 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
Unified Vision-Language-Action Model
Jun 24, 2025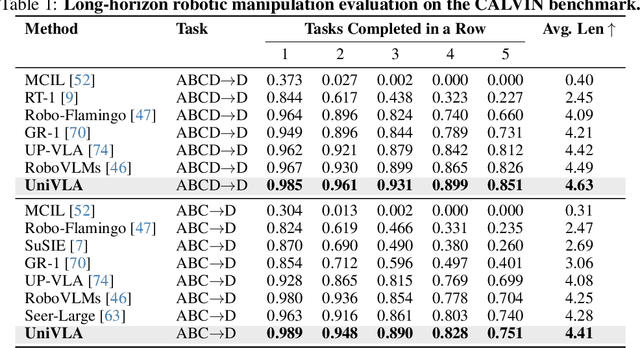
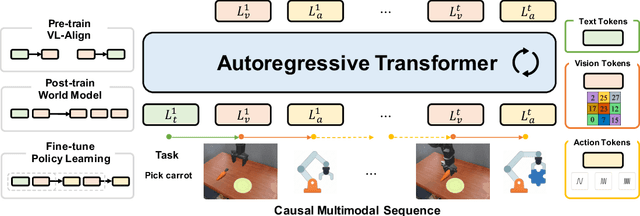
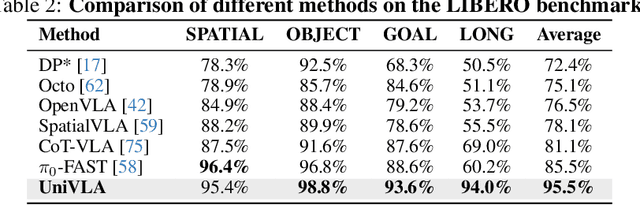
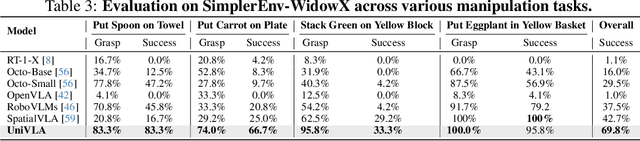
Vision-language-action models (VLAs) have garnered significant attention for their potential in advancing robotic manipulation. However, previous approaches predominantly rely on the general comprehension capabilities of vision-language models (VLMs) to generate action signals, often overlooking the rich temporal and causal structure embedded in visual observations. In this paper, we present UniVLA, a unified and native multimodal VLA model that autoregressively models vision, language, and action signals as discrete token sequences. This formulation enables flexible multimodal tasks learning, particularly from large-scale video data. By incorporating world modeling during post-training, UniVLA captures causal dynamics from videos, facilitating effective transfer to downstream policy learning--especially for long-horizon tasks. Our approach sets new state-of-the-art results across several widely used simulation benchmarks, including CALVIN, LIBERO, and Simplenv-Bridge, significantly surpassing previous methods. For example, UniVLA achieves 95.5% average success rate on LIBERO benchmark, surpassing pi0-FAST's 85.5%. We further demonstrate its broad applicability on real-world ALOHA manipulation and autonomous driving.
TC-Light: Temporally Consistent Relighting for Dynamic Long Videos
Jun 23, 2025Editing illumination in long videos with complex dynamics has significant value in various downstream tasks, including visual content creation and manipulation, as well as data scaling up for embodied AI through sim2real and real2real transfer. Nevertheless, existing video relighting techniques are predominantly limited to portrait videos or fall into the bottleneck of temporal consistency and computation efficiency. In this paper, we propose TC-Light, a novel paradigm characterized by the proposed two-stage post optimization mechanism. Starting from the video preliminarily relighted by an inflated video relighting model, it optimizes appearance embedding in the first stage to align global illumination. Then it optimizes the proposed canonical video representation, i.e., Unique Video Tensor (UVT), to align fine-grained texture and lighting in the second stage. To comprehensively evaluate performance, we also establish a long and highly dynamic video benchmark. Extensive experiments show that our method enables physically plausible relighting results with superior temporal coherence and low computation cost. The code and video demos are available at https://dekuliutesla.github.io/tclight/.
MLLM-CL: Continual Learning for Multimodal Large Language Models
Jun 05, 2025



Recent Multimodal Large Language Models (MLLMs) excel in vision-language understanding but face challenges in adapting to dynamic real-world scenarios that require continuous integration of new knowledge and skills. While continual learning (CL) offers a potential solution, existing benchmarks and methods suffer from critical limitations. In this paper, we introduce MLLM-CL, a novel benchmark encompassing domain and ability continual learning, where the former focuses on independently and identically distributed (IID) evaluation across evolving mainstream domains, whereas the latter evaluates on non-IID scenarios with emerging model ability. Methodologically, we propose preventing catastrophic interference through parameter isolation, along with an MLLM-based routing mechanism. Extensive experiments demonstrate that our approach can integrate domain-specific knowledge and functional abilities with minimal forgetting, significantly outperforming existing methods.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
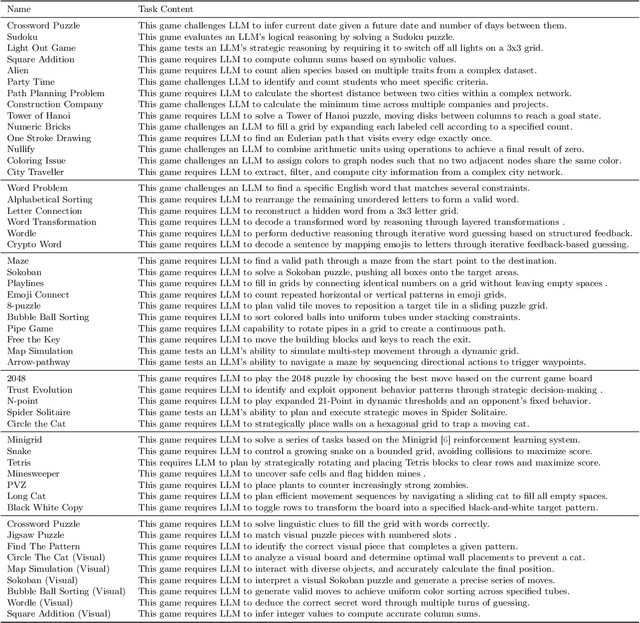
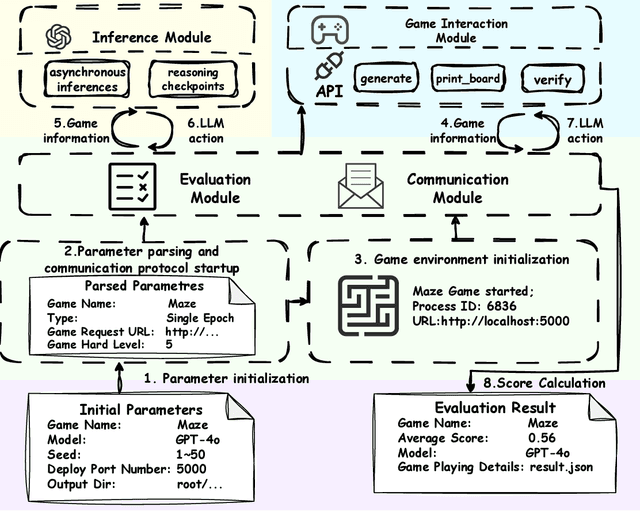

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
Semi-parametric Memory Consolidation: Towards Brain-like Deep Continual Learning
Apr 20, 2025Humans and most animals inherently possess a distinctive capacity to continually acquire novel experiences and accumulate worldly knowledge over time. This ability, termed continual learning, is also critical for deep neural networks (DNNs) to adapt to the dynamically evolving world in open environments. However, DNNs notoriously suffer from catastrophic forgetting of previously learned knowledge when trained on sequential tasks. In this work, inspired by the interactive human memory and learning system, we propose a novel biomimetic continual learning framework that integrates semi-parametric memory and the wake-sleep consolidation mechanism. For the first time, our method enables deep neural networks to retain high performance on novel tasks while maintaining prior knowledge in real-world challenging continual learning scenarios, e.g., class-incremental learning on ImageNet. This study demonstrates that emulating biological intelligence provides a promising path to enable deep neural networks with continual learning capabilities.
TrustLoRA: Low-Rank Adaptation for Failure Detection under Out-of-distribution Data
Apr 20, 2025



Reliable prediction is an essential requirement for deep neural models that are deployed in open environments, where both covariate and semantic out-of-distribution (OOD) data arise naturally. In practice, to make safe decisions, a reliable model should accept correctly recognized inputs while rejecting both those misclassified covariate-shifted and semantic-shifted examples. Besides, considering the potential existing trade-off between rejecting different failure cases, more convenient, controllable, and flexible failure detection approaches are needed. To meet the above requirements, we propose a simple failure detection framework to unify and facilitate classification with rejection under both covariate and semantic shifts. Our key insight is that by separating and consolidating failure-specific reliability knowledge with low-rank adapters and then integrating them, we can enhance the failure detection ability effectively and flexibly. Extensive experiments demonstrate the superiority of our framework.
Ross3D: Reconstructive Visual Instruction Tuning with 3D-Awareness
Apr 02, 2025



The rapid development of Large Multimodal Models (LMMs) for 2D images and videos has spurred efforts to adapt these models for interpreting 3D scenes. However, the absence of large-scale 3D vision-language datasets has posed a significant obstacle. To address this issue, typical approaches focus on injecting 3D awareness into 2D LMMs by designing 3D input-level scene representations. This work provides a new perspective. We introduce reconstructive visual instruction tuning with 3D-awareness (Ross3D), which integrates 3D-aware visual supervision into the training procedure. Specifically, it incorporates cross-view and global-view reconstruction. The former requires reconstructing masked views by aggregating overlapping information from other views. The latter aims to aggregate information from all available views to recover Bird's-Eye-View images, contributing to a comprehensive overview of the entire scene. Empirically, Ross3D achieves state-of-the-art performance across various 3D scene understanding benchmarks. More importantly, our semi-supervised experiments demonstrate significant potential in leveraging large amounts of unlabeled 3D vision-only data.
End-to-End Driving with Online Trajectory Evaluation via BEV World Model
Apr 02, 2025End-to-end autonomous driving has achieved remarkable progress by integrating perception, prediction, and planning into a fully differentiable framework. Yet, to fully realize its potential, an effective online trajectory evaluation is indispensable to ensure safety. By forecasting the future outcomes of a given trajectory, trajectory evaluation becomes much more effective. This goal can be achieved by employing a world model to capture environmental dynamics and predict future states. Therefore, we propose an end-to-end driving framework WoTE, which leverages a BEV World model to predict future BEV states for Trajectory Evaluation. The proposed BEV world model is latency-efficient compared to image-level world models and can be seamlessly supervised using off-the-shelf BEV-space traffic simulators. We validate our framework on both the NAVSIM benchmark and the closed-loop Bench2Drive benchmark based on the CARLA simulator, achieving state-of-the-art performance. Code is released at https://github.com/liyingyanUCAS/WoTE.
EmoDiffusion: Enhancing Emotional 3D Facial Animation with Latent Diffusion Models
Mar 14, 2025Speech-driven 3D facial animation seeks to produce lifelike facial expressions that are synchronized with the speech content and its emotional nuances, finding applications in various multimedia fields. However, previous methods often overlook emotional facial expressions or fail to disentangle them effectively from the speech content. To address these challenges, we present EmoDiffusion, a novel approach that disentangles different emotions in speech to generate rich 3D emotional facial expressions. Specifically, our method employs two Variational Autoencoders (VAEs) to separately generate the upper face region and mouth region, thereby learning a more refined representation of the facial sequence. Unlike traditional methods that use diffusion models to connect facial expression sequences with audio inputs, we perform the diffusion process in the latent space. Furthermore, we introduce an Emotion Adapter to evaluate upper face movements accurately. Given the paucity of 3D emotional talking face data in the animation industry, we capture facial expressions under the guidance of animation experts using LiveLinkFace on an iPhone. This effort results in the creation of an innovative 3D blendshape emotional talking face dataset (3D-BEF) used to train our network. Extensive experiments and perceptual evaluations validate the effectiveness of our approach, confirming its superiority in generating realistic and emotionally rich facial animations.