 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoma at SemEval-2025 Task 5: Aligning Librarian Records with OntoAligner for Subject Tagging
Apr 30, 2025



This paper presents our system, Homa, for SemEval-2025 Task 5: Subject Tagging, which focuses on automatically assigning subject labels to technical records from TIBKAT using the Gemeinsame Normdatei (GND) taxonomy. We leverage OntoAligner, a modular ontology alignment toolkit, to address this task by integrating retrieval-augmented generation (RAG) techniques. Our approach formulates the subject tagging problem as an alignment task, where records are matched to GND categories based on semantic similarity. We evaluate OntoAligner's adaptability for subject indexing and analyze its effectiveness in handling multilingual records. Experimental results demonstrate the strengths and limitations of this method, highlighting the potential of alignment techniques for improving subject tagging in digital libraries.
LLM for Complex Reasoning Task: An Exploratory Study in Fermi Problems
Apr 03, 2025Fermi Problems (FPs) are mathematical reasoning tasks that require human-like logic and numerical reasoning. Unlike other reasoning questions, FPs often involve real-world impracticalities or ambiguous concepts, making them challenging even for humans to solve. Despite advancements in AI, particularly with large language models (LLMs) in various reasoning tasks, FPs remain relatively under-explored. This work conducted an exploratory study to examine the capabilities and limitations of LLMs in solving FPs. We first evaluated the overall performance of three advanced LLMs using a publicly available FP dataset. We designed prompts according to the recently proposed TELeR taxonomy, including a zero-shot scenario. Results indicated that all three LLMs achieved a fp_score (range between 0 - 1) below 0.5, underscoring the inherent difficulty of these reasoning tasks. To further investigate, we categorized FPs into standard and specific questions, hypothesizing that LLMs would perform better on standard questions, which are characterized by clarity and conciseness, than on specific ones. Comparative experiments confirmed this hypothesis, demonstrating that LLMs performed better on standard FPs in terms of both accuracy and efficiency.
Towards Effective Authorship Attribution: Integrating Class-Incremental Learning
Aug 12, 2024AA is the process of attributing an unidentified document to its true author from a predefined group of known candidates, each possessing multiple samples. The nature of AA necessitates accommodating emerging new authors, as each individual must be considered unique. This uniqueness can be attributed to various factors, including their stylistic preferences, areas of expertise, gender, cultural background, and other personal characteristics that influence their writing. These diverse attributes contribute to the distinctiveness of each author, making it essential for AA systems to recognize and account for these variations. However, current AA benchmarks commonly overlook this uniqueness and frame the problem as a closed-world classification, assuming a fixed number of authors throughout the system's lifespan and neglecting the inclusion of emerging new authors. This oversight renders the majority of existing approaches ineffective for real-world applications of AA, where continuous learning is essential. These inefficiencies manifest as current models either resist learning new authors or experience catastrophic forgetting, where the introduction of new data causes the models to lose previously acquired knowledge. To address these inefficiencies, we propose redefining AA as CIL, where new authors are introduced incrementally after the initial training phase, allowing the system to adapt and learn continuously. To achieve this, we briefly examine subsequent CIL approaches introduced in other domains. Moreover, we have adopted several well-known CIL methods, along with an examination of their strengths and weaknesses in the context of AA. Additionally, we outline potential future directions for advancing CIL AA systems. As a result, our paper can serve as a starting point for evolving AA systems from closed-world models to continual learning through CIL paradigms.
OffLanDat: A Community Based Implicit Offensive Language Dataset Generated by Large Language Model Through Prompt Engineering
Mar 07, 2024



The widespread presence of offensive languages on social media has resulted in adverse effects on societal well-being. As a result, it has become very important to address this issue with high priority. Offensive languages exist in both explicit and implicit forms, with the latter being more challenging to detect. Current research in this domain encounters several challenges. Firstly, the existing datasets primarily rely on the collection of texts containing explicit offensive keywords, making it challenging to capture implicitly offensive contents that are devoid of these keywords. Secondly, usual methodologies tend to focus solely on textual analysis, neglecting the valuable insights that community information can provide. In this research paper, we introduce a novel dataset OffLanDat, a community based implicit offensive language dataset generated by ChatGPT containing data for 38 different target groups. Despite limitations in generating offensive texts using ChatGPT due to ethical constraints, we present a prompt-based approach that effectively generates implicit offensive languages. To ensure data quality, we evaluate our data with human. Additionally, we employ a prompt-based Zero-Shot method with ChatGPT and compare the detection results between human annotation and ChatGPT annotation. We utilize existing state-of-the-art models to see how effective they are in detecting such languages. We will make our code and dataset public for other researchers.
UoT-UWF-PartAI at SemEval-2021 Task 5: Self Attention Based Bi-GRU with Multi-Embedding Representation for Toxicity Highlighter
Apr 27, 2021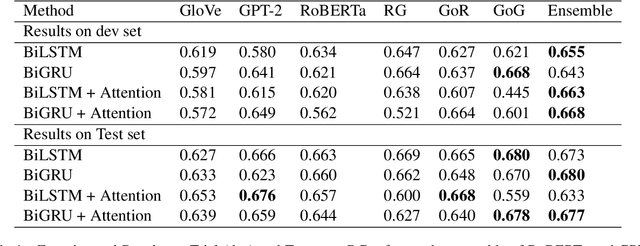
Toxic Spans Detection(TSD) task is defined as highlighting spans that make a text toxic. Many works have been done to classify a given comment or document as toxic or non-toxic. However, none of those proposed models work at the token level. In this paper, we propose a self-attention-based bidirectional gated recurrent unit(BiGRU) with a multi-embedding representation of the tokens. Our proposed model enriches the representation by a combination of GPT-2, GloVe, and RoBERTa embeddings, which led to promising results. Experimental results show that our proposed approach is very effective in detecting span tokens.