 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuxuan Wang
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Aug 24, 2022
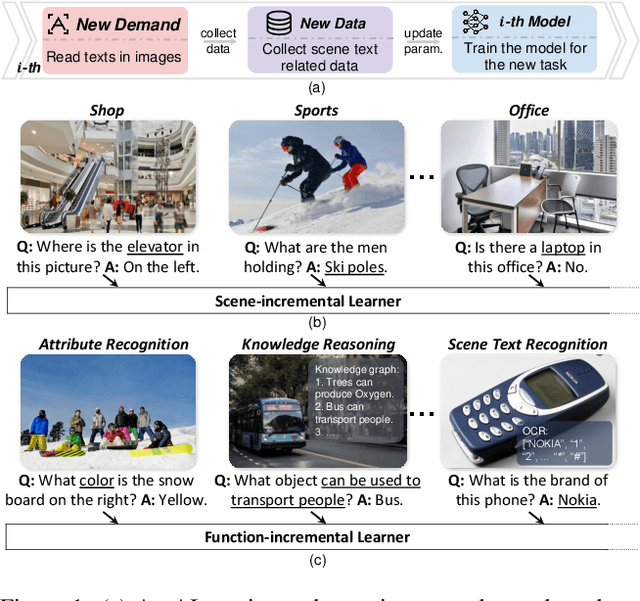
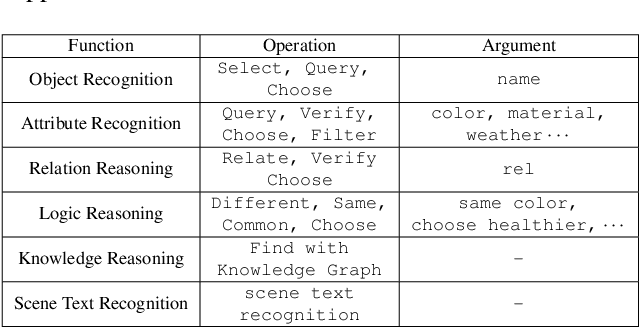
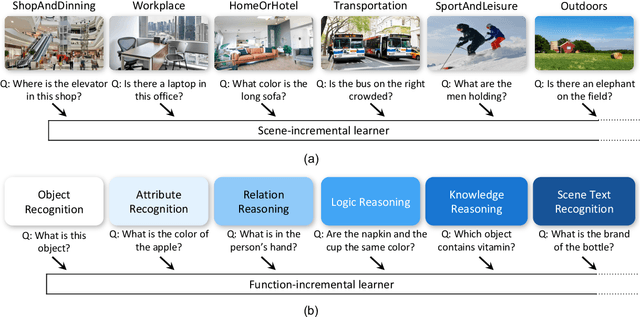
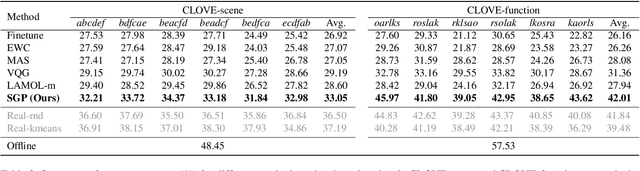
VQA is an ambitious task aiming to answer any image-related question. However, in reality, it is hard to build such a system once for all since the needs of users are continuously updated, and the system has to implement new functions. Thus, Continual Learning (CL) ability is a must in developing advanced VQA systems. Recently, a pioneer work split a VQA dataset into disjoint answer sets to study this topic. However, CL on VQA involves not only the expansion of label sets (new Answer sets). It is crucial to study how to answer questions when deploying VQA systems to new environments (new Visual scenes) and how to answer questions requiring new functions (new Question types). Thus, we propose CLOVE, a benchmark for Continual Learning On Visual quEstion answering, which contains scene- and function-incremental settings for the two aforementioned CL scenarios. In terms of methodology, the main difference between CL on VQA and classification is that the former additionally involves expanding and preventing forgetting of reasoning mechanisms, while the latter focusing on class representation. Thus, we propose a real-data-free replay-based method tailored for CL on VQA, named Scene Graph as Prompt for Symbolic Replay. Using a piece of scene graph as a prompt, it replays pseudo scene graphs to represent the past images, along with correlated QA pairs. A unified VQA model is also proposed to utilize the current and replayed data to enhance its QA ability. Finally, experimental results reveal challenges in CLOVE and demonstrate the effectiveness of our method. The dataset and code will be available at https://github.com/showlab/CLVQA.
A Piecewise Monotonic Gait Phase Estimation Model for Controlling a Powered Transfemoral Prosthesis in Various Locomotion Modes
Jul 25, 2022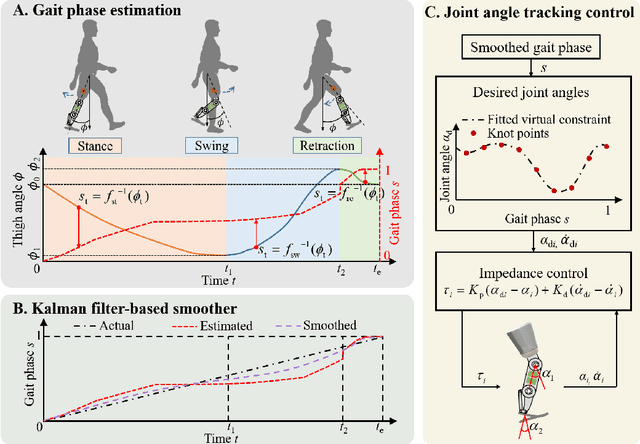

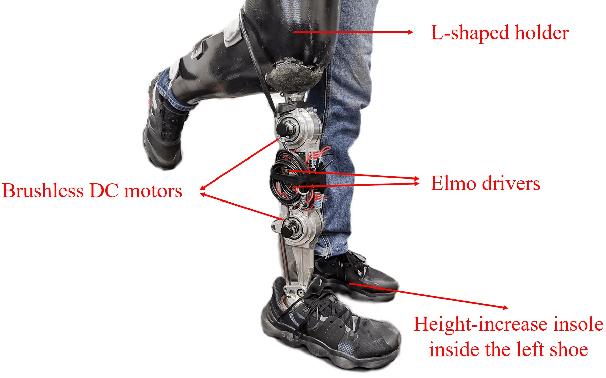
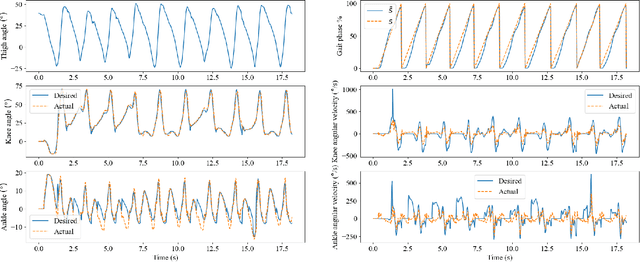
Gait phase-based control is a trending research topic for walking-aid robots, especially robotic lower-limb prostheses. Gait phase estimation is a challenge for gait phase-based control. Previous researches used the integration or the differential of the human's thigh angle to estimate the gait phase, but accumulative measurement errors and noises can affect the estimation results. In this paper, a more robust gait phase estimation method is proposed using a unified form of piecewise monotonic gait phase-thigh angle models for various locomotion modes. The gait phase is estimated from only the thigh angle, which is a stable variable and avoids phase drifting. A Kalman filter-based smoother is designed to further suppress the mutations of the estimated gait phase. Based on the proposed gait phase estimation method, a gait phase-based joint angle tracking controller is designed for a transfemoral prosthesis. The proposed gait estimation method, the gait phase smoother, and the controller are evaluated through offline analysis on walking data in various locomotion modes. And the real-time performance of the gait phase-based controller is validated in an experiment on the transfemoral prosthesis.
Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Jul 13, 2022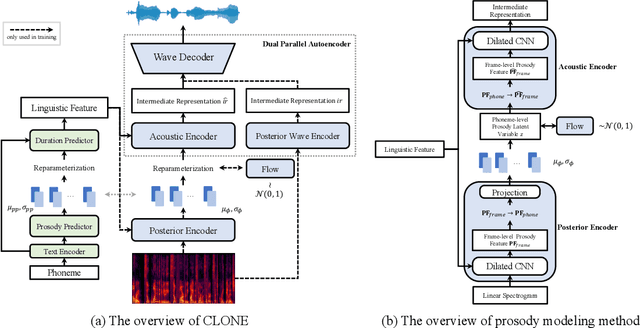
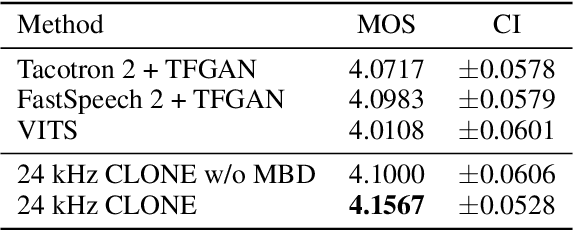
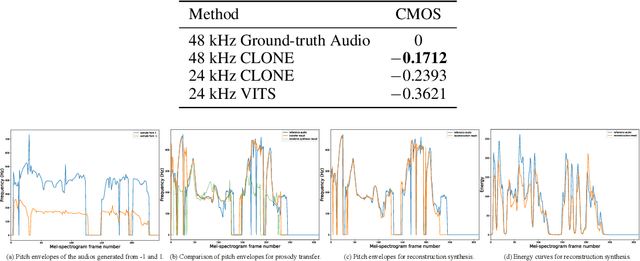

Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Jun 16, 2022
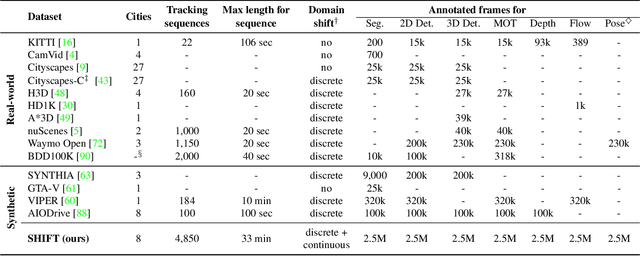
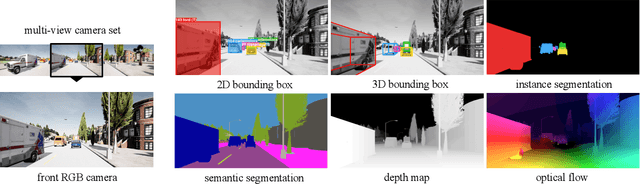

Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems. Existing image and video driving datasets, however, fall short of capturing the mutable nature of the real world. In this paper, we introduce the largest multi-task synthetic dataset for autonomous driving, SHIFT. It presents discrete and continuous shifts in cloudiness, rain and fog intensity, time of day, and vehicle and pedestrian density. Featuring a comprehensive sensor suite and annotations for several mainstream perception tasks, SHIFT allows investigating the degradation of a perception system performance at increasing levels of domain shift, fostering the development of continuous adaptation strategies to mitigate this problem and assess model robustness and generality. Our dataset and benchmark toolkit are publicly available at www.vis.xyz/shift.
VoiceFixer: A Unified Framework for High-Fidelity Speech Restoration
Apr 17, 2022
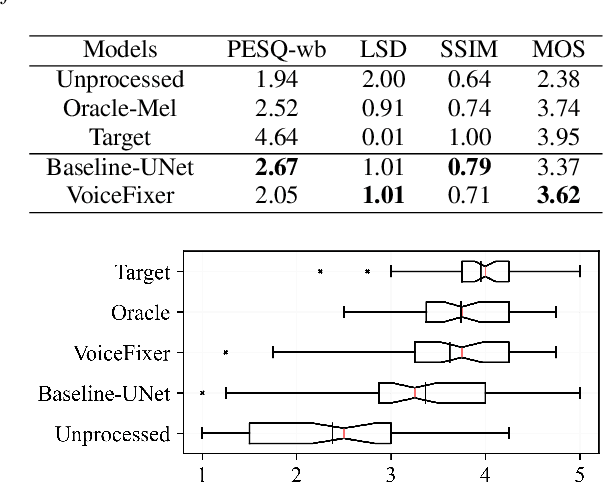
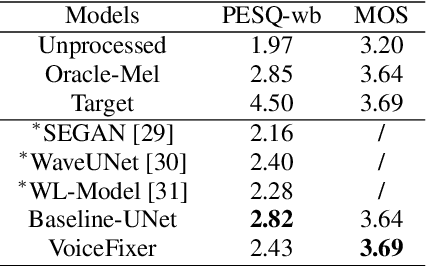
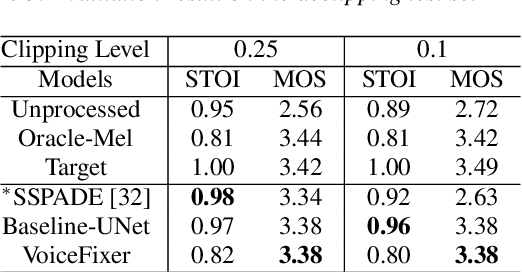
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on a single type of distortion, such as speech denoising or dereverberation. However, speech signals can be degraded by several different distortions simultaneously in the real world. It is thus important to extend speech restoration models to deal with multiple distortions. In this paper, we introduce VoiceFixer, a unified framework for high-fidelity speech restoration. VoiceFixer restores speech from multiple distortions (e.g., noise, reverberation, and clipping) and can expand degraded speech (e.g., noisy speech) with a low bandwidth to 44.1 kHz full-bandwidth high-fidelity speech. We design VoiceFixer based on (1) an analysis stage that predicts intermediate-level features from the degraded speech, and (2) a synthesis stage that generates waveform using a neural vocoder. Both objective and subjective evaluations show that VoiceFixer is effective on severely degraded speech, such as real-world historical speech recordings. Samples of VoiceFixer are available at https://haoheliu.github.io/voicefixer.
GEB+: A benchmark for generic event boundary captioning, grounding and text-based retrieval
Apr 10, 2022



Cognitive science has shown that humans perceive videos in terms of events separated by state changes of dominant subjects. State changes trigger new events and are one of the most useful among the large amount of redundant information perceived. However, previous research focuses on the overall understanding of segments without evaluating the fine-grained status changes inside. In this paper, we introduce a new dataset called Kinetic-GEBC (Generic Event Boundary Captioning). The dataset consists of over 170k boundaries associated with captions describing status changes in the generic events in 12K videos. Upon this new dataset, we propose three tasks supporting the development of a more fine-grained, robust, and human-like understanding of videos through status changes. We evaluate many representative baselines in our dataset, where we also design a new TPD (Temporal-based Pairwise Difference) Modeling method for current state-of-the-art backbones and achieve significant performance improvements. Besides, the results show there are still formidable challenges for current methods in the utilization of different granularities, representation of visual difference, and the accurate localization of status changes. Further analysis shows that our dataset can drive developing more powerful methods to understand status changes and thus improve video level comprehension.
NeuFA: Neural Network Based End-to-End Forced Alignment with Bidirectional Attention Mechanism
Mar 31, 2022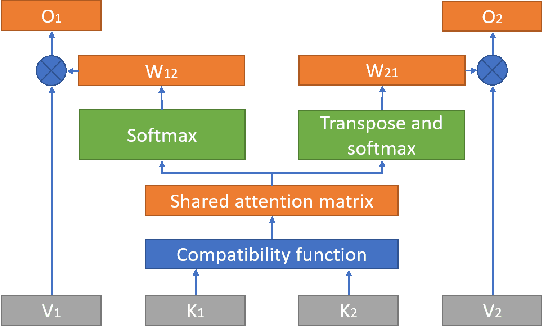
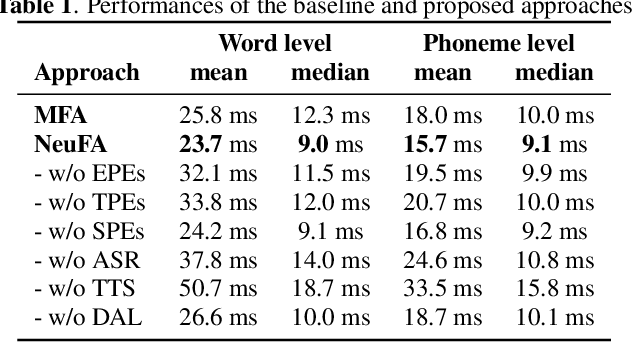
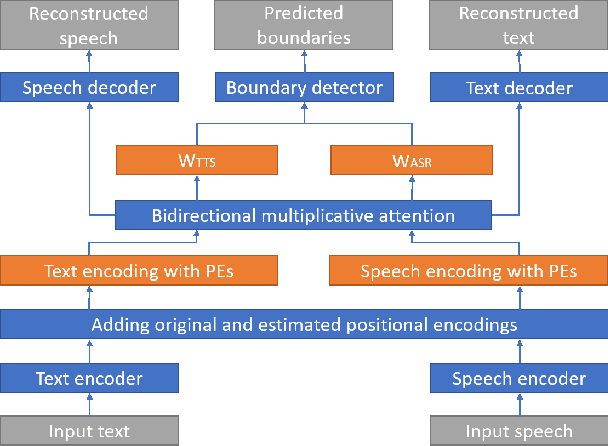
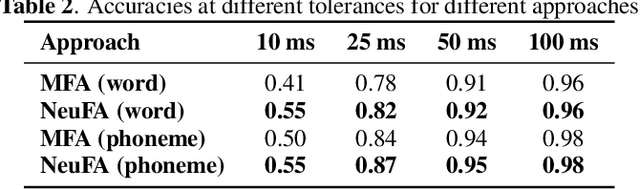
Although deep learning and end-to-end models have been widely used and shown superiority in automatic speech recognition (ASR) and text-to-speech (TTS) synthesis, state-of-the-art forced alignment (FA) models are still based on hidden Markov model (HMM). HMM has limited view of contextual information and is developed with long pipelines, leading to error accumulation and unsatisfactory performance. Inspired by the capability of attention mechanism in capturing long term contextual information and learning alignments in ASR and TTS, we propose a neural network based end-to-end forced aligner called NeuFA, in which a novel bidirectional attention mechanism plays an essential role. NeuFA integrates the alignment learning of both ASR and TTS tasks in a unified framework by learning bidirectional alignment information from a shared attention matrix in the proposed bidirectional attention mechanism. Alignments are extracted from the learnt attention weights and optimized by the ASR, TTS and FA tasks in a multi-task learning manner. Experimental results demonstrate the effectiveness of our proposed model, with mean absolute error on test set drops from 25.8 ms to 23.7 ms at word level, and from 17.0 ms to 15.7 ms at phoneme level compared with state-of-the-art HMM based model.
The USTC-Ximalaya system for the ICASSP 2022 multi-channel multi-party meeting transcription (M2MeT) challenge
Feb 10, 2022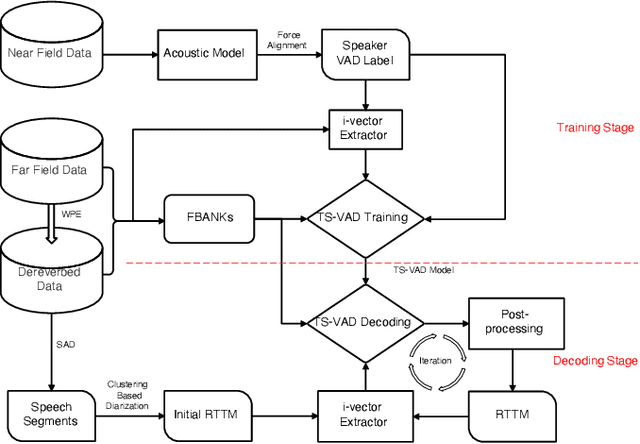
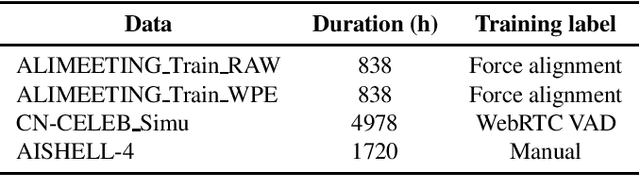
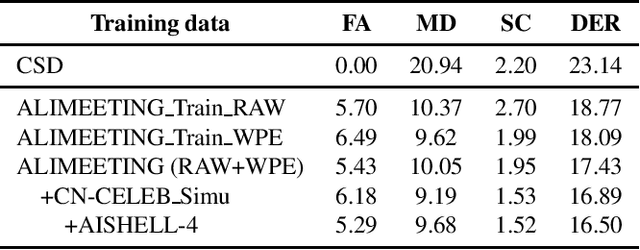
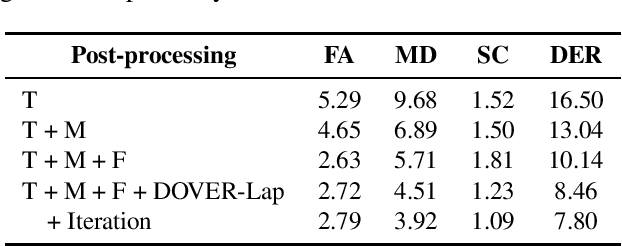
We propose two improvements to target-speaker voice activity detection (TS-VAD), the core component in our proposed speaker diarization system that was submitted to the 2022 Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenge. These techniques are designed to handle multi-speaker conversations in real-world meeting scenarios with high speaker-overlap ratios and under heavy reverberant and noisy condition. First, for data preparation and augmentation in training TS-VAD models, speech data containing both real meetings and simulated indoor conversations are used. Second, in refining results obtained after TS-VAD based decoding, we perform a series of post-processing steps to improve the VAD results needed to reduce diarization error rates (DERs). Tested on the ALIMEETING corpus, the newly released Mandarin meeting dataset used in M2MeT, we demonstrate that our proposed system can decrease the DER by up to 66.55/60.59% relatively when compared with classical clustering based diarization on the Eval/Test set.
AssistSR: Affordance-centric Question-driven Video Segment Retrieval
Dec 06, 2021
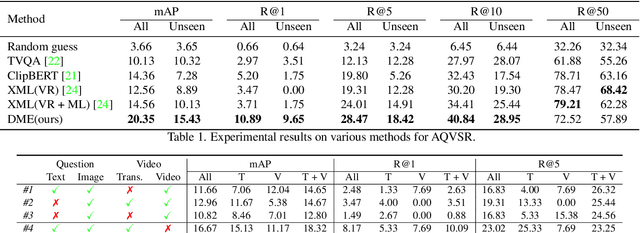
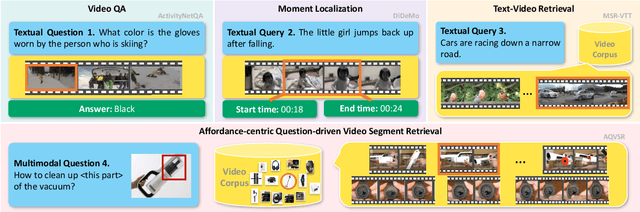
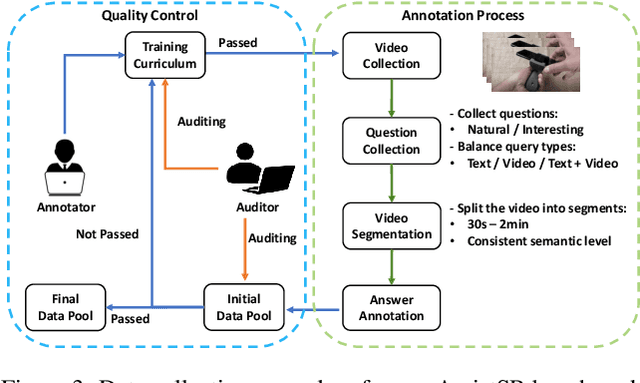
It is still a pipe dream that AI assistants on phone and AR glasses can assist our daily life in addressing our questions like "how to adjust the date for this watch?" and "how to set its heating duration? (while pointing at an oven)". The queries used in conventional tasks (i.e. Video Question Answering, Video Retrieval, Moment Localization) are often factoid and based on pure text. In contrast, we present a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR). Each of our questions is an image-box-text query that focuses on affordance of items in our daily life and expects relevant answer segments to be retrieved from a corpus of instructional video-transcript segments. To support the study of this AQVSR task, we construct a new dataset called AssistSR. We design novel guidelines to create high-quality samples. This dataset contains 1.4k multimodal questions on 1k video segments from instructional videos on diverse daily-used items. To address AQVSR, we develop a straightforward yet effective model called Dual Multimodal Encoders (DME) that significantly outperforms several baseline methods while still having large room for improvement in the future. Moreover, we present detailed ablation analyses. Our codes and data are available at https://github.com/StanLei52/AQVSR.