 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Prompt Compression for Large Language Models
Apr 24, 2025Prompt engineering enables Large Language Models (LLMs) to perform a variety of tasks. However, lengthy prompts significantly increase computational complexity and economic costs. To address this issue, we study six prompt compression methods for LLMs, aiming to reduce prompt length while maintaining LLM response quality. In this paper, we present a comprehensive analysis covering aspects such as generation performance, model hallucinations, efficacy in multimodal tasks, word omission analysis, and more. We evaluate these methods across 13 datasets, including news, scientific articles, commonsense QA, math QA, long-context QA, and VQA datasets. Our experiments reveal that prompt compression has a greater impact on LLM performance in long contexts compared to short ones. In the Longbench evaluation, moderate compression even enhances LLM performance. Our code and data is available at https://github.com/3DAgentWorld/Toolkit-for-Prompt-Compression.
The Other Side of the Coin: Exploring Fairness in Retrieval-Augmented Generation
Apr 19, 2025Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant document from external knowledge sources. By referencing this external knowledge, RAG effectively reduces the generation of factually incorrect content and addresses hallucination issues within LLMs. Recently, there has been growing attention to improving the performance and efficiency of RAG systems from various perspectives. While these advancements have yielded significant results, the application of RAG in domains with considerable societal implications raises a critical question about fairness: What impact does the introduction of the RAG paradigm have on the fairness of LLMs? To address this question, we conduct extensive experiments by varying the LLMs, retrievers, and retrieval sources. Our experimental analysis reveals that the scale of the LLMs plays a significant role in influencing fairness outcomes within the RAG framework. When the model scale is smaller than 8B, the integration of retrieval mechanisms often exacerbates unfairness in small-scale LLMs (e.g., LLaMA3.2-1B, Mistral-7B, and LLaMA3-8B). To mitigate the fairness issues introduced by RAG for small-scale LLMs, we propose two approaches, FairFT and FairFilter. Specifically, in FairFT, we align the retriever with the LLM in terms of fairness, enabling it to retrieve documents that facilitate fairer model outputs. In FairFilter, we propose a fairness filtering mechanism to filter out biased content after retrieval. Finally, we validate our proposed approaches on real-world datasets, demonstrating their effectiveness in improving fairness while maintaining performance.
Enhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
Apr 14, 2025



The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
DeepOHeat-v1: Efficient Operator Learning for Fast and Trustworthy Thermal Simulation and Optimization in 3D-IC Design
Apr 04, 2025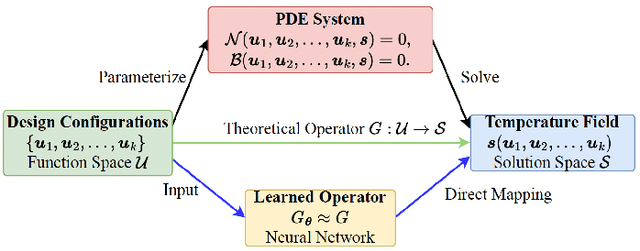

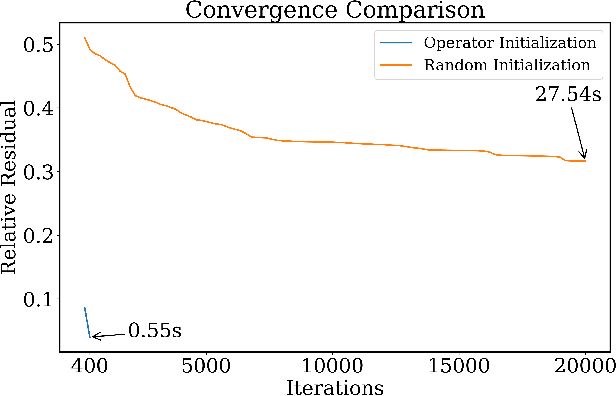

Thermal analysis is crucial in three-dimensional integrated circuit (3D-IC) design due to increased power density and complex heat dissipation paths. Although operator learning frameworks such as DeepOHeat have demonstrated promising preliminary results in accelerating thermal simulation, they face critical limitations in prediction capability for multi-scale thermal patterns, training efficiency, and trustworthiness of results during design optimization. This paper presents DeepOHeat-v1, an enhanced physics-informed operator learning framework that addresses these challenges through three key innovations. First, we integrate Kolmogorov-Arnold Networks with learnable activation functions as trunk networks, enabling an adaptive representation of multi-scale thermal patterns. This approach achieves a $1.25\times$ and $6.29\times$ reduction in error in two representative test cases. Second, we introduce a separable training method that decomposes the basis function along the coordinate axes, achieving $62\times$ training speedup and $31\times$ GPU memory reduction in our baseline case, and enabling thermal analysis at resolutions previously infeasible due to GPU memory constraints. Third, we propose a confidence score to evaluate the trustworthiness of the predicted results, and further develop a hybrid optimization workflow that combines operator learning with finite difference (FD) using Generalized Minimal Residual (GMRES) method for incremental solution refinement, enabling efficient and trustworthy thermal optimization. Experimental results demonstrate that DeepOHeat-v1 achieves accuracy comparable to optimization using high-fidelity finite difference solvers, while speeding up the entire optimization process by $70.6\times$ in our test cases, effectively minimizing the peak temperature through optimal placement of heat-generating components.
LLM for Complex Reasoning Task: An Exploratory Study in Fermi Problems
Apr 03, 2025Fermi Problems (FPs) are mathematical reasoning tasks that require human-like logic and numerical reasoning. Unlike other reasoning questions, FPs often involve real-world impracticalities or ambiguous concepts, making them challenging even for humans to solve. Despite advancements in AI, particularly with large language models (LLMs) in various reasoning tasks, FPs remain relatively under-explored. This work conducted an exploratory study to examine the capabilities and limitations of LLMs in solving FPs. We first evaluated the overall performance of three advanced LLMs using a publicly available FP dataset. We designed prompts according to the recently proposed TELeR taxonomy, including a zero-shot scenario. Results indicated that all three LLMs achieved a fp_score (range between 0 - 1) below 0.5, underscoring the inherent difficulty of these reasoning tasks. To further investigate, we categorized FPs into standard and specific questions, hypothesizing that LLMs would perform better on standard questions, which are characterized by clarity and conciseness, than on specific ones. Comparative experiments confirmed this hypothesis, demonstrating that LLMs performed better on standard FPs in terms of both accuracy and efficiency.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025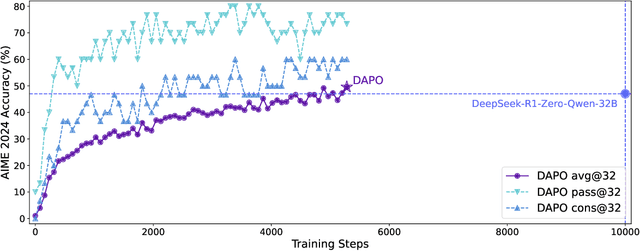

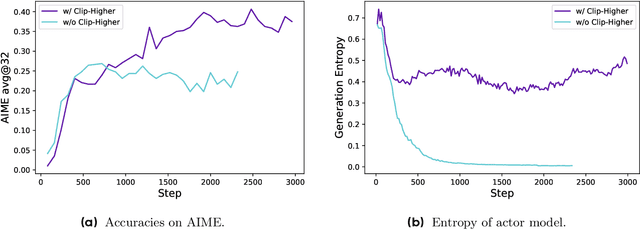

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
TT-GaussOcc: Test-Time Compute for Self-Supervised Occupancy Prediction via Spatio-Temporal Gaussian Splatting
Mar 11, 2025



Self-supervised 3D occupancy prediction offers a promising solution for understanding complex driving scenes without requiring costly 3D annotations. However, training dense voxel decoders to capture fine-grained geometry and semantics can demand hundreds of GPU hours, and such models often fail to adapt to varying voxel resolutions or new classes without extensive retraining. To overcome these limitations, we propose a practical and flexible test-time occupancy prediction framework termed TT-GaussOcc. Our approach incrementally optimizes time-aware 3D Gaussians instantiated from raw sensor streams at runtime, enabling voxelization at arbitrary user-specified resolution. Specifically, TT-GaussOcc operates in a "lift-move-voxel" symphony: we first "lift" surrounding-view semantics obtained from 2D vision foundation models (VLMs) to instantiate Gaussians at non-empty 3D space; Next, we "move" dynamic Gaussians from previous frames along estimated Gaussian scene flow to complete appearance and eliminate trailing artifacts of fast-moving objects, while accumulating static Gaussians to enforce temporal consistency; Finally, we mitigate inherent noises in semantic predictions and scene flow vectors by periodically smoothing neighboring Gaussians during optimization, using proposed trilateral RBF kernels that jointly consider color, semantic, and spatial affinities. The historical static and current dynamic Gaussians are then combined and voxelized to generate occupancy prediction. Extensive experiments on Occ3D and nuCraft with varying voxel resolutions demonstrate that TT-GaussOcc surpasses self-supervised baselines by 46% on mIoU without any offline training, and supports finer voxel resolutions at 2.6 FPS inference speed.
Wanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.