 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Test-Time Scaling with Model-Free Speculative Sampling
Jun 05, 2025Language models have demonstrated remarkable capabilities in reasoning tasks through test-time scaling techniques like best-of-N sampling and tree search. However, these approaches often demand substantial computational resources, creating a critical trade-off between performance and efficiency. We introduce STAND (STochastic Adaptive N-gram Drafting), a novel model-free speculative decoding approach that leverages the inherent redundancy in reasoning trajectories to achieve significant acceleration without compromising accuracy. Our analysis reveals that reasoning paths frequently reuse similar reasoning patterns, enabling efficient model-free token prediction without requiring separate draft models. By introducing stochastic drafting and preserving probabilistic information through a memory-efficient logit-based N-gram module, combined with optimized Gumbel-Top-K sampling and data-driven tree construction, STAND significantly improves token acceptance rates. Extensive evaluations across multiple models and reasoning tasks (AIME-2024, GPQA-Diamond, and LiveCodeBench) demonstrate that STAND reduces inference latency by 60-65% compared to standard autoregressive decoding while maintaining accuracy. Furthermore, STAND outperforms state-of-the-art speculative decoding methods by 14-28% in throughput and shows strong performance even in single-trajectory scenarios, reducing inference latency by 48-58%. As a model-free approach, STAND can be applied to any existing language model without additional training, being a powerful plug-and-play solution for accelerating language model reasoning.
Wanda++: Pruning Large Language Models via Regional Gradients
Mar 06, 2025Large Language Models (LLMs) pruning seeks to remove unimportant weights for inference speedup with minimal performance impact. However, existing methods often suffer from performance loss without full-model sparsity-aware fine-tuning. This paper presents Wanda++, a novel pruning framework that outperforms the state-of-the-art methods by utilizing decoder-block-level \textbf{regional} gradients. Specifically, Wanda++ improves the pruning score with regional gradients for the first time and proposes an efficient regional optimization method to minimize pruning-induced output discrepancies between the dense and sparse decoder output. Notably, Wanda++ improves perplexity by up to 32\% over Wanda in the language modeling task and generalizes effectively to downstream tasks. Further experiments indicate our proposed method is orthogonal to sparsity-aware fine-tuning, where Wanda++ can be combined with LoRA fine-tuning to achieve a similar perplexity improvement as the Wanda method. The proposed method is lightweight, pruning a 7B LLaMA model in under 10 minutes on a single NVIDIA H100 GPU.
Exposing Privacy Gaps: Membership Inference Attack on Preference Data for LLM Alignment
Jul 08, 2024



Large Language Models (LLMs) have seen widespread adoption due to their remarkable natural language capabilities. However, when deploying them in real-world settings, it is important to align LLMs to generate texts according to acceptable human standards. Methods such as Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) have made significant progress in refining LLMs using human preference data. However, the privacy concerns inherent in utilizing such preference data have yet to be adequately studied. In this paper, we investigate the vulnerability of LLMs aligned using human preference datasets to membership inference attacks (MIAs), highlighting the shortcomings of previous MIA approaches with respect to preference data. Our study has two main contributions: first, we introduce a novel reference-based attack framework specifically for analyzing preference data called PREMIA (\uline{Pre}ference data \uline{MIA}); second, we provide empirical evidence that DPO models are more vulnerable to MIA compared to PPO models. Our findings highlight gaps in current privacy-preserving practices for LLM alignment.
Neural Word Decomposition Models for Abusive Language Detection
Oct 02, 2019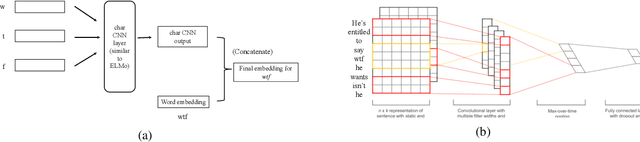
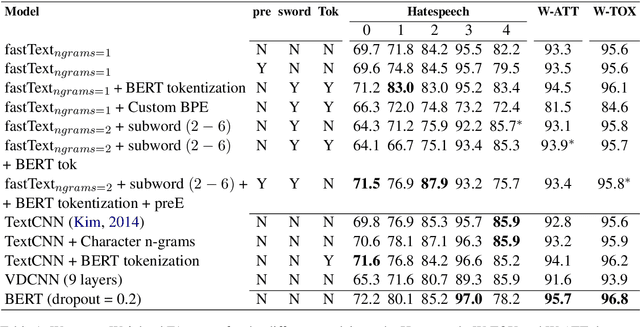
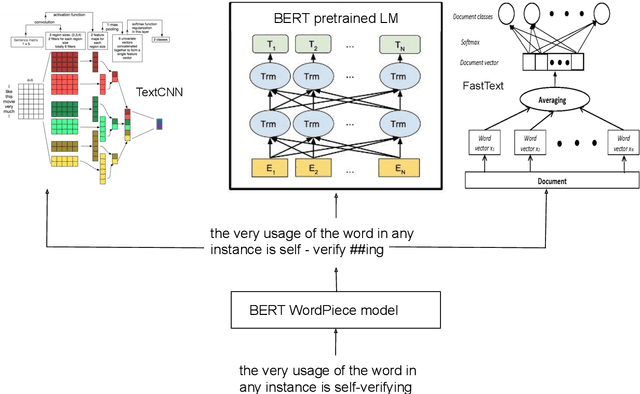
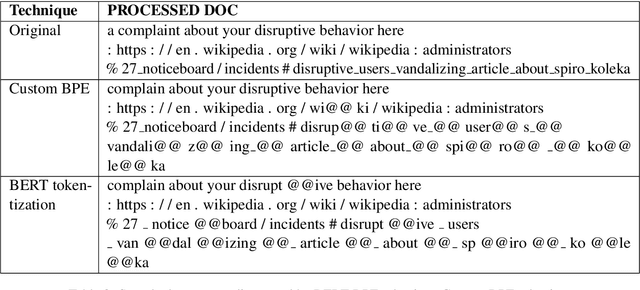
User generated text on social media often suffers from a lot of undesired characteristics including hatespeech, abusive language, insults etc. that are targeted to attack or abuse a specific group of people. Often such text is written differently compared to traditional text such as news involving either explicit mention of abusive words, obfuscated words and typological errors or implicit abuse i.e., indicating or targeting negative stereotypes. Thus, processing this text poses several robustness challenges when we apply natural language processing techniques developed for traditional text. For example, using word or token based models to process such text can treat two spelling variants of a word as two different words. Following recent work, we analyze how character, subword and byte pair encoding (BPE) models can be aid some of the challenges posed by user generated text. In our work, we analyze the effectiveness of each of the above techniques, compare and contrast various word decomposition techniques when used in combination with others. We experiment with finetuning large pretrained language models, and demonstrate their robustness to domain shift by studying Wikipedia attack, toxicity and Twitter hatespeech datasets
* Accepted at ALW Workshop at ACL2019, Florence; BERT has a WordPiece model and it enhances performance of word based models in noisy settings
Multi Sense Embeddings from Topic Models
Sep 17, 2019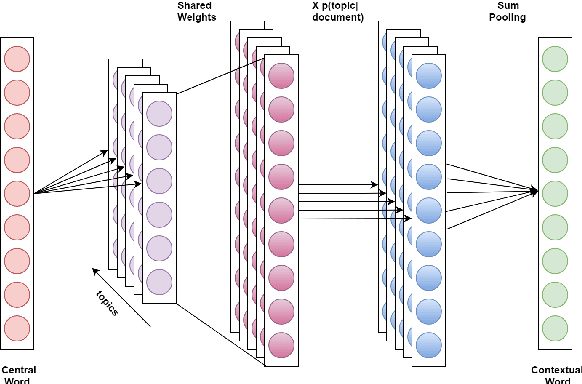
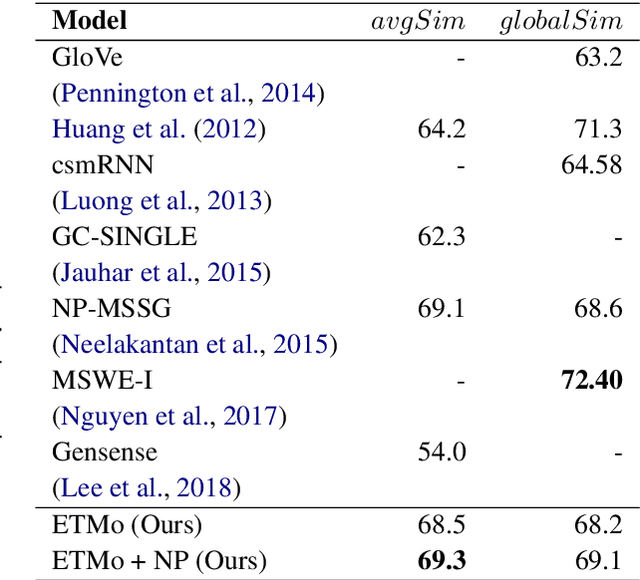
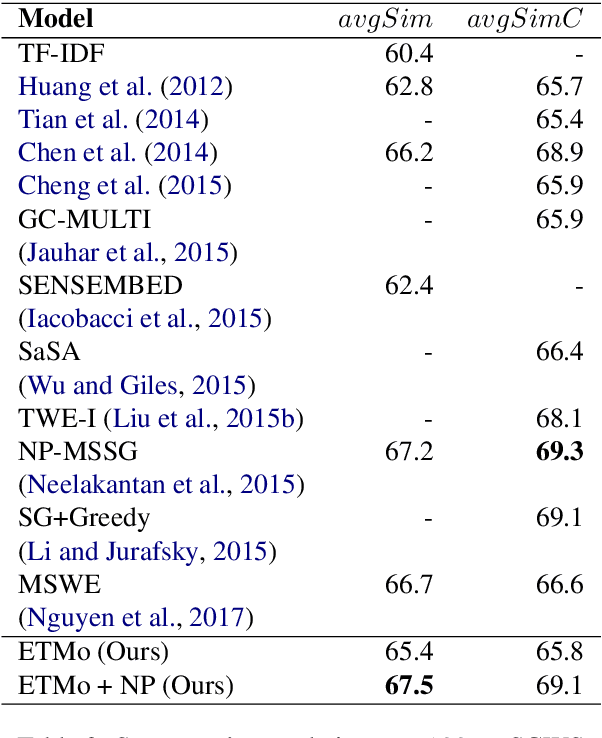

Distributed word embeddings have yielded state-of-the-art performance in many NLP tasks, mainly due to their success in capturing useful semantic information. These representations assign only a single vector to each word whereas a large number of words are polysemous (i.e., have multiple meanings). In this work, we approach this critical problem in lexical semantics, namely that of representing various senses of polysemous words in vector spaces. We propose a topic modeling based skip-gram approach for learning multi-prototype word embeddings. We also introduce a method to prune the embeddings determined by the probabilistic representation of the word in each topic. We use our embeddings to show that they can capture the context and word similarity strongly and outperform various state-of-the-art implementations.
* 8 pages, 1 figure, 7 tables