 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFIL: Deepfake Incremental Learning by Exploiting Domain-invariant Forgery Clues
Sep 18, 2023



The malicious use and widespread dissemination of deepfake pose a significant crisis of trust. Current deepfake detection models can generally recognize forgery images by training on a large dataset. However, the accuracy of detection models degrades significantly on images generated by new deepfake methods due to the difference in data distribution. To tackle this issue, we present a novel incremental learning framework that improves the generalization of deepfake detection models by continual learning from a small number of new samples. To cope with different data distributions, we propose to learn a domain-invariant representation based on supervised contrastive learning, preventing overfit to the insufficient new data. To mitigate catastrophic forgetting, we regularize our model in both feature-level and label-level based on a multi-perspective knowledge distillation approach. Finally, we propose to select both central and hard representative samples to update the replay set, which is beneficial for both domain-invariant representation learning and rehearsal-based knowledge preserving. We conduct extensive experiments on four benchmark datasets, obtaining the new state-of-the-art average forgetting rate of 7.01 and average accuracy of 85.49 on FF++, DFDC-P, DFD, and CDF2. Our code is released at https://github.com/DeepFakeIL/DFIL.
Video Infringement Detection via Feature Disentanglement and Mutual Information Maximization
Sep 13, 2023



The self-media era provides us tremendous high quality videos. Unfortunately, frequent video copyright infringements are now seriously damaging the interests and enthusiasm of video creators. Identifying infringing videos is therefore a compelling task. Current state-of-the-art methods tend to simply feed high-dimensional mixed video features into deep neural networks and count on the networks to extract useful representations. Despite its simplicity, this paradigm heavily relies on the original entangled features and lacks constraints guaranteeing that useful task-relevant semantics are extracted from the features. In this paper, we seek to tackle the above challenges from two aspects: (1) We propose to disentangle an original high-dimensional feature into multiple sub-features, explicitly disentangling the feature into exclusive lower-dimensional components. We expect the sub-features to encode non-overlapping semantics of the original feature and remove redundant information. (2) On top of the disentangled sub-features, we further learn an auxiliary feature to enhance the sub-features. We theoretically analyzed the mutual information between the label and the disentangled features, arriving at a loss that maximizes the extraction of task-relevant information from the original feature. Extensive experiments on two large-scale benchmark datasets (i.e., SVD and VCSL) demonstrate that our method achieves 90.1% TOP-100 mAP on the large-scale SVD dataset and also sets the new state-of-the-art on the VCSL benchmark dataset. Our code and model have been released at https://github.com/yyyooooo/DMI/, hoping to contribute to the community.
Prototypical Cross-domain Knowledge Transfer for Cervical Dysplasia Visual Inspection
Aug 19, 2023



Early detection of dysplasia of the cervix is critical for cervical cancer treatment. However, automatic cervical dysplasia diagnosis via visual inspection, which is more appropriate in low-resource settings, remains a challenging problem. Though promising results have been obtained by recent deep learning models, their performance is significantly hindered by the limited scale of the available cervix datasets. Distinct from previous methods that learn from a single dataset, we propose to leverage cross-domain cervical images that were collected in different but related clinical studies to improve the model's performance on the targeted cervix dataset. To robustly learn the transferable information across datasets, we propose a novel prototype-based knowledge filtering method to estimate the transferability of cross-domain samples. We further optimize the shared feature space by aligning the cross-domain image representations simultaneously on domain level with early alignment and class level with supervised contrastive learning, which endows model training and knowledge transfer with stronger robustness. The empirical results on three real-world benchmark cervical image datasets show that our proposed method outperforms the state-of-the-art cervical dysplasia visual inspection by an absolute improvement of 4.7% in top-1 accuracy, 7.0% in precision, 1.4% in recall, 4.6% in F1 score, and 0.05 in ROC-AUC.
LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting
Jun 14, 2023



Traffic forecasting plays a critical role in smart city initiatives and has experienced significant advancements thanks to the power of deep learning in capturing non-linear patterns of traffic data. However, the promising results achieved on current public datasets may not be applicable to practical scenarios due to limitations within these datasets. First, the limited sizes of them may not reflect the real-world scale of traffic networks. Second, the temporal coverage of these datasets is typically short, posing hurdles in studying long-term patterns and acquiring sufficient samples for training deep models. Third, these datasets often lack adequate metadata for sensors, which compromises the reliability and interpretability of the data. To mitigate these limitations, we introduce the LargeST benchmark dataset. It encompasses a total number of 8,600 sensors with a 5-year time coverage and includes comprehensive metadata. Using LargeST, we perform in-depth data analysis to extract data insights, benchmark well-known baselines in terms of their performance and efficiency, and identify challenges as well as opportunities for future research. We release the datasets and baseline implementations at: https://github.com/liuxu77/LargeST.
Action Recognition with Multi-stream Motion Modeling and Mutual Information Maximization
Jun 13, 2023



Action recognition has long been a fundamental and intriguing problem in artificial intelligence. The task is challenging due to the high dimensionality nature of an action, as well as the subtle motion details to be considered. Current state-of-the-art approaches typically learn from articulated motion sequences in the straightforward 3D Euclidean space. However, the vanilla Euclidean space is not efficient for modeling important motion characteristics such as the joint-wise angular acceleration, which reveals the driving force behind the motion. Moreover, current methods typically attend to each channel equally and lack theoretical constrains on extracting task-relevant features from the input. In this paper, we seek to tackle these challenges from three aspects: (1) We propose to incorporate an acceleration representation, explicitly modeling the higher-order variations in motion. (2) We introduce a novel Stream-GCN network equipped with multi-stream components and channel attention, where different representations (i.e., streams) supplement each other towards a more precise action recognition while attention capitalizes on those important channels. (3) We explore feature-level supervision for maximizing the extraction of task-relevant information and formulate this into a mutual information loss. Empirically, our approach sets the new state-of-the-art performance on three benchmark datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. Our code is anonymously released at https://github.com/ActionR-Group/Stream-GCN, hoping to inspire the community.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023



Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
CoMeta: Enhancing Meta Embeddings with Collaborative Information in Cold-start Problem of Recommendation
Mar 14, 2023



The cold-start problem is quite challenging for existing recommendation models. Specifically, for the new items with only a few interactions, their ID embeddings are trained inadequately, leading to poor recommendation performance. Some recent studies introduce meta learning to solve the cold-start problem by generating meta embeddings for new items as their initial ID embeddings. However, we argue that the capability of these methods is limited, because they mainly utilize item attribute features which only contain little information, but ignore the useful collaborative information contained in the ID embeddings of users and old items. To tackle this issue, we propose CoMeta to enhance the meta embeddings with the collaborative information. CoMeta consists of two submodules: B-EG and S-EG. Specifically, for a new item: B-EG calculates the similarity-based weighted sum of the ID embeddings of old items as its base embedding; S-EG generates its shift embedding not only with its attribute features but also with the average ID embedding of the users who interacted with it. The final meta embedding is obtained by adding up the base embedding and the shift embedding. We conduct extensive experiments on two public datasets. The experimental results demonstrate both the effectiveness and the compatibility of CoMeta.
Who is Gambling? Finding Cryptocurrency Gamblers Using Multi-modal Retrieval Methods
Nov 27, 2022With the popularity of cryptocurrencies and the remarkable development of blockchain technology, decentralized applications emerged as a revolutionary force for the Internet. Meanwhile, decentralized applications have also attracted intense attention from the online gambling community, with more and more decentralized gambling platforms created through the help of smart contracts. Compared with conventional gambling platforms, decentralized gambling have transparent rules and a low participation threshold, attracting a substantial number of gamblers. In order to discover gambling behaviors and identify the contracts and addresses involved in gambling, we propose a tool termed ETHGamDet. The tool is able to automatically detect the smart contracts and addresses involved in gambling by scrutinizing the smart contract code and address transaction records. Interestingly, we present a novel LightGBM model with memory components, which possesses the ability to learn from its own misclassifications. As a side contribution, we construct and release a large-scale gambling dataset at https://github.com/AwesomeHuang/Bitcoin-Gambling-Dataset to facilitate future research in this field. Empirically, ETHGamDet achieves a F1-score of 0.72 and 0.89 in address classification and contract classification respectively, and offers novel and interesting insights.
Invariant Feature Learning for Generalized Long-Tailed Classification
Jul 19, 2022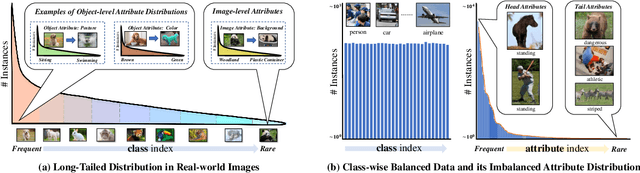
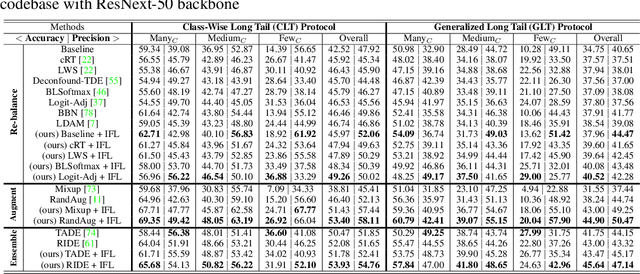
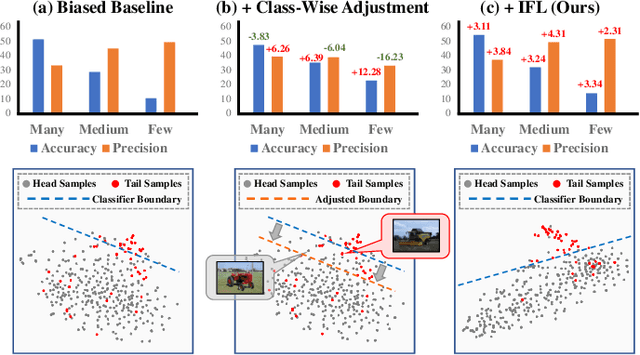
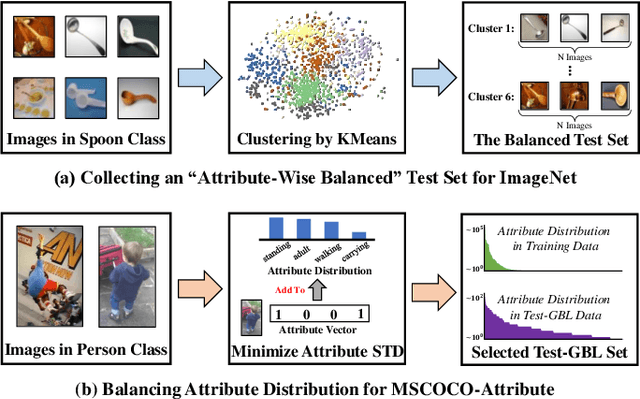
Existing long-tailed classification (LT) methods only focus on tackling the class-wise imbalance that head classes have more samples than tail classes, but overlook the attribute-wise imbalance. In fact, even if the class is balanced, samples within each class may still be long-tailed due to the varying attributes. Note that the latter is fundamentally more ubiquitous and challenging than the former because attributes are not just implicit for most datasets, but also combinatorially complex, thus prohibitively expensive to be balanced. Therefore, we introduce a novel research problem: Generalized Long-Tailed classification (GLT), to jointly consider both kinds of imbalances. By "generalized", we mean that a GLT method should naturally solve the traditional LT, but not vice versa. Not surprisingly, we find that most class-wise LT methods degenerate in our proposed two benchmarks: ImageNet-GLT and MSCOCO-GLT. We argue that it is because they over-emphasize the adjustment of class distribution while neglecting to learn attribute-invariant features. To this end, we propose an Invariant Feature Learning (IFL) method as the first strong baseline for GLT. IFL first discovers environments with divergent intra-class distributions from the imperfect predictions and then learns invariant features across them. Promisingly, as an improved feature backbone, IFL boosts all the LT line-up: one/two-stage re-balance, augmentation, and ensemble. Codes and benchmarks are available on Github: https://github.com/KaihuaTang/Generalized-Long-Tailed-Benchmarks.pytorch
Copy Motion From One to Another: Fake Motion Video Generation
May 03, 2022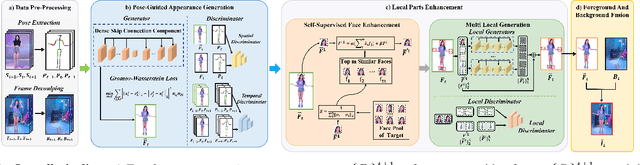
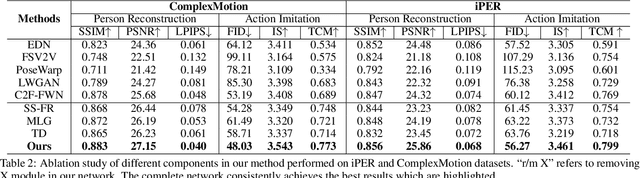
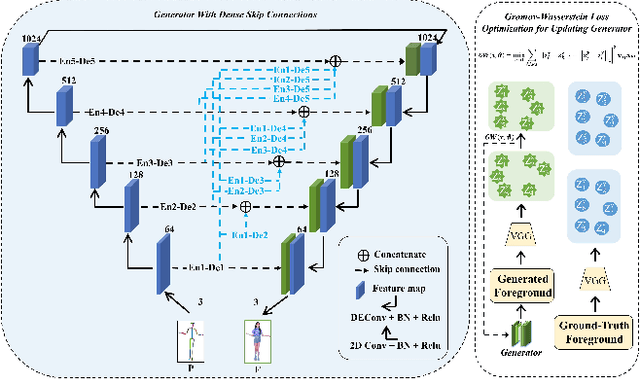
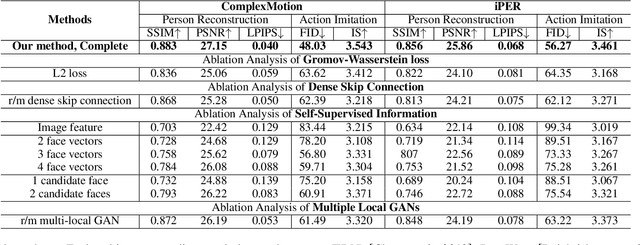
One compelling application of artificial intelligence is to generate a video of a target person performing arbitrary desired motion (from a source person). While the state-of-the-art methods are able to synthesize a video demonstrating similar broad stroke motion details, they are generally lacking in texture details. A pertinent manifestation appears as distorted face, feet, and hands, and such flaws are very sensitively perceived by human observers. Furthermore, current methods typically employ GANs with a L2 loss to assess the authenticity of the generated videos, inherently requiring a large amount of training samples to learn the texture details for adequate video generation. In this work, we tackle these challenges from three aspects: 1) We disentangle each video frame into foreground (the person) and background, focusing on generating the foreground to reduce the underlying dimension of the network output. 2) We propose a theoretically motivated Gromov-Wasserstein loss that facilitates learning the mapping from a pose to a foreground image. 3) To enhance texture details, we encode facial features with geometric guidance and employ local GANs to refine the face, feet, and hands. Extensive experiments show that our method is able to generate realistic target person videos, faithfully copying complex motions from a source person. Our code and datasets are released at https://github.com/Sifann/FakeMotion