 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2VParser: Adaptive Decomposition Tokens for Partial Alignment in Text to Video Retrieval
Jul 28, 2025



Text-to-video retrieval essentially aims to train models to align visual content with textual descriptions accurately. Due to the impressive general multimodal knowledge demonstrated by image-text pretrained models such as CLIP, existing work has primarily focused on extending CLIP knowledge for video-text tasks. However, videos typically contain richer information than images. In current video-text datasets, textual descriptions can only reflect a portion of the video content, leading to partial misalignment in video-text matching. Therefore, directly aligning text representations with video representations can result in incorrect supervision, ignoring the inequivalence of information. In this work, we propose T2VParser to extract multiview semantic representations from text and video, achieving adaptive semantic alignment rather than aligning the entire representation. To extract corresponding representations from different modalities, we introduce Adaptive Decomposition Tokens, which consist of a set of learnable tokens shared across modalities. The goal of T2VParser is to emphasize precise alignment between text and video while retaining the knowledge of pretrained models. Experimental results demonstrate that T2VParser achieves accurate partial alignment through effective cross-modal content decomposition. The code is available at https://github.com/Lilidamowang/T2VParser.
ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification
Feb 19, 2022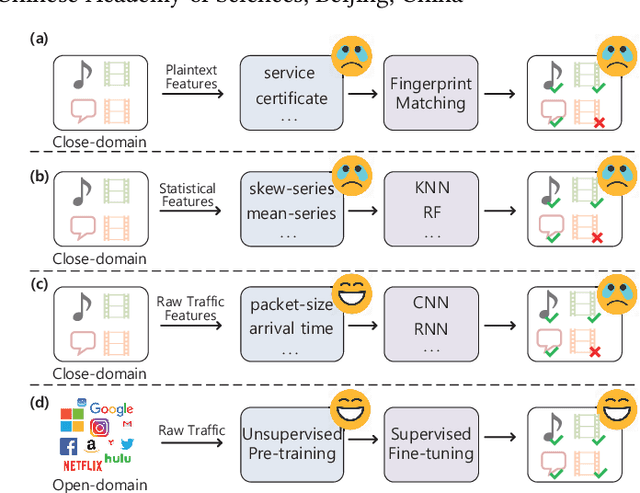
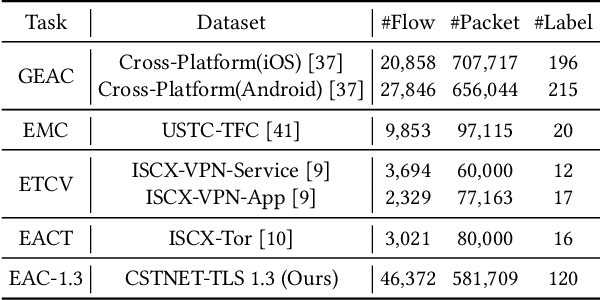
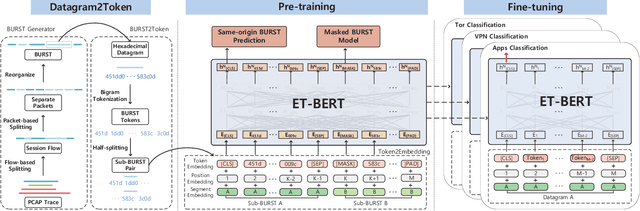
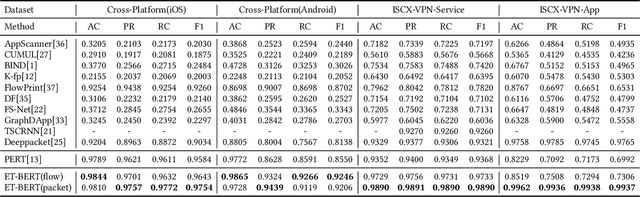
Encrypted traffic classification requires discriminative and robust traffic representation captured from content-invisible and imbalanced traffic data for accurate classification, which is challenging but indispensable to achieve network security and network management. The major limitation of existing solutions is that they highly rely on the deep features, which are overly dependent on data size and hard to generalize on unseen data. How to leverage the open-domain unlabeled traffic data to learn representation with strong generalization ability remains a key challenge. In this paper,we propose a new traffic representation model called Encrypted Traffic Bidirectional Encoder Representations from Transformer (ET-BERT), which pre-trains deep contextualized datagram-level representation from large-scale unlabeled data. The pre-trained model can be fine-tuned on a small number of task-specific labeled data and achieves state-of-the-art performance across five encrypted traffic classification tasks, remarkably pushing the F1 of ISCX-Tor to 99.2% (4.4% absolute improvement), ISCX-VPN-Service to 98.9% (5.2% absolute improvement), Cross-Platform (Android) to 92.5% (5.4% absolute improvement), CSTNET-TLS 1.3 to 97.4% (10.0% absolute improvement). Notably, we provide explanation of the empirically powerful pre-training model by analyzing the randomness of ciphers. It gives us insights in understanding the boundary of classification ability over encrypted traffic. The code is available at: https://github.com/linwhitehat/ET-BERT.
6VecLM: Language Modeling in Vector Space for IPv6 Target Generation
Aug 05, 2020
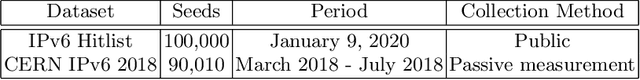
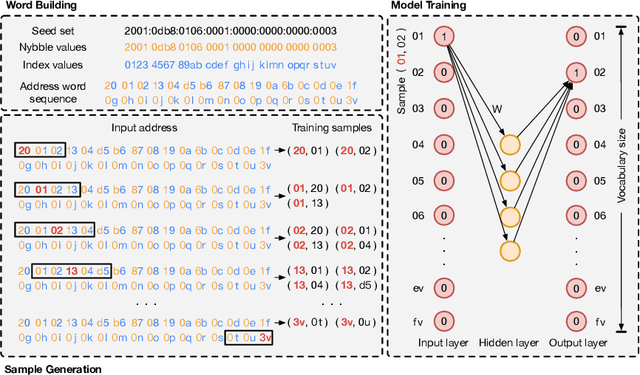
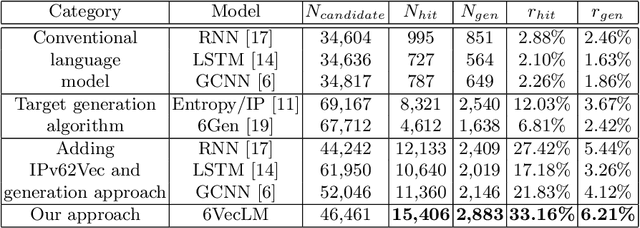
Fast IPv6 scanning is challenging in the field of network measurement as it requires exploring the whole IPv6 address space but limited by current computational power. Researchers propose to obtain possible active target candidate sets to probe by algorithmically analyzing the active seed sets. However, IPv6 addresses lack semantic information and contain numerous addressing schemes, leading to the difficulty of designing effective algorithms. In this paper, we introduce our approach 6VecLM to explore achieving such target generation algorithms. The architecture can map addresses into a vector space to interpret semantic relationships and uses a Transformer network to build IPv6 language models for predicting address sequence. Experiments indicate that our approach can perform semantic classification on address space. By adding a new generation approach, our model possesses a controllable word innovation capability compared to conventional language models. The work outperformed the state-of-the-art target generation algorithms on two active address datasets by reaching more quality candidate sets.