 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
MDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.
Oedipus and the Sphinx: Benchmarking and Improving Visual Language Models for Complex Graphic Reasoning
Aug 01, 2025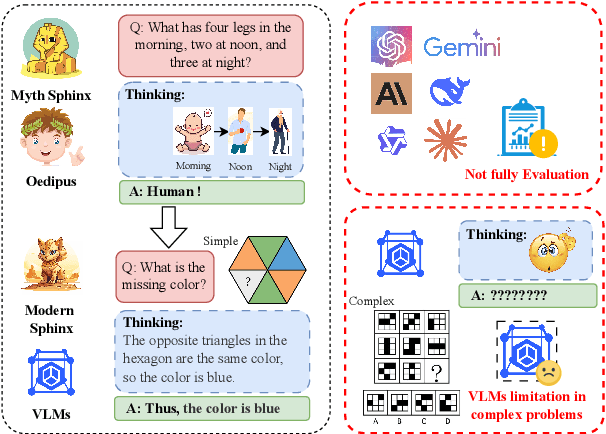



Evaluating the performance of visual language models (VLMs) in graphic reasoning tasks has become an important research topic. However, VLMs still show obvious deficiencies in simulating human-level graphic reasoning capabilities, especially in complex graphic reasoning and abstract problem solving, which are less studied and existing studies only focus on simple graphics. To evaluate the performance of VLMs in complex graphic reasoning, we propose ReasonBench, the first evaluation benchmark focused on structured graphic reasoning tasks, which includes 1,613 questions from real-world intelligence tests. ReasonBench covers reasoning dimensions related to location, attribute, quantity, and multi-element tasks, providing a comprehensive evaluation of the performance of VLMs in spatial, relational, and abstract reasoning capabilities. We benchmark 11 mainstream VLMs (including closed-source and open-source models) and reveal significant limitations of current models. Based on these findings, we propose a dual optimization strategy: Diagrammatic Reasoning Chain (DiaCoT) enhances the interpretability of reasoning by decomposing layers, and ReasonTune enhances the task adaptability of model reasoning through training, all of which improves VLM performance by 33.5\%. All experimental data and code are in the repository: https://huggingface.co/datasets/cistine/ReasonBench.
T2VParser: Adaptive Decomposition Tokens for Partial Alignment in Text to Video Retrieval
Jul 28, 2025



Text-to-video retrieval essentially aims to train models to align visual content with textual descriptions accurately. Due to the impressive general multimodal knowledge demonstrated by image-text pretrained models such as CLIP, existing work has primarily focused on extending CLIP knowledge for video-text tasks. However, videos typically contain richer information than images. In current video-text datasets, textual descriptions can only reflect a portion of the video content, leading to partial misalignment in video-text matching. Therefore, directly aligning text representations with video representations can result in incorrect supervision, ignoring the inequivalence of information. In this work, we propose T2VParser to extract multiview semantic representations from text and video, achieving adaptive semantic alignment rather than aligning the entire representation. To extract corresponding representations from different modalities, we introduce Adaptive Decomposition Tokens, which consist of a set of learnable tokens shared across modalities. The goal of T2VParser is to emphasize precise alignment between text and video while retaining the knowledge of pretrained models. Experimental results demonstrate that T2VParser achieves accurate partial alignment through effective cross-modal content decomposition. The code is available at https://github.com/Lilidamowang/T2VParser.
Yume: An Interactive World Generation Model
Jul 23, 2025



Yume aims to use images, text, or videos to create an interactive, realistic, and dynamic world, which allows exploration and control using peripheral devices or neural signals. In this report, we present a preview version of \method, which creates a dynamic world from an input image and allows exploration of the world using keyboard actions. To achieve this high-fidelity and interactive video world generation, we introduce a well-designed framework, which consists of four main components, including camera motion quantization, video generation architecture, advanced sampler, and model acceleration. First, we quantize camera motions for stable training and user-friendly interaction using keyboard inputs. Then, we introduce the Masked Video Diffusion Transformer~(MVDT) with a memory module for infinite video generation in an autoregressive manner. After that, training-free Anti-Artifact Mechanism (AAM) and Time Travel Sampling based on Stochastic Differential Equations (TTS-SDE) are introduced to the sampler for better visual quality and more precise control. Moreover, we investigate model acceleration by synergistic optimization of adversarial distillation and caching mechanisms. We use the high-quality world exploration dataset \sekai to train \method, and it achieves remarkable results in diverse scenes and applications. All data, codebase, and model weights are available on https://github.com/stdstu12/YUME. Yume will update monthly to achieve its original goal. Project page: https://stdstu12.github.io/YUME-Project/.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
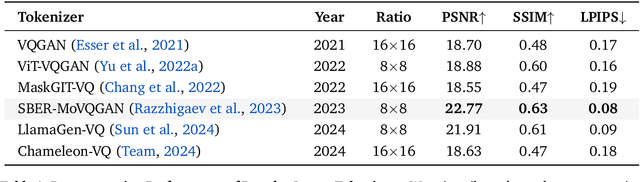
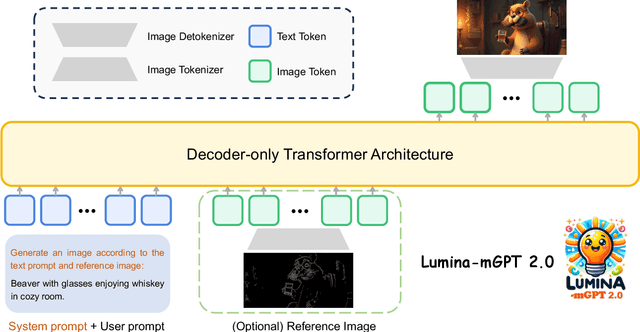

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
SkyVLN: Vision-and-Language Navigation and NMPC Control for UAVs in Urban Environments
Jul 09, 2025



Unmanned Aerial Vehicles (UAVs) have emerged as versatile tools across various sectors, driven by their mobility and adaptability. This paper introduces SkyVLN, a novel framework integrating vision-and-language navigation (VLN) with Nonlinear Model Predictive Control (NMPC) to enhance UAV autonomy in complex urban environments. Unlike traditional navigation methods, SkyVLN leverages Large Language Models (LLMs) to interpret natural language instructions and visual observations, enabling UAVs to navigate through dynamic 3D spaces with improved accuracy and robustness. We present a multimodal navigation agent equipped with a fine-grained spatial verbalizer and a history path memory mechanism. These components allow the UAV to disambiguate spatial contexts, handle ambiguous instructions, and backtrack when necessary. The framework also incorporates an NMPC module for dynamic obstacle avoidance, ensuring precise trajectory tracking and collision prevention. To validate our approach, we developed a high-fidelity 3D urban simulation environment using AirSim, featuring realistic imagery and dynamic urban elements. Extensive experiments demonstrate that SkyVLN significantly improves navigation success rates and efficiency, particularly in new and unseen environments.
Sekai: A Video Dataset towards World Exploration
Jun 18, 2025Video generation techniques have made remarkable progress, promising to be the foundation of interactive world exploration. However, existing video generation datasets are not well-suited for world exploration training as they suffer from some limitations: limited locations, short duration, static scenes, and a lack of annotations about exploration and the world. In this paper, we introduce Sekai (meaning ``world'' in Japanese), a high-quality first-person view worldwide video dataset with rich annotations for world exploration. It consists of over 5,000 hours of walking or drone view (FPV and UVA) videos from over 100 countries and regions across 750 cities. We develop an efficient and effective toolbox to collect, pre-process and annotate videos with location, scene, weather, crowd density, captions, and camera trajectories. Experiments demonstrate the quality of the dataset. And, we use a subset to train an interactive video world exploration model, named YUME (meaning ``dream'' in Japanese). We believe Sekai will benefit the area of video generation and world exploration, and motivate valuable applications.
RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
Jun 16, 2025



Accurate road topology reasoning is critical for autonomous driving, enabling effective navigation and adherence to traffic regulations. Central to this task are lane perception and topology reasoning. However, existing methods typically focus on either lane detection or Lane-to-Lane (L2L) topology reasoning, often \textit{neglecting} Lane-to-Traffic-element (L2T) relationships or \textit{failing} to optimize these tasks jointly. Furthermore, most approaches either overlook relational modeling or apply it in a limited scope, despite the inherent spatial relationships among road elements. We argue that relational modeling is beneficial for both perception and reasoning, as humans naturally leverage contextual relationships for road element recognition and their connectivity inference. To this end, we introduce relational modeling into both perception and reasoning, \textit{jointly} enhancing structural understanding. Specifically, we propose: 1) a relation-aware lane detector, where our geometry-biased self-attention and \curve\ cross-attention refine lane representations by capturing relational dependencies; 2) relation-enhanced topology heads, including a geometry-enhanced L2L head and a cross-view L2T head, boosting reasoning with relational cues; and 3) a contrastive learning strategy with InfoNCE loss to regularize relationship embeddings. Extensive experiments on OpenLane-V2 demonstrate that our approach significantly improves both detection and topology reasoning metrics, achieving +3.1 in DET$_l$, +5.3 in TOP$_{ll}$, +4.9 in TOP$_{lt}$, and an overall +4.4 in OLS, setting a new state-of-the-art. Code will be released.