 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenhua Dong
DisCover: Disentangled Music Representation Learning for Cover Song Identification
Jul 19, 2023
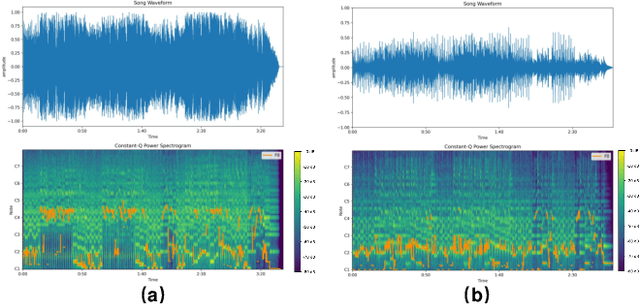

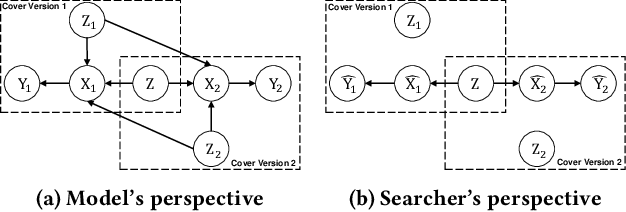
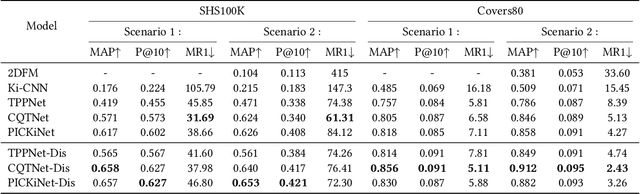
In the field of music information retrieval (MIR), cover song identification (CSI) is a challenging task that aims to identify cover versions of a query song from a massive collection. Existing works still suffer from high intra-song variances and inter-song correlations, due to the entangled nature of version-specific and version-invariant factors in their modeling. In this work, we set the goal of disentangling version-specific and version-invariant factors, which could make it easier for the model to learn invariant music representations for unseen query songs. We analyze the CSI task in a disentanglement view with the causal graph technique, and identify the intra-version and inter-version effects biasing the invariant learning. To block these effects, we propose the disentangled music representation learning framework (DisCover) for CSI. DisCover consists of two critical components: (1) Knowledge-guided Disentanglement Module (KDM) and (2) Gradient-based Adversarial Disentanglement Module (GADM), which block intra-version and inter-version biased effects, respectively. KDM minimizes the mutual information between the learned representations and version-variant factors that are identified with prior domain knowledge. GADM identifies version-variant factors by simulating the representation transitions between intra-song versions, and exploits adversarial distillation for effect blocking. Extensive comparisons with best-performing methods and in-depth analysis demonstrate the effectiveness of DisCover and the and necessity of disentanglement for CSI.
ReLoop2: Building Self-Adaptive Recommendation Models via Responsive Error Compensation Loop
Jun 22, 2023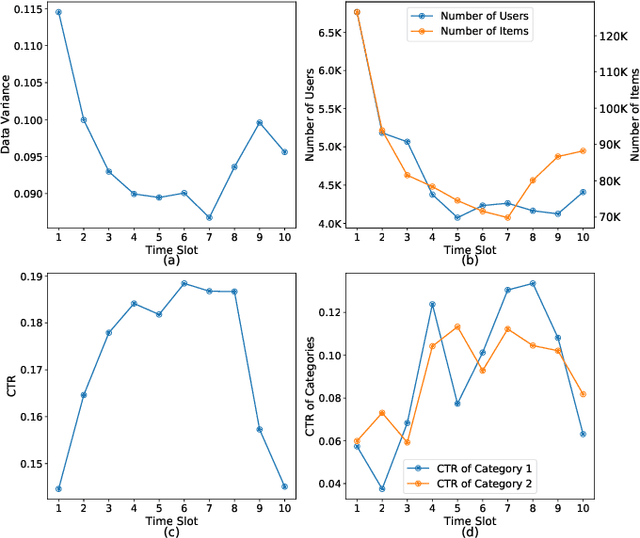
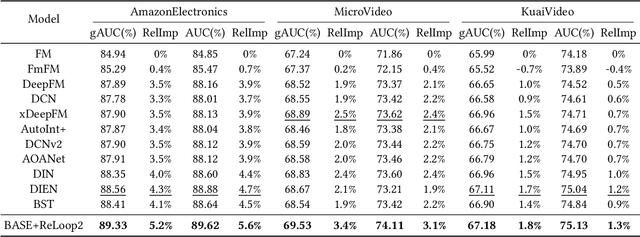
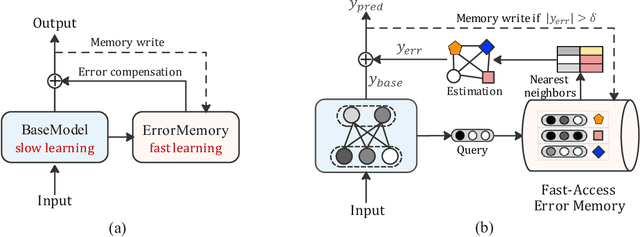
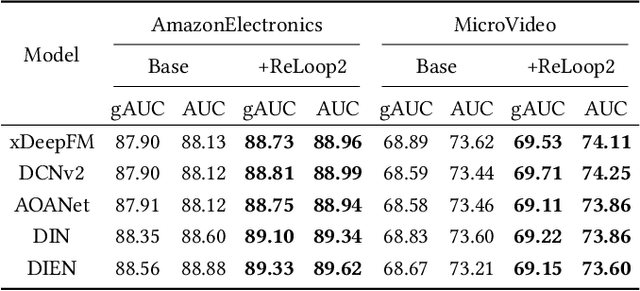
Industrial recommender systems face the challenge of operating in non-stationary environments, where data distribution shifts arise from evolving user behaviors over time. To tackle this challenge, a common approach is to periodically re-train or incrementally update deployed deep models with newly observed data, resulting in a continual training process. However, the conventional learning paradigm of neural networks relies on iterative gradient-based updates with a small learning rate, making it slow for large recommendation models to adapt. In this paper, we introduce ReLoop2, a self-correcting learning loop that facilitates fast model adaptation in online recommender systems through responsive error compensation. Inspired by the slow-fast complementary learning system observed in human brains, we propose an error memory module that directly stores error samples from incoming data streams. These stored samples are subsequently leveraged to compensate for model prediction errors during testing, particularly under distribution shifts. The error memory module is designed with fast access capabilities and undergoes continual refreshing with newly observed data samples during the model serving phase to support fast model adaptation. We evaluate the effectiveness of ReLoop2 on three open benchmark datasets as well as a real-world production dataset. The results demonstrate the potential of ReLoop2 in enhancing the responsiveness and adaptiveness of recommender systems operating in non-stationary environments.
FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction
Apr 06, 2023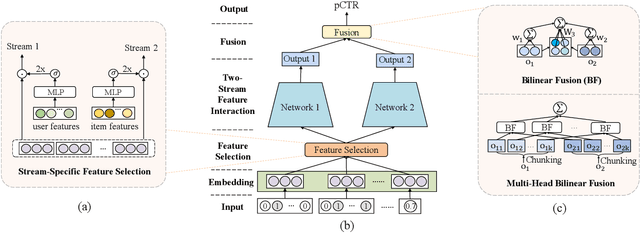
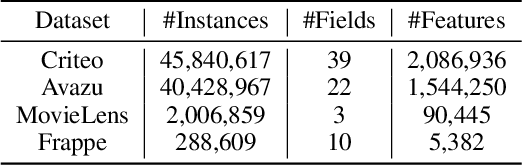
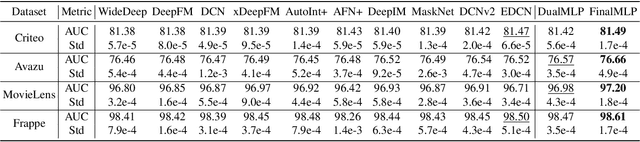
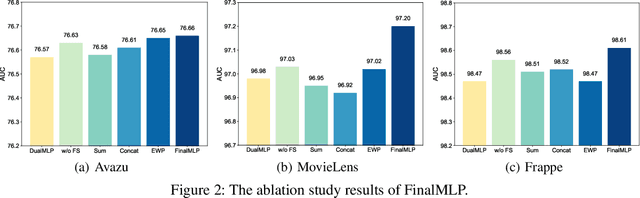
Click-through rate (CTR) prediction is one of the fundamental tasks for online advertising and recommendation. While multi-layer perceptron (MLP) serves as a core component in many deep CTR prediction models, it has been widely recognized that applying a vanilla MLP network alone is inefficient in learning multiplicative feature interactions. As such, many two-stream interaction models (e.g., DeepFM and DCN) have been proposed by integrating an MLP network with another dedicated network for enhanced CTR prediction. As the MLP stream learns feature interactions implicitly, existing research focuses mainly on enhancing explicit feature interactions in the complementary stream. In contrast, our empirical study shows that a well-tuned two-stream MLP model that simply combines two MLPs can even achieve surprisingly good performance, which has never been reported before by existing work. Based on this observation, we further propose feature selection and interaction aggregation layers that can be easily plugged to make an enhanced two-stream MLP model, FinalMLP. In this way, it not only enables differentiated feature inputs but also effectively fuses stream-level interactions across two streams. Our evaluation results on four open benchmark datasets as well as an online A/B test in our industrial system show that FinalMLP achieves better performance than many sophisticated two-stream CTR models. Our source code will be available at MindSpore/models and FuxiCTR/model_zoo.
FANS: Fast Non-Autoregressive Sequence Generation for Item List Continuation
Apr 02, 2023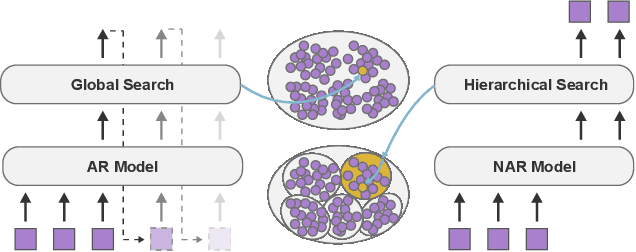
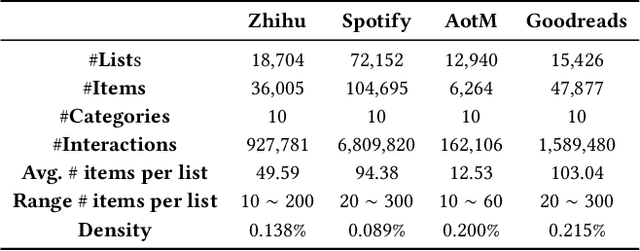
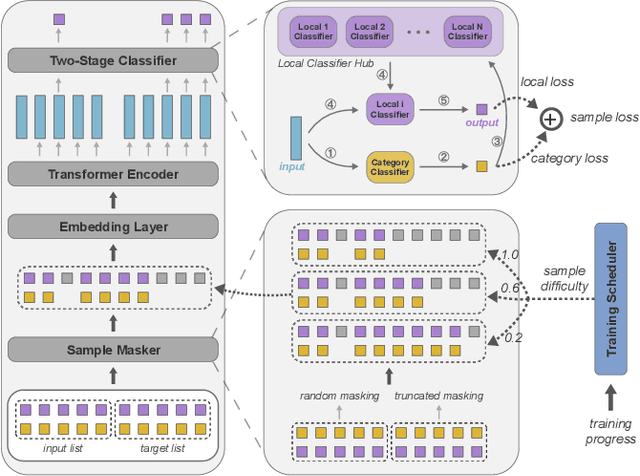
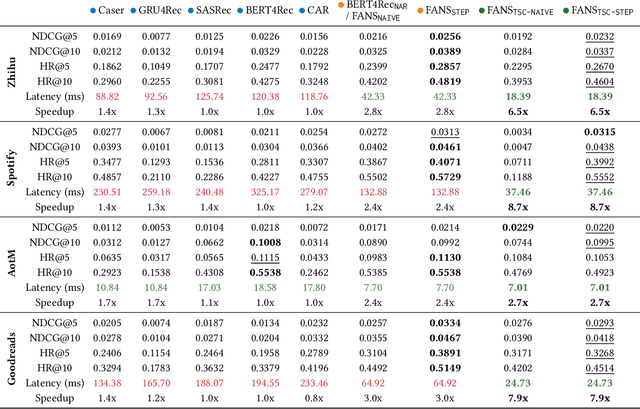
User-curated item lists, such as video-based playlists on Youtube and book-based lists on Goodreads, have become prevalent for content sharing on online platforms. Item list continuation is proposed to model the overall trend of a list and predict subsequent items. Recently, Transformer-based models have shown promise in comprehending contextual information and capturing item relationships in a list. However, deploying them in real-time industrial applications is challenging, mainly because the autoregressive generation mechanism used in them is time-consuming. In this paper, we propose a novel fast non-autoregressive sequence generation model, namely FANS, to enhance inference efficiency and quality for item list continuation. First, we use a non-autoregressive generation mechanism to decode next $K$ items simultaneously instead of one by one in existing models. Then, we design a two-stage classifier to replace the vanilla classifier used in current transformer-based models to further reduce the decoding time. Moreover, to improve the quality of non-autoregressive generation, we employ a curriculum learning strategy to optimize training. Experimental results on four real-world item list continuation datasets including Zhihu, Spotify, AotM, and Goodreads show that our FANS model can significantly improve inference efficiency (up to 8.7x) while achieving competitive or better generation quality for item list continuation compared with the state-of-the-art autoregressive models. We also validate the efficiency of FANS in an industrial setting. Our source code and data will be available at MindSpore/models and Github.
Fair-CDA: Continuous and Directional Augmentation for Group Fairness
Apr 01, 2023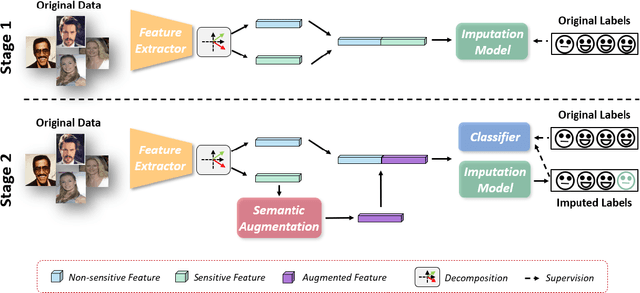
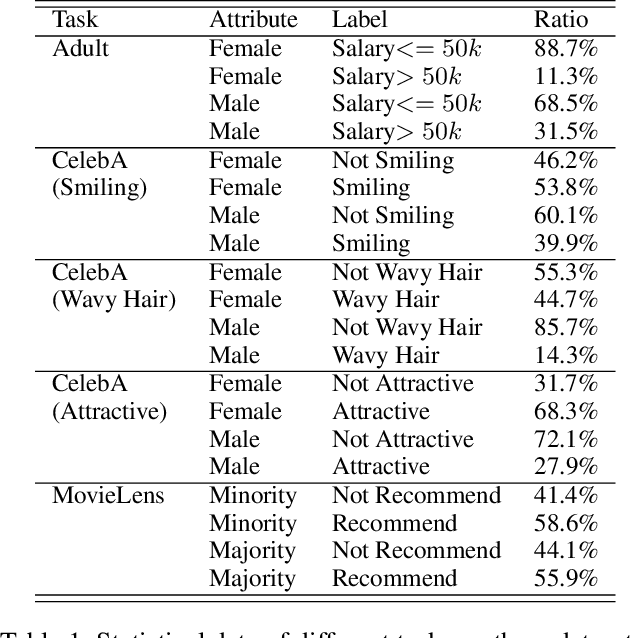
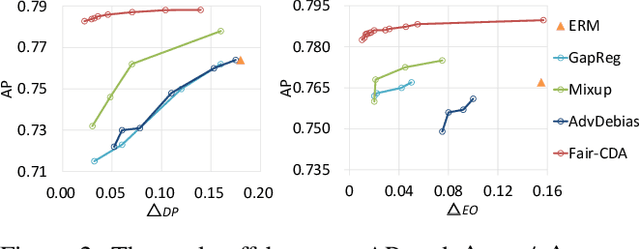
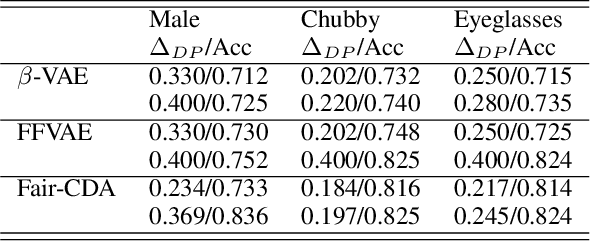
In this work, we propose {\it Fair-CDA}, a fine-grained data augmentation strategy for imposing fairness constraints. We use a feature disentanglement method to extract the features highly related to the sensitive attributes. Then we show that group fairness can be achieved by regularizing the models on transition paths of sensitive features between groups. By adjusting the perturbation strength in the direction of the paths, our proposed augmentation is controllable and auditable. To alleviate the accuracy degradation caused by fairness constraints, we further introduce a calibrated model to impute labels for the augmented data. Our proposed method does not assume any data generative model and ensures good generalization for both accuracy and fairness. Experimental results show that Fair-CDA consistently outperforms state-of-the-art methods on widely-used benchmarks, e.g., Adult, CelebA and MovieLens. Especially, Fair-CDA obtains an 86.3\% relative improvement for fairness while maintaining the accuracy on the Adult dataset. Moreover, we evaluate Fair-CDA in an online recommendation system to demonstrate the effectiveness of our method in terms of accuracy and fairness.
Bounding System-Induced Biases in Recommender Systems with A Randomized Dataset
Mar 21, 2023Debiased recommendation with a randomized dataset has shown very promising results in mitigating the system-induced biases. However, it still lacks more theoretical insights or an ideal optimization objective function compared with the other more well studied route without a randomized dataset. To bridge this gap, we study the debiasing problem from a new perspective and propose to directly minimize the upper bound of an ideal objective function, which facilitates a better potential solution to the system-induced biases. Firstly, we formulate a new ideal optimization objective function with a randomized dataset. Secondly, according to the prior constraints that an adopted loss function may satisfy, we derive two different upper bounds of the objective function, i.e., a generalization error bound with the triangle inequality and a generalization error bound with the separability. Thirdly, we show that most existing related methods can be regarded as the insufficient optimization of these two upper bounds. Fourthly, we propose a novel method called debiasing approximate upper bound with a randomized dataset (DUB), which achieves a more sufficient optimization of these upper bounds. Finally, we conduct extensive experiments on a public dataset and a real product dataset to verify the effectiveness of our DUB.
REASONER: An Explainable Recommendation Dataset with Multi-aspect Real User Labeled Ground Truths Towards more Measurable Explainable Recommendation
Mar 01, 2023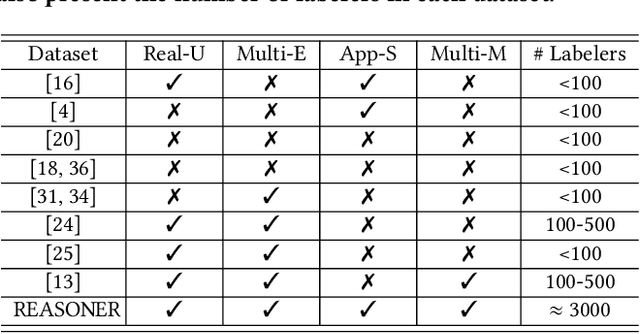
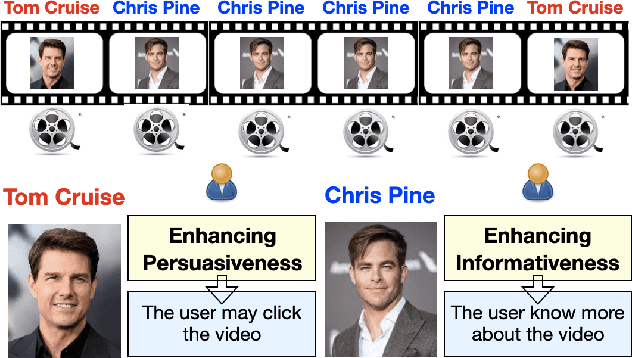
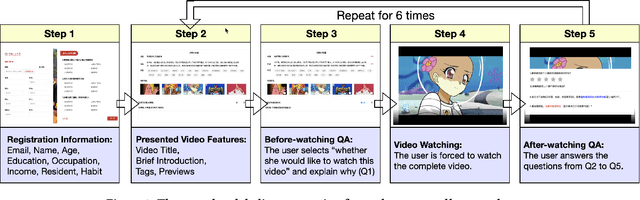

Explainable recommendation has attracted much attention from the industry and academic communities. It has shown great potential for improving the recommendation persuasiveness, informativeness and user satisfaction. Despite a lot of promising explainable recommender models have been proposed in the past few years, the evaluation strategies of these models suffer from several limitations. For example, the explanation ground truths are not labeled by real users, the explanations are mostly evaluated based on only one aspect and the evaluation strategies can be hard to unify. To alleviate the above problems, we propose to build an explainable recommendation dataset with multi-aspect real user labeled ground truths. In specific, we firstly develop a video recommendation platform, where a series of questions around the recommendation explainability are carefully designed. Then, we recruit about 3000 users with different backgrounds to use the system, and collect their behaviors and feedback to our questions. In this paper, we detail the construction process of our dataset and also provide extensive analysis on its characteristics. In addition, we develop a library, where ten well-known explainable recommender models are implemented in a unified framework. Based on this library, we build several benchmarks for different explainable recommendation tasks. At last, we present many new opportunities brought by our dataset, which are expected to shed some new lights to the explainable recommendation field. Our dataset, library and the related documents have been released at https://reasoner2023.github.io/.
A Generalized Doubly Robust Learning Framework for Debiasing Post-Click Conversion Rate Prediction
Nov 12, 2022
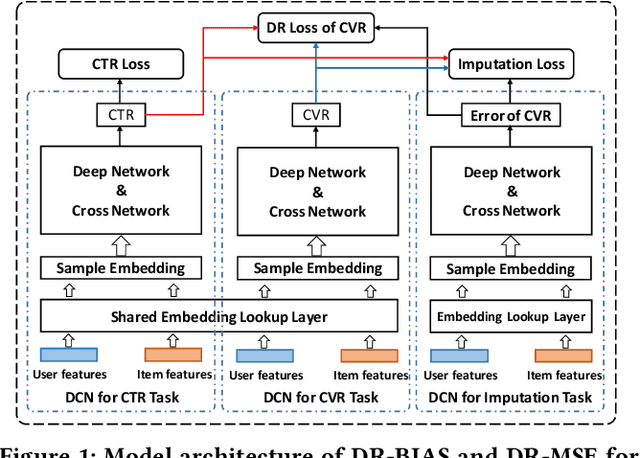
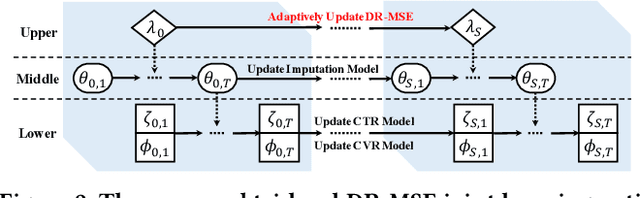
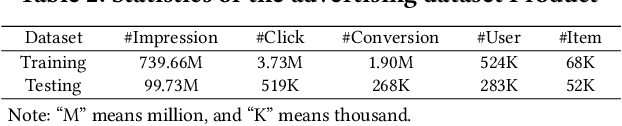
Post-click conversion rate (CVR) prediction is an essential task for discovering user interests and increasing platform revenues in a range of industrial applications. One of the most challenging problems of this task is the existence of severe selection bias caused by the inherent self-selection behavior of users and the item selection process of systems. Currently, doubly robust (DR) learning approaches achieve the state-of-the-art performance for debiasing CVR prediction. However, in this paper, by theoretically analyzing the bias, variance and generalization bounds of DR methods, we find that existing DR approaches may have poor generalization caused by inaccurate estimation of propensity scores and imputation errors, which often occur in practice. Motivated by such analysis, we propose a generalized learning framework that not only unifies existing DR methods, but also provides a valuable opportunity to develop a series of new debiasing techniques to accommodate different application scenarios. Based on the framework, we propose two new DR methods, namely DR-BIAS and DR-MSE. DR-BIAS directly controls the bias of DR loss, while DR-MSE balances the bias and variance flexibly, which achieves better generalization performance. In addition, we propose a novel tri-level joint learning optimization method for DR-MSE in CVR prediction, and an efficient training algorithm correspondingly. We conduct extensive experiments on both real-world and semi-synthetic datasets, which validate the effectiveness of our proposed methods.