 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataCube: A Video Retrieval Platform via Natural Language Semantic Profiling
Feb 18, 2026Large-scale video repositories are increasingly available for modern video understanding and generation tasks. However, transforming raw videos into high-quality, task-specific datasets remains costly and inefficient. We present DataCube, an intelligent platform for automatic video processing, multi-dimensional profiling, and query-driven retrieval. DataCube constructs structured semantic representations of video clips and supports hybrid retrieval with neural re-ranking and deep semantic matching. Through an interactive web interface, users can efficiently construct customized video subsets from massive repositories for training, analysis, and evaluation, and build searchable systems over their own private video collections. The system is publicly accessible at https://datacube.baai.ac.cn/. Demo Video: https://baai-data-cube.ks3-cn-beijing.ksyuncs.com/custom/Adobe%20Express%20-%202%E6%9C%8818%E6%97%A5%20%281%29%281%29%20%281%29.mp4
CI-VID: A Coherent Interleaved Text-Video Dataset
Jul 02, 2025Text-to-video (T2V) generation has recently attracted considerable attention, resulting in the development of numerous high-quality datasets that have propelled progress in this area. However, existing public datasets are primarily composed of isolated text-video (T-V) pairs and thus fail to support the modeling of coherent multi-clip video sequences. To address this limitation, we introduce CI-VID, a dataset that moves beyond isolated text-to-video (T2V) generation toward text-and-video-to-video (TV2V) generation, enabling models to produce coherent, multi-scene video sequences. CI-VID contains over 340,000 samples, each featuring a coherent sequence of video clips with text captions that capture both the individual content of each clip and the transitions between them, enabling visually and textually grounded generation. To further validate the effectiveness of CI-VID, we design a comprehensive, multi-dimensional benchmark incorporating human evaluation, VLM-based assessment, and similarity-based metrics. Experimental results demonstrate that models trained on CI-VID exhibit significant improvements in both accuracy and content consistency when generating video sequences. This facilitates the creation of story-driven content with smooth visual transitions and strong temporal coherence, underscoring the quality and practical utility of the CI-VID dataset We release the CI-VID dataset and the accompanying code for data construction and evaluation at: https://github.com/ymju-BAAI/CI-VID
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
Beyond IID: Optimizing Instruction Learning from the Perspective of Instruction Interaction and Dependency
Sep 11, 2024



With the availability of various instruction datasets, a pivotal challenge is how to effectively select and integrate these instructions to fine-tune large language models (LLMs). Previous research mainly focuses on selecting individual high-quality instructions. However, these works overlooked the joint interactions and dependencies between different categories of instructions, leading to suboptimal selection strategies. Moreover, the nature of these interaction patterns remains largely unexplored, let alone optimize the instruction set with regard to them. To fill these gaps, in this paper, we: (1) systemically investigate interaction and dependency patterns between different categories of instructions, (2) manage to optimize the instruction set concerning the interaction patterns using a linear programming-based method, and optimize the learning schema of SFT using an instruction dependency taxonomy guided curriculum learning. Experimental results across different LLMs demonstrate improved performance over strong baselines on widely adopted benchmarks.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering
Mar 08, 2024



Open-domain question answering (ODQA) has emerged as a pivotal research spotlight in information systems. Existing methods follow two main paradigms to collect evidence: (1) The \textit{retrieve-then-read} paradigm retrieves pertinent documents from an external corpus; and (2) the \textit{generate-then-read} paradigm employs large language models (LLMs) to generate relevant documents. However, neither can fully address multifaceted requirements for evidence. To this end, we propose LLMQA, a generalized framework that formulates the ODQA process into three basic steps: query expansion, document selection, and answer generation, combining the superiority of both retrieval-based and generation-based evidence. Since LLMs exhibit their excellent capabilities to accomplish various tasks, we instruct LLMs to play multiple roles as generators, rerankers, and evaluators within our framework, integrating them to collaborate in the ODQA process. Furthermore, we introduce a novel prompt optimization algorithm to refine role-playing prompts and steer LLMs to produce higher-quality evidence and answers. Extensive experimental results on widely used benchmarks (NQ, WebQ, and TriviaQA) demonstrate that LLMQA achieves the best performance in terms of both answer accuracy and evidence quality, showcasing its potential for advancing ODQA research and applications.
Obstacle-Transformer: A Trajectory Prediction Network Based on Surrounding Trajectories
Apr 16, 2023



Recurrent Neural Network, Long Short-Term Memory, and Transformer have made great progress in predicting the trajectories of moving objects. Although the trajectory element with the surrounding scene features has been merged to improve performance, there still exist some problems to be solved. One is that the time series processing models will increase the inference time with the increase of the number of prediction sequences. Another lies in which the features can not be extracted from the scene's image and point cloud in some situations. Therefore, this paper proposes an Obstacle-Transformer to predict trajectory in a constant inference time. An ``obstacle'' is designed by the surrounding trajectory rather than images or point clouds, making Obstacle-Transformer more applicable in a wider range of scenarios. Experiments are conducted on ETH and UCY data sets to verify the performance of our model.
* 8 pages, 4 figures
Lyapunov-Based Reinforcement Learning State Estimator
Oct 26, 2020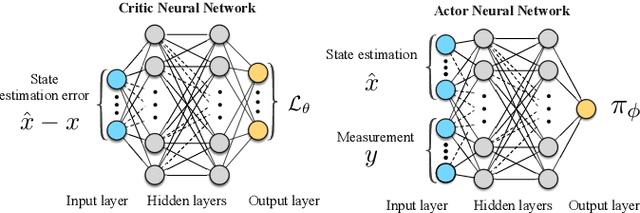
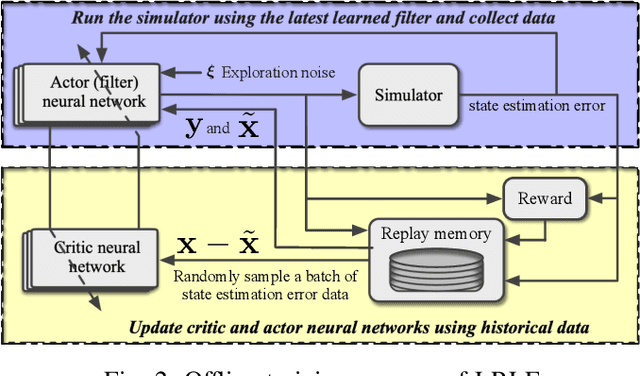
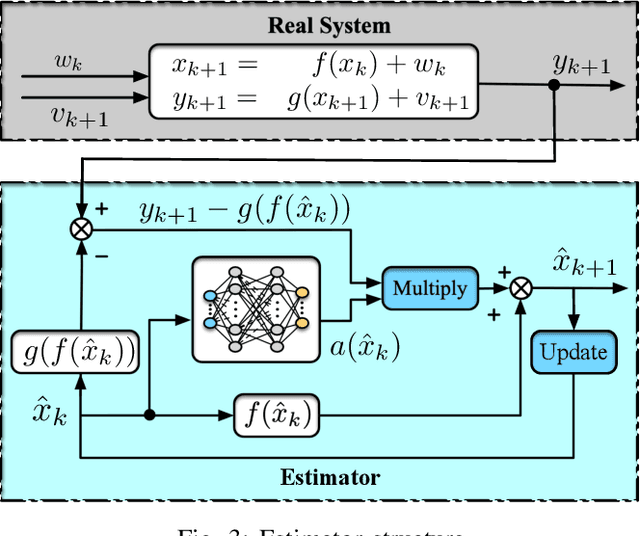
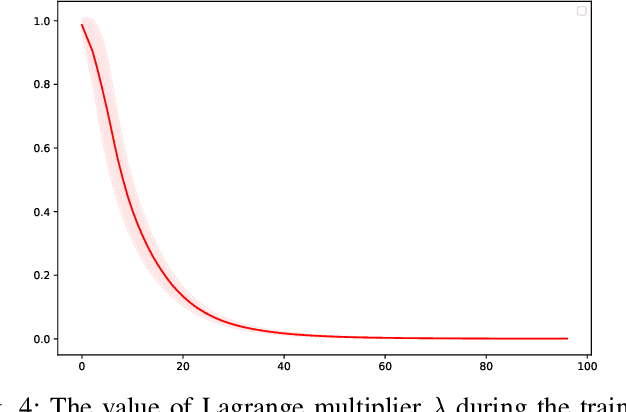
In this paper, we consider the state estimation problem for nonlinear stochastic discrete-time systems. We combine Lyapunov's method in control theory and deep reinforcement learning to design the state estimator. We theoretically prove the convergence of the bounded estimate error solely using the data simulated from the model. An actor-critic reinforcement learning algorithm is proposed to learn the state estimator approximated by a deep neural network. The convergence of the algorithm is analysed. The proposed Lyapunov-based reinforcement learning state estimator is compared with a number of existing nonlinear filtering methods through Monte Carlo simulations, showing its advantage in terms of estimate convergence even under some system uncertainties such as covariance shift in system noise and randomly missing measurements. To the best of our knowledge, this is the first reinforcement learning based nonlinear state estimator with bounded estimate error performance guarantee.