 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliev3R: Relieving Feed-forward Reconstruction from Multi-View Geometric Annotations
Apr 01, 2026With recent advances, Feed-forward Reconstruction Models (FFRMs) have demonstrated great potential in reconstruction quality and adaptiveness to multiple downstream tasks. However, the excessive reliance on multi-view geometric annotations, e.g. 3D point maps and camera poses, makes the fully-supervised training scheme of FFRMs difficult to scale up. In this paper, we propose Reliev3R, a weakly-supervised paradigm for training FFRMs from scratch without cost-prohibitive multi-view geometric annotations. Relieving the reliance on geometric sensory data and compute-exhaustive structure-from-motion preprocessing, our method draws 3D knowledge directly from monocular relative depths and image sparse correspondences given by zero-shot predictions of pretrained models. At the core of Reliev3R, we design an ambiguity-aware relative depth loss and a trigonometry-based reprojection loss to facilitate supervision for multi-view geometric consistency. Training from scratch with the less data, Reliev3R catches up with its fully-supervised sibling models, taking a step towards low-cost 3D reconstruction supervisions and scalable FFRMs.
Monocular Open Vocabulary Occupancy Prediction for Indoor Scenes
Feb 26, 2026Open-vocabulary 3D occupancy is vital for embodied agents, which need to understand complex indoor environments where semantic categories are abundant and evolve beyond fixed taxonomies. While recent work has explored open-vocabulary occupancy in outdoor driving scenarios, such methods transfer poorly indoors, where geometry is denser, layouts are more intricate, and semantics are far more fine-grained. To address these challenges, we adopt a geometry-only supervision paradigm that uses only binary occupancy labels (occupied vs free). Our framework builds upon 3D Language-Embedded Gaussians, which serve as a unified intermediate representation coupling fine-grained 3D geometry with a language-aligned semantic embedding. On the geometry side, we find that existing Gaussian-to-Occupancy operators fail to converge under such weak supervision, and we introduce an opacity-aware, Poisson-based approach that stabilizes volumetric aggregation. On the semantic side, direct alignment between rendered features and open-vocabulary segmentation features suffers from feature mixing; we therefore propose a Progressive Temperature Decay schedule that gradually sharpens opacities during splatting, strengthening Gaussian-language alignment. On Occ-ScanNet, our framework achieves 59.50 IoU and 21.05 mIoU in the open-vocabulary setting, surpassing all existing occupancy methods in IoU and outperforming prior open-vocabulary approaches by a large margin in mIoU. Code will be released at https://github.com/JuIvyy/LegoOcc.
Generalizing Visual Geometry Priors to Sparse Gaussian Occupancy Prediction
Feb 25, 2026Accurate 3D scene understanding is essential for embodied intelligence, with occupancy prediction emerging as a key task for reasoning about both objects and free space. Existing approaches largely rely on depth priors (e.g., DepthAnything) but make only limited use of 3D cues, restricting performance and generalization. Recently, visual geometry models such as VGGT have shown strong capability in providing rich 3D priors, but similar to monocular depth foundation models, they still operate at the level of visible surfaces rather than volumetric interiors, motivating us to explore how to more effectively leverage these increasingly powerful geometry priors for 3D occupancy prediction. We present GPOcc, a framework that leverages generalizable visual geometry priors (GPs) for monocular occupancy prediction. Our method extends surface points inward along camera rays to generate volumetric samples, which are represented as Gaussian primitives for probabilistic occupancy inference. To handle streaming input, we further design a training-free incremental update strategy that fuses per-frame Gaussians into a unified global representation. Experiments on Occ-ScanNet and EmbodiedOcc-ScanNet demonstrate significant gains: GPOcc improves mIoU by +9.99 in the monocular setting and +11.79 in the streaming setting over prior state of the art. Under the same depth prior, it achieves +6.73 mIoU while running 2.65$\times$ faster. These results highlight that GPOcc leverages geometry priors more effectively and efficiently. Code will be released at https://github.com/JuIvyy/GPOcc.
RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
Jun 16, 2025



Accurate road topology reasoning is critical for autonomous driving, enabling effective navigation and adherence to traffic regulations. Central to this task are lane perception and topology reasoning. However, existing methods typically focus on either lane detection or Lane-to-Lane (L2L) topology reasoning, often \textit{neglecting} Lane-to-Traffic-element (L2T) relationships or \textit{failing} to optimize these tasks jointly. Furthermore, most approaches either overlook relational modeling or apply it in a limited scope, despite the inherent spatial relationships among road elements. We argue that relational modeling is beneficial for both perception and reasoning, as humans naturally leverage contextual relationships for road element recognition and their connectivity inference. To this end, we introduce relational modeling into both perception and reasoning, \textit{jointly} enhancing structural understanding. Specifically, we propose: 1) a relation-aware lane detector, where our geometry-biased self-attention and \curve\ cross-attention refine lane representations by capturing relational dependencies; 2) relation-enhanced topology heads, including a geometry-enhanced L2L head and a cross-view L2T head, boosting reasoning with relational cues; and 3) a contrastive learning strategy with InfoNCE loss to regularize relationship embeddings. Extensive experiments on OpenLane-V2 demonstrate that our approach significantly improves both detection and topology reasoning metrics, achieving +3.1 in DET$_l$, +5.3 in TOP$_{ll}$, +4.9 in TOP$_{lt}$, and an overall +4.4 in OLS, setting a new state-of-the-art. Code will be released.
Topo2Seq: Enhanced Topology Reasoning via Topology Sequence Learning
Feb 13, 2025



Extracting lane topology from perspective views (PV) is crucial for planning and control in autonomous driving. This approach extracts potential drivable trajectories for self-driving vehicles without relying on high-definition (HD) maps. However, the unordered nature and weak long-range perception of the DETR-like framework can result in misaligned segment endpoints and limited topological prediction capabilities. Inspired by the learning of contextual relationships in language models, the connectivity relations in roads can be characterized as explicit topology sequences. In this paper, we introduce Topo2Seq, a novel approach for enhancing topology reasoning via topology sequences learning. The core concept of Topo2Seq is a randomized order prompt-to-sequence learning between lane segment decoder and topology sequence decoder. The dual-decoder branches simultaneously learn the lane topology sequences extracted from the Directed Acyclic Graph (DAG) and the lane graph containing geometric information. Randomized order prompt-to-sequence learning extracts unordered key points from the lane graph predicted by the lane segment decoder, which are then fed into the prompt design of the topology sequence decoder to reconstruct an ordered and complete lane graph. In this way, the lane segment decoder learns powerful long-range perception and accurate topological reasoning from the topology sequence decoder. Notably, topology sequence decoder is only introduced during training and does not affect the inference efficiency. Experimental evaluations on the OpenLane-V2 dataset demonstrate the state-of-the-art performance of Topo2Seq in topology reasoning.
DV-3DLane: End-to-end Multi-modal 3D Lane Detection with Dual-view Representation
Jun 23, 2024Accurate 3D lane estimation is crucial for ensuring safety in autonomous driving. However, prevailing monocular techniques suffer from depth loss and lighting variations, hampering accurate 3D lane detection. In contrast, LiDAR points offer geometric cues and enable precise localization. In this paper, we present DV-3DLane, a novel end-to-end Dual-View multi-modal 3D Lane detection framework that synergizes the strengths of both images and LiDAR points. We propose to learn multi-modal features in dual-view spaces, i.e., perspective view (PV) and bird's-eye-view (BEV), effectively leveraging the modal-specific information. To achieve this, we introduce three designs: 1) A bidirectional feature fusion strategy that integrates multi-modal features into each view space, exploiting their unique strengths. 2) A unified query generation approach that leverages lane-aware knowledge from both PV and BEV spaces to generate queries. 3) A 3D dual-view deformable attention mechanism, which aggregates discriminative features from both PV and BEV spaces into queries for accurate 3D lane detection. Extensive experiments on the public benchmark, OpenLane, demonstrate the efficacy and efficiency of DV-3DLane. It achieves state-of-the-art performance, with a remarkable 11.2 gain in F1 score and a substantial 53.5% reduction in errors. The code is available at \url{https://github.com/JMoonr/dv-3dlane}.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 20, 2023



3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo, realistic OpenLane and ONCE-3DLanes by large margins (e.g., 11.4 gain in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR .
M^2-3DLaneNet: Multi-Modal 3D Lane Detection
Sep 20, 2022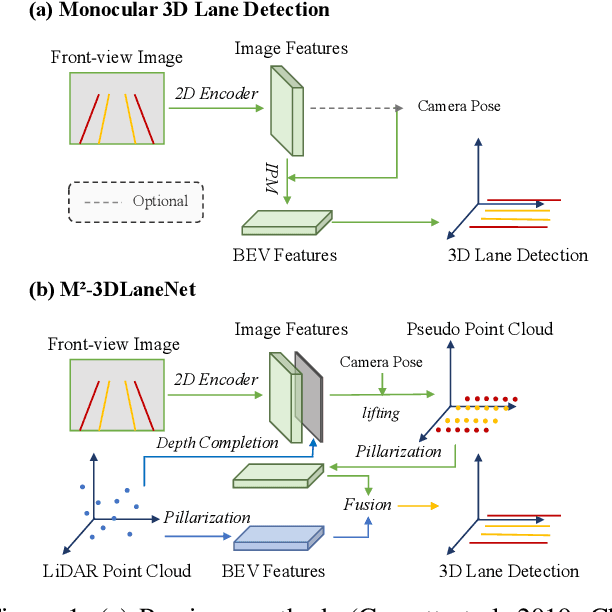
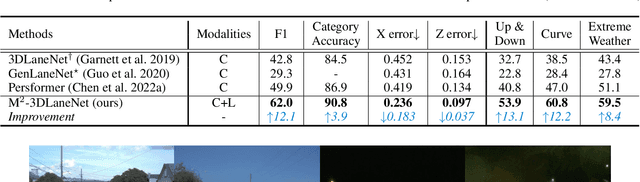
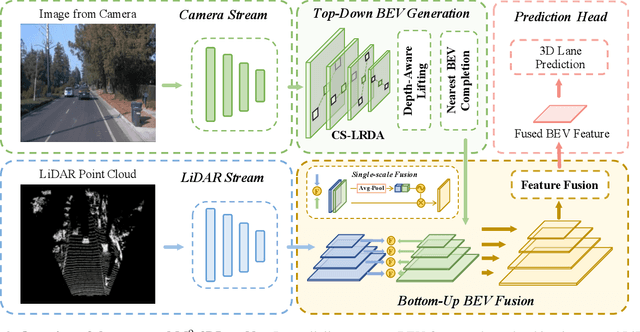
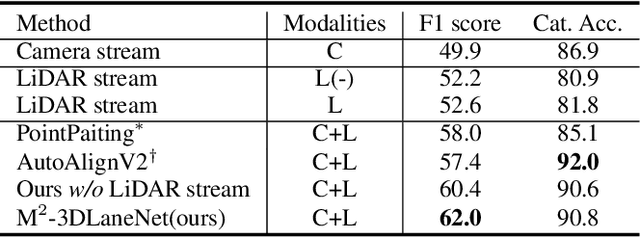
Estimating accurate lane lines in 3D space remains challenging due to their sparse and slim nature. In this work, we propose the M^2-3DLaneNet, a Multi-Modal framework for effective 3D lane detection. Aiming at integrating complementary information from multi-sensors, M^2-3DLaneNet first extracts multi-modal features with modal-specific backbones, then fuses them in a unified Bird's-Eye View (BEV) space. Specifically, our method consists of two core components. 1) To achieve accurate 2D-3D mapping, we propose the top-down BEV generation. Within it, a Line-Restricted Deform-Attention (LRDA) module is utilized to effectively enhance image features in a top-down manner, fully capturing the slenderness features of lanes. After that, it casts the 2D pyramidal features into 3D space using depth-aware lifting and generates BEV features through pillarization. 2) We further propose the bottom-up BEV fusion, which aggregates multi-modal features through multi-scale cascaded attention, integrating complementary information from camera and LiDAR sensors. Sufficient experiments demonstrate the effectiveness of M^2-3DLaneNet, which outperforms previous state-of-the-art methods by a large margin, i.e., 12.1% F1-score improvement on OpenLane dataset.
Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer
Aug 10, 2022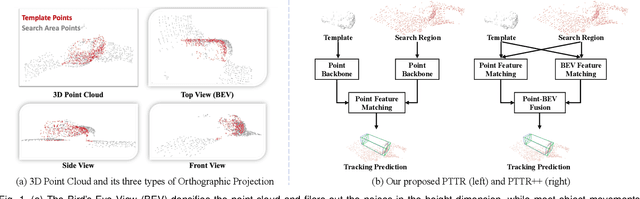
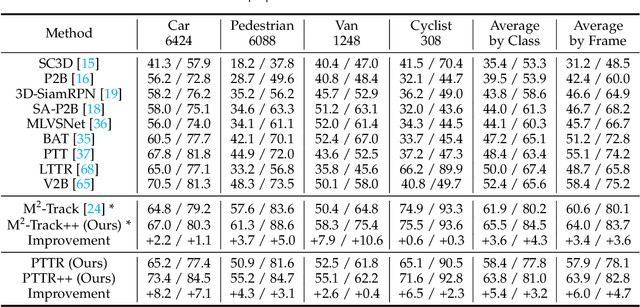
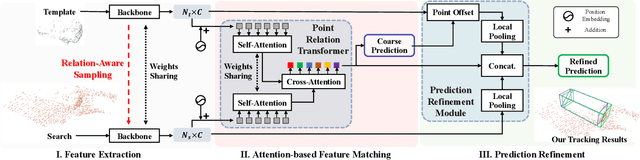
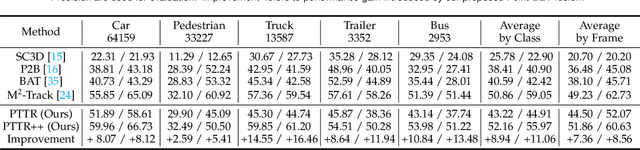
With the prevalence of LiDAR sensors in autonomous driving, 3D object tracking has received increasing attention. In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in consecutive frames given an object template. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to the given template during subsampling. 2) We propose a Point Relation Transformer for effective feature aggregation and feature matching between the template and search region. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction through local feature pooling. In addition, motivated by the favorable properties of the Bird's-Eye View (BEV) of point clouds in capturing object motion, we further design a more advanced framework named PTTR++, which incorporates both the point-wise view and BEV representation to exploit their complementary effect in generating high-quality tracking results. PTTR++ substantially boosts the tracking performance on top of PTTR with low computational overhead. Extensive experiments over multiple datasets show that our proposed approaches achieve superior 3D tracking accuracy and efficiency.
PTTR: Relational 3D Point Cloud Object Tracking with Transformer
Dec 07, 2021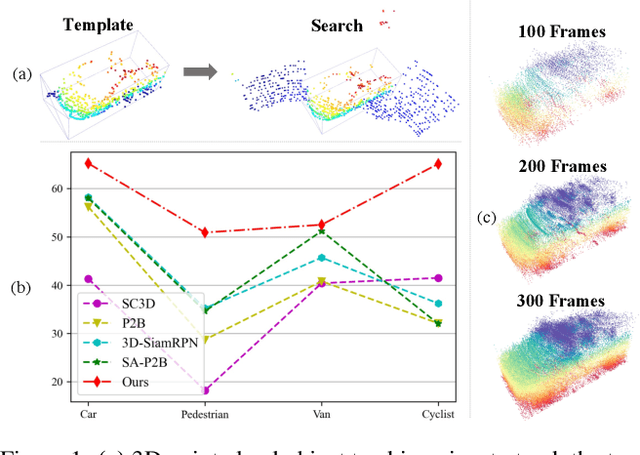
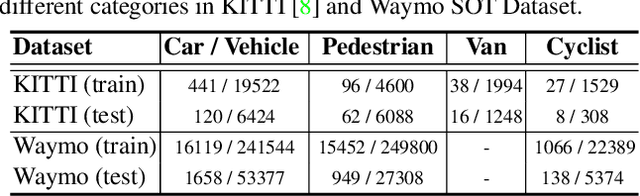
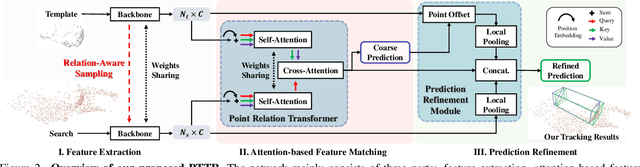
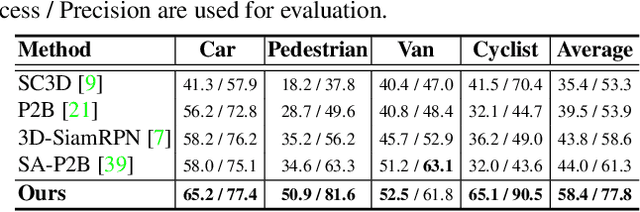
In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in the current search point cloud given a template point cloud. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to given templates during subsampling. 2) Furthermore, we propose a Point Relation Transformer (PRT) consisting of a self-attention and a cross-attention module. The global self-attention operation captures long-range dependencies to enhance encoded point features for the search area and the template, respectively. Subsequently, we generate the coarse tracking results by matching the two sets of point features via cross-attention. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction. In addition, we create a large-scale point cloud single object tracking benchmark based on the Waymo Open Dataset. Extensive experiments show that PTTR achieves superior point cloud tracking in both accuracy and efficiency.