 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAGLNet: Uncertainty-Aggregated Global-Local Fusion Network with Cooperative CNN-Transformer for Building Extraction
Dec 15, 2025Building extraction from remote sensing images is a challenging task due to the complex structure variations of the buildings. Existing methods employ convolutional or self-attention blocks to capture the multi-scale features in the segmentation models, while the inherent gap of the feature pyramids and insufficient global-local feature integration leads to inaccurate, ambiguous extraction results. To address this issue, in this paper, we present an Uncertainty-Aggregated Global-Local Fusion Network (UAGLNet), which is capable to exploit high-quality global-local visual semantics under the guidance of uncertainty modeling. Specifically, we propose a novel cooperative encoder, which adopts hybrid CNN and transformer layers at different stages to capture the local and global visual semantics, respectively. An intermediate cooperative interaction block (CIB) is designed to narrow the gap between the local and global features when the network becomes deeper. Afterwards, we propose a Global-Local Fusion (GLF) module to complementarily fuse the global and local representations. Moreover, to mitigate the segmentation ambiguity in uncertain regions, we propose an Uncertainty-Aggregated Decoder (UAD) to explicitly estimate the pixel-wise uncertainty to enhance the segmentation accuracy. Extensive experiments demonstrate that our method achieves superior performance to other state-of-the-art methods. Our code is available at https://github.com/Dstate/UAGLNet
Efficient Robotic Policy Learning via Latent Space Backward Planning
May 11, 2025Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach can serve as a generic world model, it introduces two significant challenges for downstream policy learning: substantial computational costs that hinder real-time deployment, and accumulated inaccuracies that can mislead action extraction. Planning with coarse-grained subgoals partially alleviates efficiency issues. However, their forward planning schemes can still result in off-task predictions due to accumulation errors, leading to misalignment with long-term goals. This raises a critical question: Can robotic planning be both efficient and accurate enough for real-time control in long-horizon, multi-stage tasks? To address this, we propose a Latent Space Backward Planning scheme (LBP), which begins by grounding the task into final latent goals, followed by recursively predicting intermediate subgoals closer to the current state. The grounded final goal enables backward subgoal planning to always remain aware of task completion, facilitating on-task prediction along the entire planning horizon. The subgoal-conditioned policy incorporates a learnable token to summarize the subgoal sequences and determines how each subgoal guides action extraction. Through extensive simulation and real-robot long-horizon experiments, we show that LBP outperforms existing fine-grained and forward planning methods, achieving SOTA performance. Project Page: https://lbp-authors.github.io
Universal Actions for Enhanced Embodied Foundation Models
Jan 17, 2025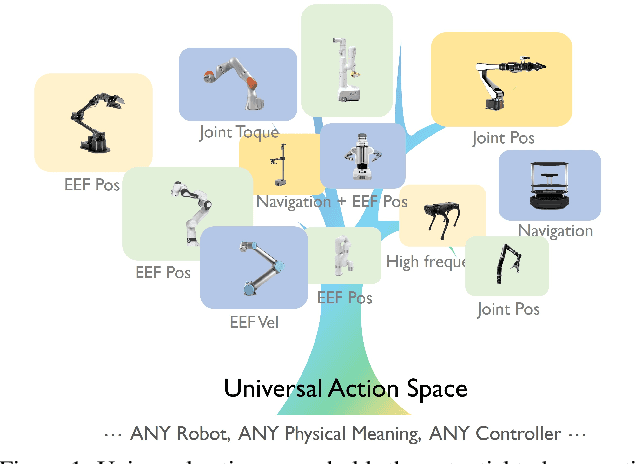

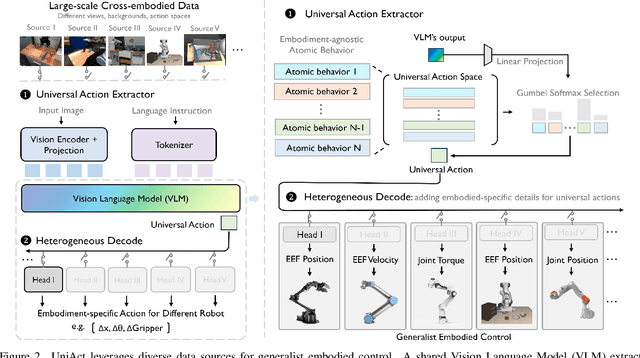
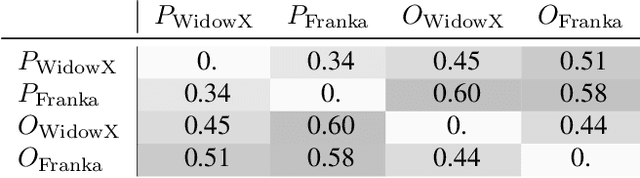
Training on diverse, internet-scale data is a key factor in the success of recent large foundation models. Yet, using the same recipe for building embodied agents has faced noticeable difficulties. Despite the availability of many crowd-sourced embodied datasets, their action spaces often exhibit significant heterogeneity due to distinct physical embodiment and control interfaces for different robots, causing substantial challenges in developing embodied foundation models using cross-domain data. In this paper, we introduce UniAct, a new embodied foundation modeling framework operating in a tokenized Universal Action Space. Our learned universal actions capture the generic atomic behaviors across diverse robots by exploiting their shared structural features, and enable enhanced cross-domain data utilization and cross-embodiment generalizations by eliminating the notorious heterogeneity. The universal actions can be efficiently translated back to heterogeneous actionable commands by simply adding embodiment-specific details, from which fast adaptation to new robots becomes simple and straightforward. Our 0.5B instantiation of UniAct outperforms 14X larger SOTA embodied foundation models in extensive evaluations on various real-world and simulation robots, showcasing exceptional cross-embodiment control and adaptation capability, highlighting the crucial benefit of adopting universal actions. Project page: https://github.com/2toinf/UniAct