 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTORM: Internalized Modeling for Spatial-Temporal Reasoning in Video-Language Models
May 25, 2026Many video reasoning tasks require tracking motion, temporal order, and evolving visual states across frames. Existing methods built on large vision-language models (LVLMs) often address this challenge by externalizing reasoning through textual chain-of-thought (CoT), keyframe selection, repeated frame reinsertion, or external tool use. While effective, such pipelines increase inference-time latency and engineering complexity, and they force temporal-visual evidence to be serialized into text or repeatedly re-encoded from frames. Inspired by the intuition that visual reasoning can occur implicitly before verbalization, we propose STORMS (Spatial-Temporal reasOning via inteRnalized Modeling), a two-stage framework that teaches LVLMs to reason through bounded continuous latent trajectories instead of explicit textual CoT. In Stage I, STORMS aligns latent tokens with thought-video representations derived from generated videos, grounding the latent states in dynamic visual evidence. In Stage II, the model is further trained with answer-only supervision, encouraging the reasoning process to be internalized without step-by-step annotations. Generated thought videos are used only during training; at inference, STORMS performs a bounded latent rollout without regenerating videos, reinserting frames, or invoking external visual tools. Experiments on VideoMME, MVBench, TempCompass, and MMVU show that STORMS improves video reasoning accuracy while substantially reducing inference overhead compared with tool or video-generation-based reasoning pipelines.
Uncertainty-Guided Dual-Domain Learning for Reliable Skin Lesion Segmentation
May 10, 2026Accurate skin lesion segmentation is vital for dermoscopic Computer-Aided Diagnosis. However, visual ambiguity and morphological irregularity often defeat spatial modeling, necessitating multi-domain architectures. Existing paradigms frequently overlook the active use of prediction uncertainty, leading to deterministic frameworks that suffer from blind cross-domain fusion and overfit to label noise. To address these issues, we propose the Uncertainty-Guided Dual-Domain Network (UGDD-Net). UGDD-Net introduces a novel "Glance-and-Gaze" mechanism to transform uncertainty into an active guiding signal. Specifically, the Uncertainty-Guided Bi-directional Feature Fusion (UGBFF) module uses pixel-level uncertainty to modulate spatial-spectral interactions. The Uncertainty-Guided Graph Refinement (UGGR) module constructs a topology-aware graph to propagate reliable semantic consensus and refine uncertain nodes. Finally, the Uncertainty-Guided Margin-Adaptive Loss (UGML) enforces strict constraints on confident pixels while relaxing penalties on uncertain ones to improve statistical calibration. Extensive experiments on ISIC2017, ISIC2018, PH2, and HAM10000 datasets demonstrate that UGDD-Net achieves state-of-the-art performance, especially on "Hard Samples". Our uncertainty maps align with expert inter-observer variability, providing robust interpretability for human-machine collaborative diagnosis.
Physion-Eval: Evaluating Physical Realism in Generated Video via Human Reasoning
Mar 20, 2026Video generation models are increasingly used as world simulators for storytelling, simulation, and embodied AI. As these models advance, a key question arises: do generated videos obey the physical laws of the real world? Existing evaluations largely rely on automated metrics or coarse human judgments such as preferences or rubric-based checks. While useful for assessing perceptual quality, these methods provide limited insight into when and why generated dynamics violate real-world physical constraints. We introduce Physion-Eval, a large-scale benchmark of expert human reasoning for diagnosing physical realism failures in videos generated by five state-of-the-art models across egocentric and exocentric views, containing 10,990 expert reasoning traces spanning 22 fine-grained physical categories. Each generated video is derived from a corresponding real-world reference video depicting a clear physical process, and annotated with temporally localized glitches, structured failure categories, and natural-language explanations of the violated physical behavior. Using this dataset, we reveal a striking limitation of current video generation models: in physics-critical scenarios, 83.3% of exocentric and 93.5% of egocentric generated videos exhibit at least one human-identifiable physical glitch. We hope Physion-Eval will set a new standard for physical realism evaluation and guide the development of physics-grounded video generation. The benchmark is publicly available at https://huggingface.co/datasets/PhysionLabs/Physion-Eval.
VisRef: Visual Refocusing while Thinking Improves Test-Time Scaling in Multi-Modal Large Reasoning Models
Feb 27, 2026Advances in large reasoning models have shown strong performance on complex reasoning tasks by scaling test-time compute through extended reasoning. However, recent studies observe that in vision-dependent tasks, extended textual reasoning at inference time can degrade performance as models progressively lose attention to visual tokens and increasingly rely on textual priors alone. To address this, prior works use reinforcement learning (RL)-based fine-tuning to route visual tokens or employ refocusing mechanisms during reasoning. While effective, these methods are computationally expensive, requiring large-scale data generation and policy optimization. To leverage the benefits of test-time compute without additional RL fine-tuning, we propose VisRef, a visually grounded test-time scaling framework. Our key idea is to actively guide the reasoning process by re-injecting a coreset of visual tokens that are semantically relevant to the reasoning context while remaining diverse and globally representative of the image, enabling more grounded multi-modal reasoning. Experiments on three visual reasoning benchmarks with state-of-the-art multi-modal large reasoning models demonstrate that, under fixed test-time compute budgets, VisRef consistently outperforms existing test-time scaling approaches by up to 6.4%.
Towards Explicit Acoustic Evidence Perception in Audio LLMs for Speech Deepfake Detection
Jan 30, 2026Speech deepfake detection (SDD) focuses on identifying whether a given speech signal is genuine or has been synthetically generated. Existing audio large language model (LLM)-based methods excel in content understanding; however, their predictions are often biased toward semantically correlated cues, which results in fine-grained acoustic artifacts being overlooked during the decisionmaking process. Consequently, fake speech with natural semantics can bypass detectors despite harboring subtle acoustic anomalies; this suggests that the challenge stems not from the absence of acoustic data, but from its inadequate accessibility when semantic-dominant reasoning prevails. To address this issue, we investigate SDD within the audio LLM paradigm and introduce SDD with Auditory Perception-enhanced Audio Large Language Model (SDD-APALLM), an acoustically enhanced framework designed to explicitly expose fine-grained time-frequency evidence as accessible acoustic cues. By combining raw audio with structured spectrograms, the proposed framework empowers audio LLMs to more effectively capture subtle acoustic inconsistencies without compromising their semantic understanding. Experimental results indicate consistent gains in detection accuracy and robustness, especially in cases where semantic cues are misleading. Further analysis reveals that these improvements stem from a coordinated utilization of semantic and acoustic information, as opposed to simple modality aggregation.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025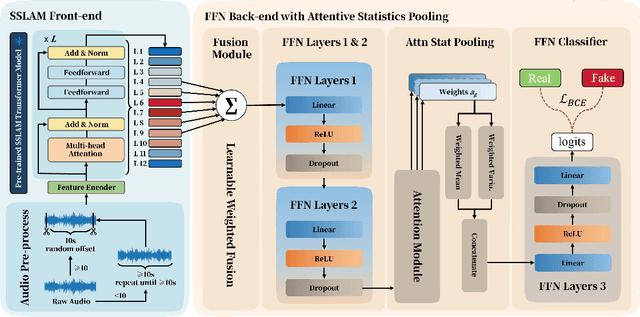
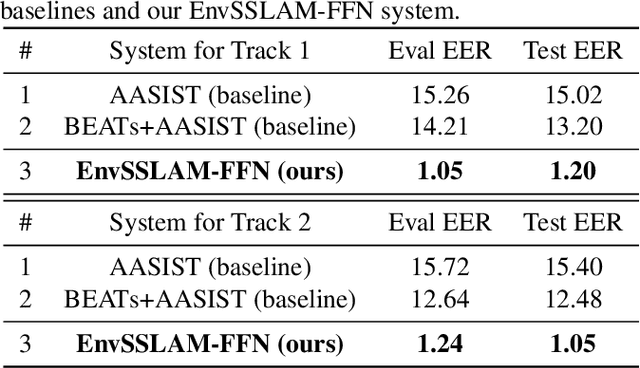
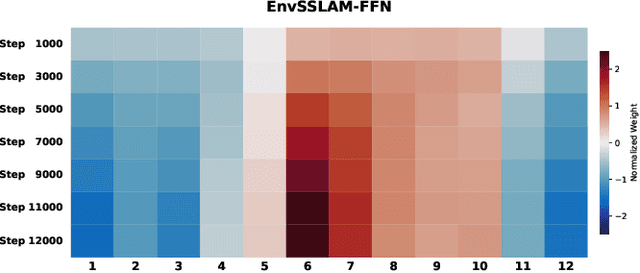
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.
AuthGuard: Generalizable Deepfake Detection via Language Guidance
Jun 04, 2025Existing deepfake detection techniques struggle to keep-up with the ever-evolving novel, unseen forgeries methods. This limitation stems from their reliance on statistical artifacts learned during training, which are often tied to specific generation processes that may not be representative of samples from new, unseen deepfake generation methods encountered at test time. We propose that incorporating language guidance can improve deepfake detection generalization by integrating human-like commonsense reasoning -- such as recognizing logical inconsistencies and perceptual anomalies -- alongside statistical cues. To achieve this, we train an expert deepfake vision encoder by combining discriminative classification with image-text contrastive learning, where the text is generated by generalist MLLMs using few-shot prompting. This allows the encoder to extract both language-describable, commonsense deepfake artifacts and statistical forgery artifacts from pixel-level distributions. To further enhance robustness, we integrate data uncertainty learning into vision-language contrastive learning, mitigating noise in image-text supervision. Our expert vision encoder seamlessly interfaces with an LLM, further enabling more generalized and interpretable deepfake detection while also boosting accuracy. The resulting framework, AuthGuard, achieves state-of-the-art deepfake detection accuracy in both in-distribution and out-of-distribution settings, achieving AUC gains of 6.15% on the DFDC dataset and 16.68% on the DF40 dataset. Additionally, AuthGuard significantly enhances deepfake reasoning, improving performance by 24.69% on the DDVQA dataset.
Ground-V: Teaching VLMs to Ground Complex Instructions in Pixels
May 20, 2025This work presents a simple yet effective workflow for automatically scaling instruction-following data to elicit pixel-level grounding capabilities of VLMs under complex instructions. In particular, we address five critical real-world challenges in text-instruction-based grounding: hallucinated references, multi-object scenarios, reasoning, multi-granularity, and part-level references. By leveraging knowledge distillation from a pre-trained teacher model, our approach generates high-quality instruction-response pairs linked to existing pixel-level annotations, minimizing the need for costly human annotation. The resulting dataset, Ground-V, captures rich object localization knowledge and nuanced pixel-level referring expressions. Experiment results show that models trained on Ground-V exhibit substantial improvements across diverse grounding tasks. Specifically, incorporating Ground-V during training directly achieves an average accuracy boost of 4.4% for LISA and a 7.9% for PSALM across six benchmarks on the gIoU metric. It also sets new state-of-the-art results on standard benchmarks such as RefCOCO/+/g. Notably, on gRefCOCO, we achieve an N-Acc of 83.3%, exceeding the previous state-of-the-art by more than 20%.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
Breaking the $\log(1/Δ_2)$ Barrier: Better Batched Best Arm Identification with Adaptive Grids
Jan 29, 2025

We investigate the problem of batched best arm identification in multi-armed bandits, where we aim to identify the best arm from a set of $n$ arms while minimizing both the number of samples and batches. We introduce an algorithm that achieves near-optimal sample complexity and features an instance-sensitive batch complexity, which breaks the $\log(1/\Delta_2)$ barrier. The main contribution of our algorithm is a novel sample allocation scheme that effectively balances exploration and exploitation for batch sizes. Experimental results indicate that our approach is more batch-efficient across various setups. We also extend this framework to the problem of batched best arm identification in linear bandits and achieve similar improvements.