 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative-Competitive Team Play of Real-World Craft Robots
Feb 24, 2026Multi-agent deep Reinforcement Learning (RL) has made significant progress in developing intelligent game-playing agents in recent years. However, the efficient training of collective robots using multi-agent RL and the transfer of learned policies to real-world applications remain open research questions. In this work, we first develop a comprehensive robotic system, including simulation, distributed learning framework, and physical robot components. We then propose and evaluate reinforcement learning techniques designed for efficient training of cooperative and competitive policies on this platform. To address the challenges of multi-agent sim-to-real transfer, we introduce Out of Distribution State Initialization (OODSI) to mitigate the impact of the sim-to-real gap. In the experiments, OODSI improves the Sim2Real performance by 20%. We demonstrate the effectiveness of our approach through experiments with a multi-robot car competitive game and a cooperative task in real-world settings.
MAG-Nav: Language-Driven Object Navigation Leveraging Memory-Reserved Active Grounding
Aug 07, 2025Visual navigation in unknown environments based solely on natural language descriptions is a key capability for intelligent robots. In this work, we propose a navigation framework built upon off-the-shelf Visual Language Models (VLMs), enhanced with two human-inspired mechanisms: perspective-based active grounding, which dynamically adjusts the robot's viewpoint for improved visual inspection, and historical memory backtracking, which enables the system to retain and re-evaluate uncertain observations over time. Unlike existing approaches that passively rely on incidental visual inputs, our method actively optimizes perception and leverages memory to resolve ambiguity, significantly improving vision-language grounding in complex, unseen environments. Our framework operates in a zero-shot manner, achieving strong generalization to diverse and open-ended language descriptions without requiring labeled data or model fine-tuning. Experimental results on Habitat-Matterport 3D (HM3D) show that our method outperforms state-of-the-art approaches in language-driven object navigation. We further demonstrate its practicality through real-world deployment on a quadruped robot, achieving robust and effective navigation performance.
MinD: Unified Visual Imagination and Control via Hierarchical World Models
Jun 23, 2025



Video generation models (VGMs) offer a promising pathway for unified world modeling in robotics by integrating simulation, prediction, and manipulation. However, their practical application remains limited due to (1) slowgeneration speed, which limits real-time interaction, and (2) poor consistency between imagined videos and executable actions. To address these challenges, we propose Manipulate in Dream (MinD), a hierarchical diffusion-based world model framework that employs a dual-system design for vision-language manipulation. MinD executes VGM at low frequencies to extract video prediction features, while leveraging a high-frequency diffusion policy for real-time interaction. This architecture enables low-latency, closed-loop control in manipulation with coherent visual guidance. To better coordinate the two systems, we introduce a video-action diffusion matching module (DiffMatcher), with a novel co-training strategy that uses separate schedulers for each diffusion model. Specifically, we introduce a diffusion-forcing mechanism to DiffMatcher that aligns their intermediate representations during training, helping the fast action model better understand video-based predictions. Beyond manipulation, MinD also functions as a world simulator, reliably predicting task success or failure in latent space before execution. Trustworthy analysis further shows that VGMs can preemptively evaluate task feasibility and mitigate risks. Extensive experiments across multiple benchmarks demonstrate that MinD achieves state-of-the-art manipulation (63%+) in RL-Bench, advancing the frontier of unified world modeling in robotics.
A Novel ViDAR Device With Visual Inertial Encoder Odometry and Reinforcement Learning-Based Active SLAM Method
Jun 16, 2025In the field of multi-sensor fusion for simultaneous localization and mapping (SLAM), monocular cameras and IMUs are widely used to build simple and effective visual-inertial systems. However, limited research has explored the integration of motor-encoder devices to enhance SLAM performance. By incorporating such devices, it is possible to significantly improve active capability and field of view (FOV) with minimal additional cost and structural complexity. This paper proposes a novel visual-inertial-encoder tightly coupled odometry (VIEO) based on a ViDAR (Video Detection and Ranging) device. A ViDAR calibration method is introduced to ensure accurate initialization for VIEO. In addition, a platform motion decoupled active SLAM method based on deep reinforcement learning (DRL) is proposed. Experimental data demonstrate that the proposed ViDAR and the VIEO algorithm significantly increase cross-frame co-visibility relationships compared to its corresponding visual-inertial odometry (VIO) algorithm, improving state estimation accuracy. Additionally, the DRL-based active SLAM algorithm, with the ability to decouple from platform motion, can increase the diversity weight of the feature points and further enhance the VIEO algorithm's performance. The proposed methodology sheds fresh insights into both the updated platform design and decoupled approach of active SLAM systems in complex environments.
* 12 pages, 13 figures
VLN-Game: Vision-Language Equilibrium Search for Zero-Shot Semantic Navigation
Nov 18, 2024Following human instructions to explore and search for a specified target in an unfamiliar environment is a crucial skill for mobile service robots. Most of the previous works on object goal navigation have typically focused on a single input modality as the target, which may lead to limited consideration of language descriptions containing detailed attributes and spatial relationships. To address this limitation, we propose VLN-Game, a novel zero-shot framework for visual target navigation that can process object names and descriptive language targets effectively. To be more precise, our approach constructs a 3D object-centric spatial map by integrating pre-trained visual-language features with a 3D reconstruction of the physical environment. Then, the framework identifies the most promising areas to explore in search of potential target candidates. A game-theoretic vision language model is employed to determine which target best matches the given language description. Experiments conducted on the Habitat-Matterport 3D (HM3D) dataset demonstrate that the proposed framework achieves state-of-the-art performance in both object goal navigation and language-based navigation tasks. Moreover, we show that VLN-Game can be easily deployed on real-world robots. The success of VLN-Game highlights the promising potential of using game-theoretic methods with compact vision-language models to advance decision-making capabilities in robotic systems. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/vln-game.
EAR-Net: Pursuing End-to-End Absolute Rotations from Multi-View Images
Oct 16, 2023Absolute rotation estimation is an important topic in 3D computer vision. Existing works in literature generally employ a multi-stage (at least two-stage) estimation strategy where multiple independent operations (feature matching, two-view rotation estimation, and rotation averaging) are implemented sequentially. However, such a multi-stage strategy inevitably leads to the accumulation of the errors caused by each involved operation, and degrades its final estimation on global rotations accordingly. To address this problem, we propose an End-to-end method for estimating Absolution Rotations from multi-view images based on deep neural Networks, called EAR-Net. The proposed EAR-Net consists of an epipolar confidence graph construction module and a confidence-aware rotation averaging module. The epipolar confidence graph construction module is explored to simultaneously predict pairwise relative rotations among the input images and their corresponding confidences, resulting in a weighted graph (called epipolar confidence graph). Based on this graph, the confidence-aware rotation averaging module, which is differentiable, is explored to predict the absolute rotations. Thanks to the introduced confidences of the relative rotations, the proposed EAR-Net could effectively handle outlier cases. Experimental results on three public datasets demonstrate that EAR-Net outperforms the state-of-the-art methods by a large margin in terms of accuracy and speed.
Lifelike Agility and Play on Quadrupedal Robots using Reinforcement Learning and Generative Pre-trained Models
Aug 29, 2023Summarizing knowledge from animals and human beings inspires robotic innovations. In this work, we propose a framework for driving legged robots act like real animals with lifelike agility and strategy in complex environments. Inspired by large pre-trained models witnessed with impressive performance in language and image understanding, we introduce the power of advanced deep generative models to produce motor control signals stimulating legged robots to act like real animals. Unlike conventional controllers and end-to-end RL methods that are task-specific, we propose to pre-train generative models over animal motion datasets to preserve expressive knowledge of animal behavior. The pre-trained model holds sufficient primitive-level knowledge yet is environment-agnostic. It is then reused for a successive stage of learning to align with the environments by traversing a number of challenging obstacles that are rarely considered in previous approaches, including creeping through narrow spaces, jumping over hurdles, freerunning over scattered blocks, etc. Finally, a task-specific controller is trained to solve complex downstream tasks by reusing the knowledge from previous stages. Enriching the knowledge regarding each stage does not affect the usage of other levels of knowledge. This flexible framework offers the possibility of continual knowledge accumulation at different levels. We successfully apply the trained multi-level controllers to the MAX robot, a quadrupedal robot developed in-house, to mimic animals, traverse complex obstacles, and play in a designed challenging multi-agent Chase Tag Game, where lifelike agility and strategy emerge on the robots. The present research pushes the frontier of robot control with new insights on reusing multi-level pre-trained knowledge and solving highly complex downstream tasks in the real world.
Social4Rec: Distilling User Preference from Social Graph for Video Recommendation in Tencent
Feb 23, 2023Despite recommender systems play a key role in network content platforms, mining the user's interests is still a significant challenge. Existing works predict the user interest by utilizing user behaviors, i.e., clicks, views, etc., but current solutions are ineffective when users perform unsettled activities. The latter ones involve new users, which have few activities of any kind, and sparse users who have low-frequency behaviors. We uniformly describe both these user-types as "cold users", which are very common but often neglected in network content platforms. To address this issue, we enhance the representation of the user interest by combining his social interest, e.g., friendship, following bloggers, interest groups, etc., with the activity behaviors. Thus, in this work, we present a novel algorithm entitled SocialNet, which adopts a two-stage method to progressively extract the coarse-grained and fine-grained social interest. Our technique then concatenates SocialNet's output with the original user representation to get the final user representation that combines behavior interests and social interests. Offline experiments on Tencent video's recommender system demonstrate the superiority over the baseline behavior-based model. The online experiment also shows a significant performance improvement in clicks and view time in the real-world recommendation system. The source code is available at https://github.com/Social4Rec/SocialNet.
Descriptor Distillation: a Teacher-Student-Regularized Framework for Learning Local Descriptors
Sep 23, 2022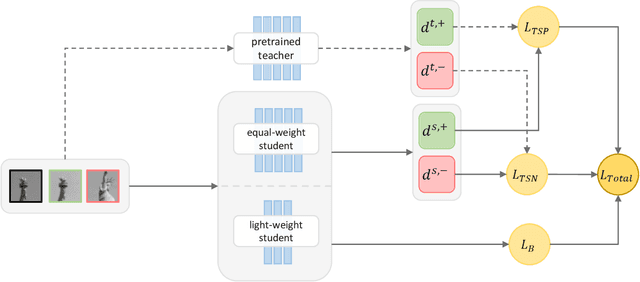
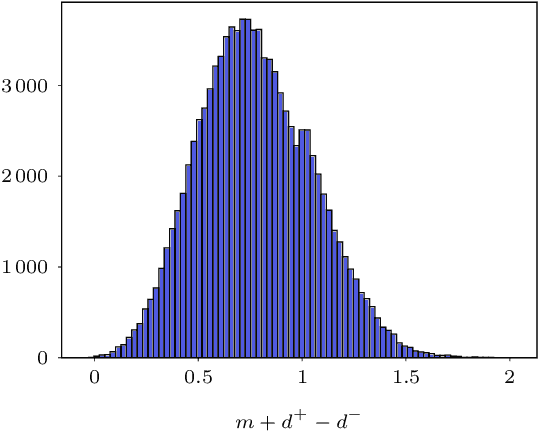
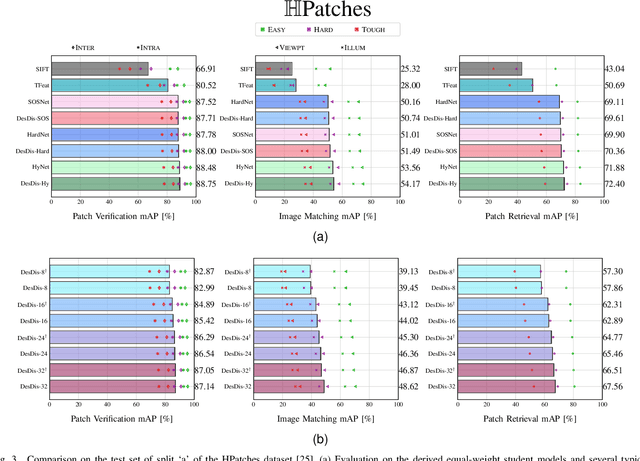

Learning a fast and discriminative patch descriptor is a challenging topic in computer vision. Recently, many existing works focus on training various descriptor learning networks by minimizing a triplet loss (or its variants), which is expected to decrease the distance between each positive pair and increase the distance between each negative pair. However, such an expectation has to be lowered due to the non-perfect convergence of network optimizer to a local solution. Addressing this problem and the open computational speed problem, we propose a Descriptor Distillation framework for local descriptor learning, called DesDis, where a student model gains knowledge from a pre-trained teacher model, and it is further enhanced via a designed teacher-student regularizer. This teacher-student regularizer is to constrain the difference between the positive (also negative) pair similarity from the teacher model and that from the student model, and we theoretically prove that a more effective student model could be trained by minimizing a weighted combination of the triplet loss and this regularizer, than its teacher which is trained by minimizing the triplet loss singly. Under the proposed DesDis, many existing descriptor networks could be embedded as the teacher model, and accordingly, both equal-weight and light-weight student models could be derived, which outperform their teacher in either accuracy or speed. Experimental results on 3 public datasets demonstrate that the equal-weight student models, derived from the proposed DesDis framework by utilizing three typical descriptor learning networks as teacher models, could achieve significantly better performances than their teachers and several other comparative methods. In addition, the derived light-weight models could achieve 8 times or even faster speeds than the comparative methods under similar patch verification performances
LT4REC:A Lottery Ticket Hypothesis Based Multi-task Practice for Video Recommendation System
Aug 22, 2020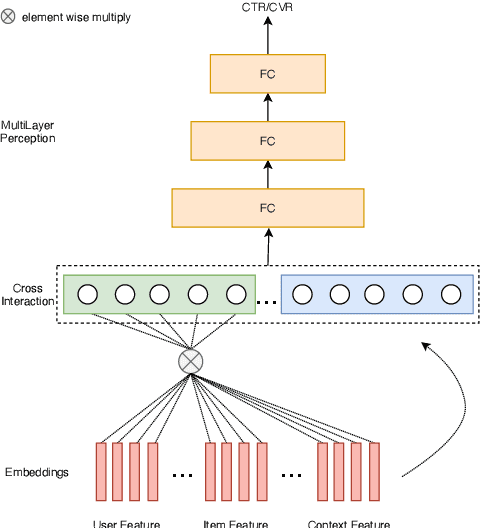

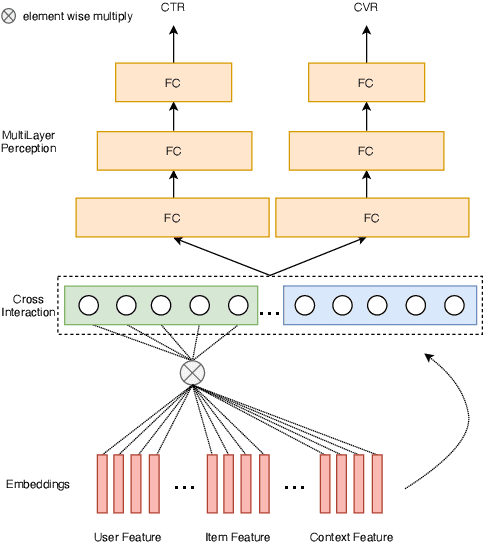
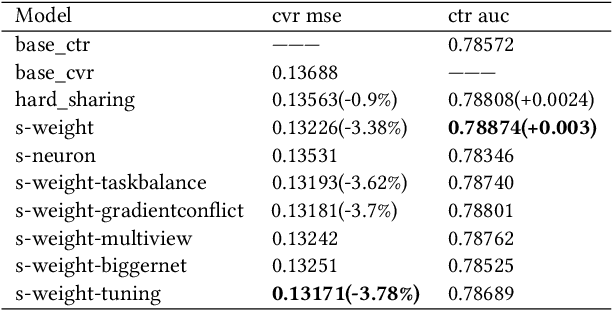
Click-through rate prediction (CTR) and post-click conversion rate prediction (CVR) play key roles across all industrial ranking systems, such as recommendation systems, online advertising, and search engines. Different from the extensive research on CTR, there is much less research on CVR estimation, whose main challenge is extreme data sparsity with one or two orders of magnitude reduction in the number of samples than CTR. People try to solve this problem with the paradigm of multi-task learning with the sufficient samples of CTR, but the typical hard sharing method can't effectively solve this problem, because it is difficult to analyze which parts of network components can be shared and which parts are in conflict, i.e., there is a large inaccuracy with artificially designed neurons sharing. In this paper, we model CVR in a brand-new method by adopting the lottery-ticket-hypothesis-based sparse sharing multi-task learning, which can automatically and flexibly learn which neuron weights to be shared without artificial experience. Experiments on the dataset gathered from traffic logs of Tencent video's recommendation system demonstrate that sparse sharing in the CVR model significantly outperforms competitive methods. Due to the nature of weight sparsity in sparse sharing, it can also significantly reduce computational complexity and memory usage which are very important in the industrial recommendation system.