 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFLoRA: Selective Decoupled Federated LoRA for Privacy-preserving Fine-tuning with Heterogeneous Clients
Jan 29, 2026Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a privacy-preserving approach for adapting models over distributed data, where parameter-efficient methods such as Low-Rank Adaptation (LoRA) are widely adopted to reduce communication and memory costs. However, practical deployments often exhibit rank and data heterogeneity: clients operate under different low-rank budgets and data distributions, making direct aggregation of LoRA updates biased and unstable. Existing approaches either enforce a unified rank or align heterogeneous updates into a single shared subspace, which tends to mix transferable and client-specific directions and consequently undermines personalization. Moreover, under differential privacy (DP), perturbing such structurally mixed updates injects noise into directions that should remain purely local, leading to unnecessary utility degradation. To address these issues, we propose Selective Decoupled Federated LoRA (SDFLoRA), a structure-aware LoRA framework that decouples each client update into a shared component for aggregation and a private component that preserves client-specific semantics. Only the shared component participates in subspace alignment, while the private component remains local and uncommunicated, making the training DP-compatible and stabilizing aggregation under rank heterogeneity. By injecting noise only into the aggregated shareable update, this approach avoids perturbations to local directions and improves the utility-privacy trade-off. Experiments on multiple benchmarks demonstrate that SDFLoRA outperforms federated LoRA baselines and achieves a strong utility-privacy trade-off.
SDFLoRA: Selective Dual-Module LoRA for Federated Fine-tuning with Heterogeneous Clients
Jan 16, 2026Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a way to enable privacy-preserving adaptation over distributed data. Parameter-efficient methods such as LoRA are widely adopted to reduce communication and memory costs. Despite these advances, practical FL deployments often exhibit rank heterogeneity, since different clients may use different low-rank configurations. This makes direct aggregation of LoRA updates biased and unstable. Existing solutions typically enforce unified ranks or align heterogeneous updates into a shared subspace, which over-constrains client-specific semantics, limits personalization, and provides weak protection of local client information under differential privacy noise. To address this issue, we propose Selective Dual-module Federated LoRA (SDFLoRA), which decomposes each client adapter into a global module that captures transferable knowledge and a local module that preserves client-specific adaptations. The global module is selectively aligned and aggregated across clients, while local modules remain private. This design enables robust learning under rank heterogeneity and supports privacy-aware optimization by injecting differential privacy noise exclusively into the global module. Experiments on GLUE benchmarks demonstrate that SDFLoRA outperforms representative federated LoRA baselines and achieves a better utility-privacy trade-off.
The Eminence in Shadow: Exploiting Feature Boundary Ambiguity for Robust Backdoor Attacks
Dec 17, 2025Deep neural networks (DNNs) underpin critical applications yet remain vulnerable to backdoor attacks, typically reliant on heuristic brute-force methods. Despite significant empirical advancements in backdoor research, the lack of rigorous theoretical analysis limits understanding of underlying mechanisms, constraining attack predictability and adaptability. Therefore, we provide a theoretical analysis targeting backdoor attacks, focusing on how sparse decision boundaries enable disproportionate model manipulation. Based on this finding, we derive a closed-form, ambiguous boundary region, wherein negligible relabeled samples induce substantial misclassification. Influence function analysis further quantifies significant parameter shifts caused by these margin samples, with minimal impact on clean accuracy, formally grounding why such low poison rates suffice for efficacious attacks. Leveraging these insights, we propose Eminence, an explainable and robust black-box backdoor framework with provable theoretical guarantees and inherent stealth properties. Eminence optimizes a universal, visually subtle trigger that strategically exploits vulnerable decision boundaries and effectively achieves robust misclassification with exceptionally low poison rates (< 0.1%, compared to SOTA methods typically requiring > 1%). Comprehensive experiments validate our theoretical discussions and demonstrate the effectiveness of Eminence, confirming an exponential relationship between margin poisoning and adversarial boundary manipulation. Eminence maintains > 90% attack success rate, exhibits negligible clean-accuracy loss, and demonstrates high transferability across diverse models, datasets and scenarios.
Blockchain-based Federated Recommendation with Incentive Mechanism
Sep 03, 2024


Nowadays, federated recommendation technology is rapidly evolving to help multiple organisations share data and train models while meeting user privacy, data security and government regulatory requirements. However, federated recommendation increases customer system costs such as power, computational and communication resources. Besides, federated recommendation systems are also susceptible to model attacks and data poisoning by participating malicious clients. Therefore, most customers are unwilling to participate in federated recommendation without any incentive. To address these problems, we propose a blockchain-based federated recommendation system with incentive mechanism to promote more trustworthy, secure, and efficient federated recommendation service. First, we construct a federated recommendation system based on NeuMF and FedAvg. Then we introduce a reverse auction mechanism to select optimal clients that can maximize the social surplus. Finally, we employ blockchain for on-chain evidence storage of models to ensure the safety of the federated recommendation system. The experimental results show that our proposed incentive mechanism can attract clients with superior training data to engage in the federal recommendation at a lower cost, which can increase the economic benefit of federal recommendation by 54.9\% while improve the recommendation performance. Thus our work provides theoretical and technological support for the construction of a harmonious and healthy ecological environment for the application of federal recommendation.
Clean-image Backdoor Attacks
Mar 26, 2024



To gather a significant quantity of annotated training data for high-performance image classification models, numerous companies opt to enlist third-party providers to label their unlabeled data. This practice is widely regarded as secure, even in cases where some annotated errors occur, as the impact of these minor inaccuracies on the final performance of the models is negligible and existing backdoor attacks require attacker's ability to poison the training images. Nevertheless, in this paper, we propose clean-image backdoor attacks which uncover that backdoors can still be injected via a fraction of incorrect labels without modifying the training images. Specifically, in our attacks, the attacker first seeks a trigger feature to divide the training images into two parts: those with the feature and those without it. Subsequently, the attacker falsifies the labels of the former part to a backdoor class. The backdoor will be finally implanted into the target model after it is trained on the poisoned data. During the inference phase, the attacker can activate the backdoor in two ways: slightly modifying the input image to obtain the trigger feature, or taking an image that naturally has the trigger feature as input. We conduct extensive experiments to demonstrate the effectiveness and practicality of our attacks. According to the experimental results, we conclude that our attacks seriously jeopardize the fairness and robustness of image classification models, and it is necessary to be vigilant about the incorrect labels in outsourced labeling.
CoMeta: Enhancing Meta Embeddings with Collaborative Information in Cold-start Problem of Recommendation
Mar 14, 2023



The cold-start problem is quite challenging for existing recommendation models. Specifically, for the new items with only a few interactions, their ID embeddings are trained inadequately, leading to poor recommendation performance. Some recent studies introduce meta learning to solve the cold-start problem by generating meta embeddings for new items as their initial ID embeddings. However, we argue that the capability of these methods is limited, because they mainly utilize item attribute features which only contain little information, but ignore the useful collaborative information contained in the ID embeddings of users and old items. To tackle this issue, we propose CoMeta to enhance the meta embeddings with the collaborative information. CoMeta consists of two submodules: B-EG and S-EG. Specifically, for a new item: B-EG calculates the similarity-based weighted sum of the ID embeddings of old items as its base embedding; S-EG generates its shift embedding not only with its attribute features but also with the average ID embedding of the users who interacted with it. The final meta embedding is obtained by adding up the base embedding and the shift embedding. We conduct extensive experiments on two public datasets. The experimental results demonstrate both the effectiveness and the compatibility of CoMeta.
Who is Gambling? Finding Cryptocurrency Gamblers Using Multi-modal Retrieval Methods
Nov 27, 2022With the popularity of cryptocurrencies and the remarkable development of blockchain technology, decentralized applications emerged as a revolutionary force for the Internet. Meanwhile, decentralized applications have also attracted intense attention from the online gambling community, with more and more decentralized gambling platforms created through the help of smart contracts. Compared with conventional gambling platforms, decentralized gambling have transparent rules and a low participation threshold, attracting a substantial number of gamblers. In order to discover gambling behaviors and identify the contracts and addresses involved in gambling, we propose a tool termed ETHGamDet. The tool is able to automatically detect the smart contracts and addresses involved in gambling by scrutinizing the smart contract code and address transaction records. Interestingly, we present a novel LightGBM model with memory components, which possesses the ability to learn from its own misclassifications. As a side contribution, we construct and release a large-scale gambling dataset at https://github.com/AwesomeHuang/Bitcoin-Gambling-Dataset to facilitate future research in this field. Empirically, ETHGamDet achieves a F1-score of 0.72 and 0.89 in address classification and contract classification respectively, and offers novel and interesting insights.
Demystifying Bitcoin Address Behavior via Graph Neural Networks
Nov 26, 2022



Bitcoin is one of the decentralized cryptocurrencies powered by a peer-to-peer blockchain network. Parties who trade in the bitcoin network are not required to disclose any personal information. Such property of anonymity, however, precipitates potential malicious transactions to a certain extent. Indeed, various illegal activities such as money laundering, dark network trading, and gambling in the bitcoin network are nothing new now. While a proliferation of work has been developed to identify malicious bitcoin transactions, the behavior analysis and classification of bitcoin addresses are largely overlooked by existing tools. In this paper, we propose BAClassifier, a tool that can automatically classify bitcoin addresses based on their behaviors. Technically, we come up with the following three key designs. First, we consider casting the transactions of the bitcoin address into an address graph structure, of which we introduce a graph node compression technique and a graph structure augmentation method to characterize a unified graph representation. Furthermore, we leverage a graph feature network to learn the graph representations of each address and generate the graph embeddings. Finally, we aggregate all graph embeddings of an address into the address-level representation, and engage in a classification model to give the address behavior classification. As a side contribution, we construct and release a large-scale annotated dataset that consists of over 2 million real-world bitcoin addresses and concerns 4 types of address behaviors. Experimental results demonstrate that our proposed framework outperforms state-of-the-art bitcoin address classifiers and existing classification models, where the precision and F1-score are 96% and 95%, respectively. Our implementation and dataset are released, hoping to inspire others.
Poisoning Deep Learning based Recommender Model in Federated Learning Scenarios
Apr 26, 2022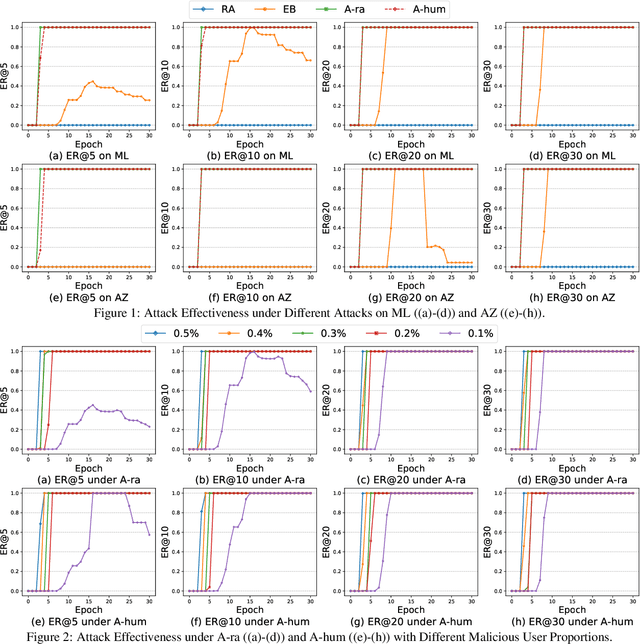
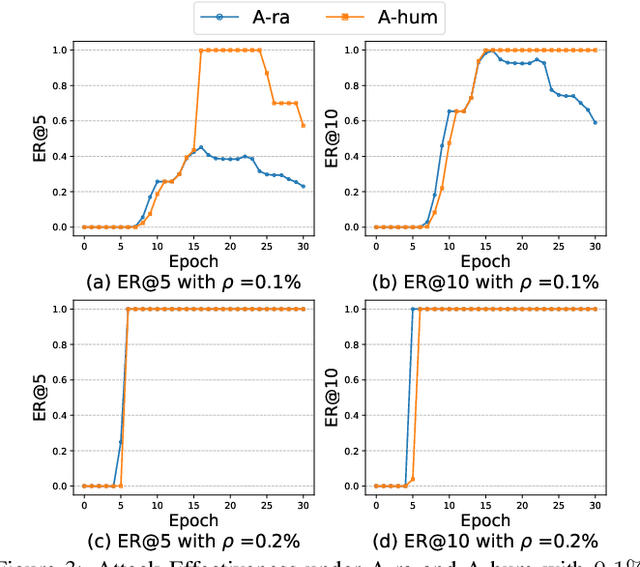
Various attack methods against recommender systems have been proposed in the past years, and the security issues of recommender systems have drawn considerable attention. Traditional attacks attempt to make target items recommended to as many users as possible by poisoning the training data. Benifiting from the feature of protecting users' private data, federated recommendation can effectively defend such attacks. Therefore, quite a few works have devoted themselves to developing federated recommender systems. For proving current federated recommendation is still vulnerable, in this work we probe to design attack approaches targeting deep learning based recommender models in federated learning scenarios. Specifically, our attacks generate poisoned gradients for manipulated malicious users to upload based on two strategies (i.e., random approximation and hard user mining). Extensive experiments show that our well-designed attacks can effectively poison the target models, and the attack effectiveness sets the state-of-the-art.
FedRecAttack: Model Poisoning Attack to Federated Recommendation
Apr 01, 2022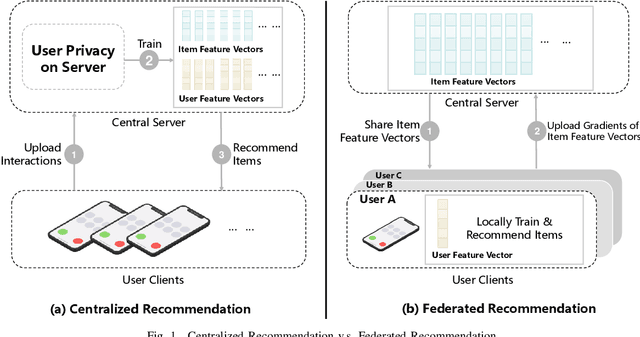
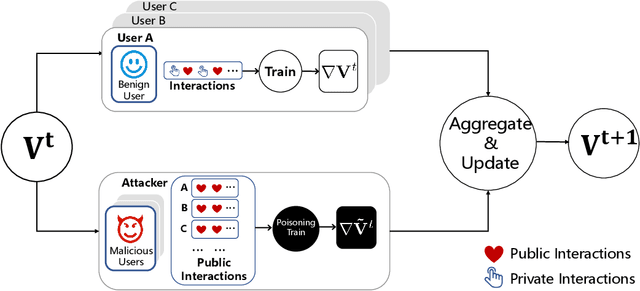
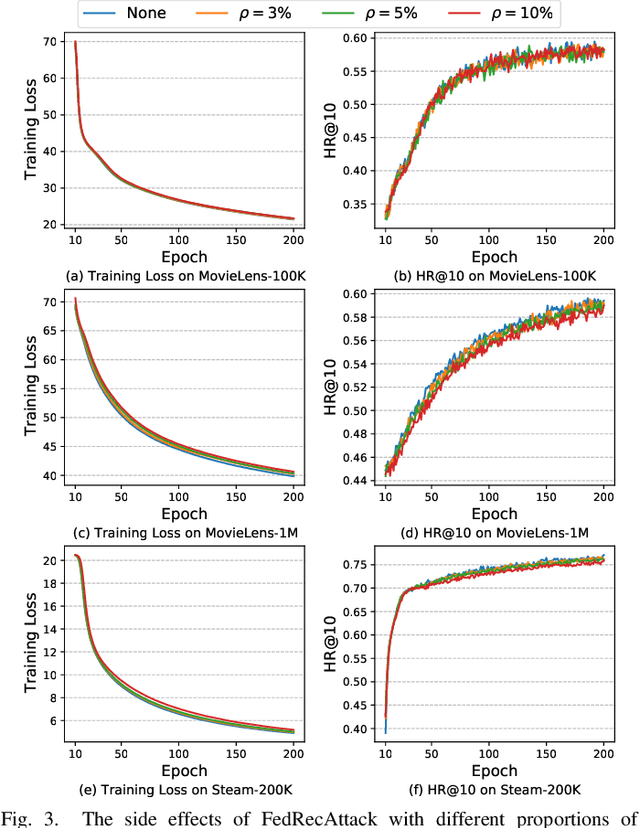

Federated Recommendation (FR) has received considerable popularity and attention in the past few years. In FR, for each user, its feature vector and interaction data are kept locally on its own client thus are private to others. Without the access to above information, most existing poisoning attacks against recommender systems or federated learning lose validity. Benifiting from this characteristic, FR is commonly considered fairly secured. However, we argue that there is still possible and necessary security improvement could be made in FR. To prove our opinion, in this paper we present FedRecAttack, a model poisoning attack to FR aiming to raise the exposure ratio of target items. In most recommendation scenarios, apart from private user-item interactions (e.g., clicks, watches and purchases), some interactions are public (e.g., likes, follows and comments). Motivated by this point, in FedRecAttack we make use of the public interactions to approximate users' feature vectors, thereby attacker can generate poisoned gradients accordingly and control malicious users to upload the poisoned gradients in a well-designed way. To evaluate the effectiveness and side effects of FedRecAttack, we conduct extensive experiments on three real-world datasets of different sizes from two completely different scenarios. Experimental results demonstrate that our proposed FedRecAttack achieves the state-of-the-art effectiveness while its side effects are negligible. Moreover, even with small proportion (3%) of malicious users and small proportion (1%) of public interactions, FedRecAttack remains highly effective, which reveals that FR is more vulnerable to attack than people commonly considered.