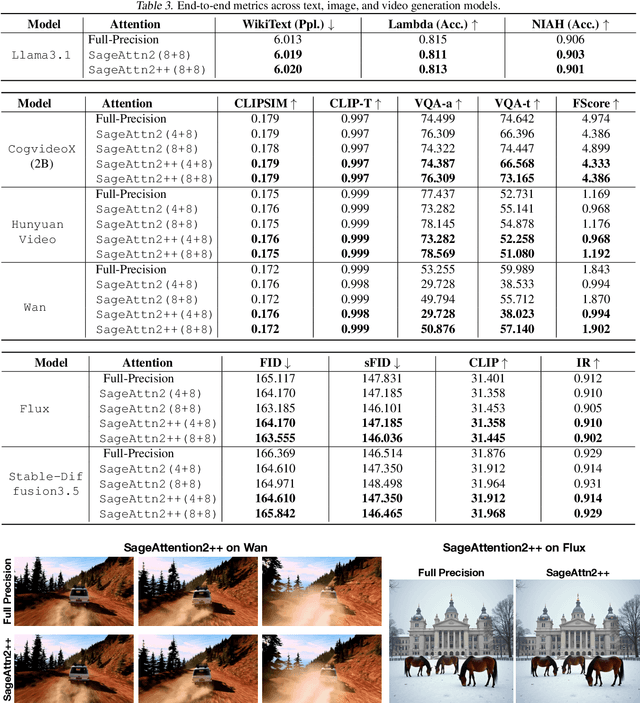
The efficiency of attention is critical because its time complexity grows quadratically with sequence length. SageAttention2 addresses this by utilizing quantization to accelerate matrix multiplications (Matmul) in attention. To further accelerate SageAttention2, we propose to utilize the faster instruction of FP8 Matmul accumulated in FP16. The instruction is 2x faster than the FP8 Matmul used in SageAttention2. Our experiments show that SageAttention2++ achieves a 3.9x speedup over FlashAttention while maintaining the same attention accuracy as SageAttention2. This means SageAttention2++ effectively accelerates various models, including those for language, image, and video generation, with negligible end-to-end metrics loss. The code will be available at https://github.com/thu-ml/SageAttention.
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
May 16, 2025The efficiency of attention is important due to its quadratic time complexity. We enhance the efficiency of attention through two key contributions: First, we leverage the new FP4 Tensor Cores in Blackwell GPUs to accelerate attention computation. Our implementation achieves 1038 TOPS on RTX5090, which is a 5x speedup over the fastest FlashAttention on RTX5090. Experiments show that our FP4 attention can accelerate inference of various models in a plug-and-play way. Second, we pioneer low-bit attention to training tasks. Existing low-bit attention works like FlashAttention3 and SageAttention focus only on inference. However, the efficiency of training large models is also important. To explore whether low-bit attention can be effectively applied to training tasks, we design an accurate and efficient 8-bit attention for both forward and backward propagation. Experiments indicate that 8-bit attention achieves lossless performance in fine-tuning tasks but exhibits slower convergence in pretraining tasks. The code will be available at https://github.com/thu-ml/SageAttention.