 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Localization and Synthesis - Datasets, Challenges and Opportunities
Oct 26, 2025Cross-view localization and synthesis are two fundamental tasks in cross-view visual understanding, which deals with cross-view datasets: overhead (satellite or aerial) and ground-level imagery. These tasks have gained increasing attention due to their broad applications in autonomous navigation, urban planning, and augmented reality. Cross-view localization aims to estimate the geographic position of ground-level images based on information provided by overhead imagery while cross-view synthesis seeks to generate ground-level images based on information from the overhead imagery. Both tasks remain challenging due to significant differences in viewing perspective, resolution, and occlusion, which are widely embedded in cross-view datasets. Recent years have witnessed rapid progress driven by the availability of large-scale datasets and novel approaches. Typically, cross-view localization is formulated as an image retrieval problem where ground-level features are matched with tiled overhead images feature, extracted by convolutional neural networks (CNNs) or vision transformers (ViTs) for cross-view feature embedding. Cross-view synthesis, on the other hand, seeks to generate ground-level views based on information from overhead imagery, generally using generative adversarial networks (GANs) or diffusion models. This paper presents a comprehensive survey of advances in cross-view localization and synthesis, reviewing widely used datasets, highlighting key challenges, and providing an organized overview of state-of-the-art techniques. Furthermore, it discusses current limitations, offers comparative analyses, and outlines promising directions for future research. We also include the project page via https://github.com/GDAOSU/Awesome-Cross-View-Methods.
Deep learning for 3D point cloud processing -- from approaches, tasks to its implications on urban and environmental applications
Sep 15, 2025Point cloud processing as a fundamental task in the field of geomatics and computer vision, has been supporting tasks and applications at different scales from air to ground, including mapping, environmental monitoring, urban/tree structure modeling, automated driving, robotics, disaster responses etc. Due to the rapid development of deep learning, point cloud processing algorithms have nowadays been almost explicitly dominated by learning-based approaches, most of which are yet transitioned into real-world practices. Existing surveys primarily focus on the ever-updating network architecture to accommodate unordered point clouds, largely ignoring their practical values in typical point cloud processing applications, in which extra-large volume of data, diverse scene contents, varying point density, data modality need to be considered. In this paper, we provide a meta review on deep learning approaches and datasets that cover a selection of critical tasks of point cloud processing in use such as scene completion, registration, semantic segmentation, and modeling. By reviewing a broad range of urban and environmental applications these tasks can support, we identify gaps to be closed as these methods transformed into applications and draw concluding remarks in both the algorithmic and practical aspects of the surveyed methods.
Satellite to GroundScape -- Large-scale Consistent Ground View Generation from Satellite Views
Apr 22, 2025



Generating consistent ground-view images from satellite imagery is challenging, primarily due to the large discrepancies in viewing angles and resolution between satellite and ground-level domains. Previous efforts mainly concentrated on single-view generation, often resulting in inconsistencies across neighboring ground views. In this work, we propose a novel cross-view synthesis approach designed to overcome these challenges by ensuring consistency across ground-view images generated from satellite views. Our method, based on a fixed latent diffusion model, introduces two conditioning modules: satellite-guided denoising, which extracts high-level scene layout to guide the denoising process, and satellite-temporal denoising, which captures camera motion to maintain consistency across multiple generated views. We further contribute a large-scale satellite-ground dataset containing over 100,000 perspective pairs to facilitate extensive ground scene or video generation. Experimental results demonstrate that our approach outperforms existing methods on perceptual and temporal metrics, achieving high photorealism and consistency in multi-view outputs.
Skyeyes: Ground Roaming using Aerial View Images
Sep 25, 2024



Integrating aerial imagery-based scene generation into applications like autonomous driving and gaming enhances realism in 3D environments, but challenges remain in creating detailed content for occluded areas and ensuring real-time, consistent rendering. In this paper, we introduce Skyeyes, a novel framework that can generate photorealistic sequences of ground view images using only aerial view inputs, thereby creating a ground roaming experience. More specifically, we combine a 3D representation with a view consistent generation model, which ensures coherence between generated images. This method allows for the creation of geometrically consistent ground view images, even with large view gaps. The images maintain improved spatial-temporal coherence and realism, enhancing scene comprehension and visualization from aerial perspectives. To the best of our knowledge, there are no publicly available datasets that contain pairwise geo-aligned aerial and ground view imagery. Therefore, we build a large, synthetic, and geo-aligned dataset using Unreal Engine. Both qualitative and quantitative analyses on this synthetic dataset display superior results compared to other leading synthesis approaches. See the project page for more results: https://chaoren2357.github.io/website-skyeyes/.
Geospecific View Generation -- Geometry-Context Aware High-resolution Ground View Inference from Satellite Views
Jul 10, 2024



Predicting realistic ground views from satellite imagery in urban scenes is a challenging task due to the significant view gaps between satellite and ground-view images. We propose a novel pipeline to tackle this challenge, by generating geospecifc views that maximally respect the weak geometry and texture from multi-view satellite images. Different from existing approaches that hallucinate images from cues such as partial semantics or geometry from overhead satellite images, our method directly predicts ground-view images at geolocation by using a comprehensive set of information from the satellite image, resulting in ground-level images with a resolution boost at a factor of ten or more. We leverage a novel building refinement method to reduce geometric distortions in satellite data at ground level, which ensures the creation of accurate conditions for view synthesis using diffusion networks. Moreover, we proposed a novel geospecific prior, which prompts distribution learning of diffusion models to respect image samples that are closer to the geolocation of the predicted images. We demonstrate our pipeline is the first to generate close-to-real and geospecific ground views merely based on satellite images.
Large-scale DSM registration via motion averaging
Jun 02, 2024



Generating wide-area digital surface models (DSMs) requires registering a large number of individual, and partially overlapped DSMs. This presents a challenging problem for a typical registration algorithm, since when a large number of observations from these multiple DSMs are considered, it may easily cause memory overflow. Sequential registration algorithms, although can significantly reduce the computation, are especially vulnerable for small overlapped pairs, leading to a large error accumulation. In this work, we propose a novel solution that builds the DSM registration task as a motion averaging problem: pair-wise DSMs are registered to build a scene graph, with edges representing relative poses between DSMs. Specifically, based on the grid structure of the large DSM, the pair-wise registration is performed using a novel nearest neighbor search method. We show that the scene graph can be optimized via an extremely fast motion average algorithm with O(N) complexity (N refers to the number of images). Evaluation of high-resolution satellite-derived DSM demonstrates significant improvement in computation and accuracy.
* 9 Figures
Enabling Neural Radiance Fields (NeRF) for Large-scale Aerial Images -- A Multi-tiling Approach and the Geometry Assessment of NeRF
Oct 17, 2023



Neural Radiance Fields (NeRF) offer the potential to benefit 3D reconstruction tasks, including aerial photogrammetry. However, the scalability and accuracy of the inferred geometry are not well-documented for large-scale aerial assets,since such datasets usually result in very high memory consumption and slow convergence.. In this paper, we aim to scale the NeRF on large-scael aerial datasets and provide a thorough geometry assessment of NeRF. Specifically, we introduce a location-specific sampling technique as well as a multi-camera tiling (MCT) strategy to reduce memory consumption during image loading for RAM, representation training for GPU memory, and increase the convergence rate within tiles. MCT decomposes a large-frame image into multiple tiled images with different camera models, allowing these small-frame images to be fed into the training process as needed for specific locations without a loss of accuracy. We implement our method on a representative approach, Mip-NeRF, and compare its geometry performance with threephotgrammetric MVS pipelines on two typical aerial datasets against LiDAR reference data. Both qualitative and quantitative results suggest that the proposed NeRF approach produces better completeness and object details than traditional approaches, although as of now, it still falls short in terms of accuracy.
Point Cloud Registration for LiDAR and Photogrammetric Data: a Critical Synthesis and Performance Analysis on Classic and Deep Learning Algorithms
Feb 14, 2023



Recent advances in computer vision and deep learning have shown promising performance in estimating rigid/similarity transformation between unregistered point clouds of complex objects and scenes. However, their performances are mostly evaluated using a limited number of datasets from a single sensor (e.g. Kinect or RealSense cameras), lacking a comprehensive overview of their applicability in photogrammetric 3D mapping scenarios. In this work, we provide a comprehensive review of the state-of-the-art (SOTA) point cloud registration methods, where we analyze and evaluate these methods using a diverse set of point cloud data from indoor to satellite sources. The quantitative analysis allows for exploring the strengths, applicability, challenges, and future trends of these methods. In contrast to existing analysis works that introduce point cloud registration as a holistic process, our experimental analysis is based on its inherent two-step process to better comprehend these approaches including feature/keypoint-based initial coarse registration and dense fine registration through cloud-to-cloud (C2C) optimization. More than ten methods, including classic hand-crafted, deep-learning-based feature correspondence, and robust C2C methods were tested. We observed that the success rate of most of the algorithms are fewer than 40% over the datasets we tested and there are still are large margin of improvement upon existing algorithms concerning 3D sparse corresopondence search, and the ability to register point clouds with complex geometry and occlusions. With the evaluated statistics on three datasets, we conclude the best-performing methods for each step and provide our recommendations, and outlook future efforts.
A volumetric change detection framework using UAV oblique photogrammetry - A case study of ultra-high-resolution monitoring of progressive building collapse
Aug 05, 2021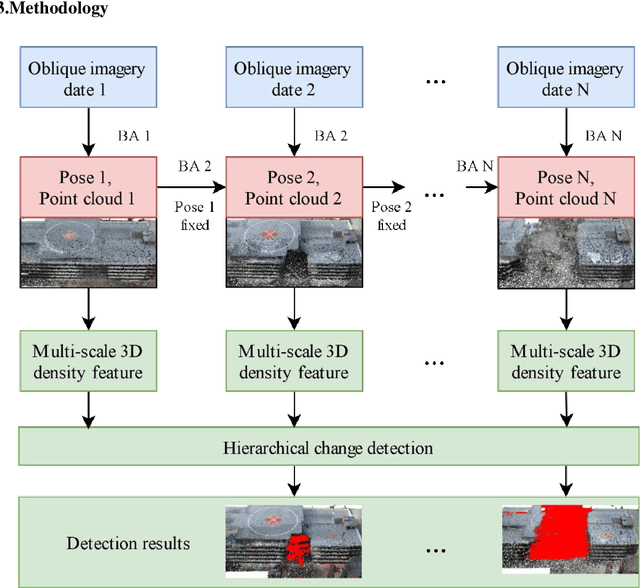

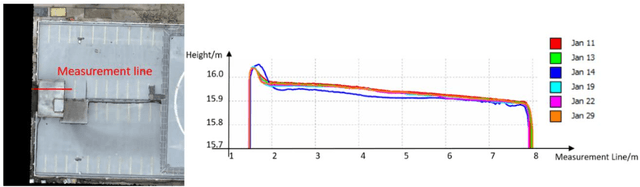
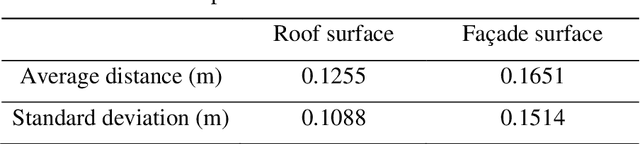
In this paper, we present a case study that performs an unmanned aerial vehicle (UAV) based fine-scale 3D change detection and monitoring of progressive collapse performance of a building during a demolition event. Multi-temporal oblique photogrammetry images are collected with 3D point clouds generated at different stages of the demolition. The geometric accuracy of the generated point clouds has been evaluated against both airborne and terrestrial LiDAR point clouds, achieving an average distance of 12 cm and 16 cm for roof and facade respectively. We propose a hierarchical volumetric change detection framework that unifies multi-temporal UAV images for pose estimation (free of ground control points), reconstruction, and a coarse-to-fine 3D density change analysis. This work has provided a solution capable of addressing change detection on full 3D time-series datasets where dramatic scene content changes are presented progressively. Our change detection results on the building demolition event have been evaluated against the manually marked ground-truth changes and have achieved an F-1 score varying from 0.78 to 0.92, with consistently high precision (0.92 - 0.99). Volumetric changes through the demolition progress are derived from change detection and have shown to favorably reflect the qualitative and quantitative building demolition progression.