 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Impedance Control for Floating-Base Supernumerary Robotic Leg in Walking Assistance
Nov 15, 2025In human-robot systems, ensuring safety during force control in the presence of both internal and external disturbances is crucial. As a typical loosely coupled floating-base robot system, the supernumerary robotic leg (SRL) system is particularly susceptible to strong internal disturbances. To address the challenge posed by floating base, we investigated the dynamics model of the loosely coupled SRL and designed a hybrid position/force impedance controller to fit dynamic torque input. An efficient variable impedance control (VIC) method is developed to enhance human-robot interaction, particularly in scenarios involving external force disturbances. By dynamically adjusting impedance parameters, VIC improves the dynamic switching between rigidity and flexibility, so that it can adapt to unknown environmental disturbances in different states. An efficient real-time stability guaranteed impedance parameters generating network is specifically designed for the proposed SRL, to achieve shock mitigation and high rigidity supporting. Simulations and experiments validate the system's effectiveness, demonstrating its ability to maintain smooth signal transitions in flexible states while providing strong support forces in rigid states. This approach provides a practical solution for accommodating individual gait variations in interaction, and significantly advances the safety and adaptability of human-robot systems.
MindEye-OmniAssist: A Gaze-Driven LLM-Enhanced Assistive Robot System for Implicit Intention Recognition and Task Execution
Mar 17, 2025A promising effective human-robot interaction in assistive robotic systems is gaze-based control. However, current gaze-based assistive systems mainly help users with basic grasping actions, offering limited support. Moreover, the restricted intent recognition capability constrains the assistive system's ability to provide diverse assistance functions. In this paper, we propose an open implicit intention recognition framework powered by Large Language Model (LLM) and Vision Foundation Model (VFM), which can process gaze input and recognize user intents that are not confined to predefined or specific scenarios. Furthermore, we implement a gaze-driven LLM-enhanced assistive robot system (MindEye-OmniAssist) that recognizes user's intentions through gaze and assists in completing task. To achieve this, the system utilizes open vocabulary object detector, intention recognition network and LLM to infer their full intentions. By integrating eye movement feedback and LLM, it generates action sequences to assist the user in completing tasks. Real-world experiments have been conducted for assistive tasks, and the system achieved an overall success rate of 41/55 across various undefined tasks. Preliminary results show that the proposed method holds the potential to provide a more user-friendly human-computer interaction interface and significantly enhance the versatility and effectiveness of assistive systems by supporting more complex and diverse task.
Fast Hip Joint Moment Estimation with A General Moment Feature Generation Method
Oct 01, 2024The hip joint moment during walking is a crucial basis for hip exoskeleton control. Compared to generating assistive torque profiles based on gait estimation, estimating hip joint moment directly using hip joint angles offers advantages such as simplified sensing and adaptability to variable walking speeds. Existing methods that directly estimate moment from hip joint angles are mainly used for offline biomechanical estimation. However, they suffer from long computation time and lack of personalization, rendering them unsuitable for personalized control of hip exoskeletons. To address these challenges, this paper proposes a fast hip joint moment estimation method based on generalized moment features (GMF). The method first employs a GMF generator to learn a feature representation of joint moment, namely the proposed GMF, which is independent of individual differences. Subsequently, a GRU-based neural network with fast computational performance is trained to learn the mapping from the joint kinematics to the GMF. Finally, the predicted GMF is decoded into the joint moment with a GMF decoder. The joint estimation model is trained and tested on a dataset comprising 20 subjects under 28 walking speed conditions. Results show that the proposed method achieves a root mean square error of 0.1180 $\pm$ 0.0021 Nm/kg for subjects in test dataset, and the computation time per estimation using the employed GRU-based estimator is 1.3420 $\pm$ 0.0031 ms, significantly faster than mainstream neural network architectures, while maintaining comparable network accuracy. These promising results demonstrate that the proposed method enhances the accuracy and computational speed of joint moment estimation neural networks, with potential for guiding exoskeleton control.
Enhancing Prosthetic Safety and Environmental Adaptability: A Visual-Inertial Prosthesis Motion Estimation Approach on Uneven Terrains
Apr 29, 2024



Environment awareness is crucial for enhancing walking safety and stability of amputee wearing powered prosthesis when crossing uneven terrains such as stairs and obstacles. However, existing environmental perception systems for prosthesis only provide terrain types and corresponding parameters, which fails to prevent potential collisions when crossing uneven terrains and may lead to falls and other severe consequences. In this paper, a visual-inertial motion estimation approach is proposed for prosthesis to perceive its movement and the changes of spatial relationship between the prosthesis and uneven terrain when traversing them. To achieve this, we estimate the knee motion by utilizing a depth camera to perceive the environment and align feature points extracted from stairs and obstacles. Subsequently, an error-state Kalman filter is incorporated to fuse the inertial data into visual estimations to reduce the feature extraction error and obtain a more robust estimation. The motion of prosthetic joint and toe are derived using the prosthesis model parameters. Experiment conducted on our collected dataset and stair walking trials with a powered prosthesis shows that the proposed method can accurately tracking the motion of the human leg and prosthesis with an average root-mean-square error of toe trajectory less than 5 cm. The proposed method is expected to enable the environmental adaptive control for prosthesis, thereby enhancing amputee's safety and mobility in uneven terrains.
D3PRefiner: A Diffusion-based Denoise Method for 3D Human Pose Refinement
Jan 08, 2024Three-dimensional (3D) human pose estimation using a monocular camera has gained increasing attention due to its ease of implementation and the abundance of data available from daily life. However, owing to the inherent depth ambiguity in images, the accuracy of existing monocular camera-based 3D pose estimation methods remains unsatisfactory, and the estimated 3D poses usually include much noise. By observing the histogram of this noise, we find each dimension of the noise follows a certain distribution, which indicates the possibility for a neural network to learn the mapping between noisy poses and ground truth poses. In this work, in order to obtain more accurate 3D poses, a Diffusion-based 3D Pose Refiner (D3PRefiner) is proposed to refine the output of any existing 3D pose estimator. We first introduce a conditional multivariate Gaussian distribution to model the distribution of noisy 3D poses, using paired 2D poses and noisy 3D poses as conditions to achieve greater accuracy. Additionally, we leverage the architecture of current diffusion models to convert the distribution of noisy 3D poses into ground truth 3D poses. To evaluate the effectiveness of the proposed method, two state-of-the-art sequence-to-sequence 3D pose estimators are used as basic 3D pose estimation models, and the proposed method is evaluated on different types of 2D poses and different lengths of the input sequence. Experimental results demonstrate the proposed architecture can significantly improve the performance of current sequence-to-sequence 3D pose estimators, with a reduction of at least 10.3% in the mean per joint position error (MPJPE) and at least 11.0% in the Procrustes MPJPE (P-MPJPE).
A Piecewise Monotonic Gait Phase Estimation Model for Controlling a Powered Transfemoral Prosthesis in Various Locomotion Modes
Jul 25, 2022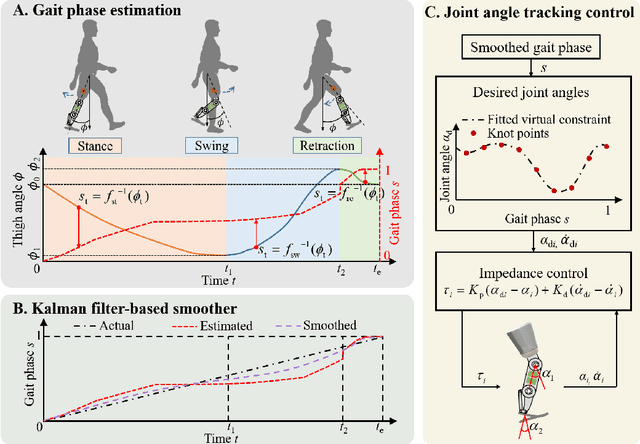

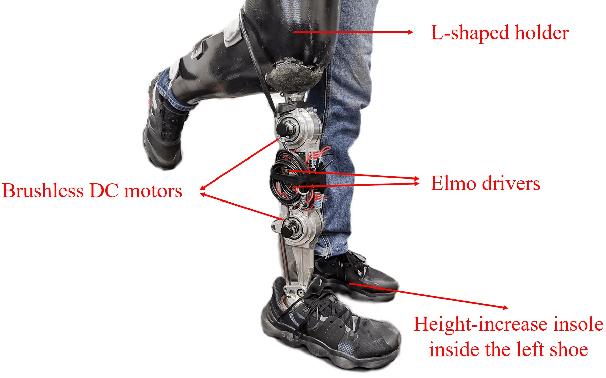
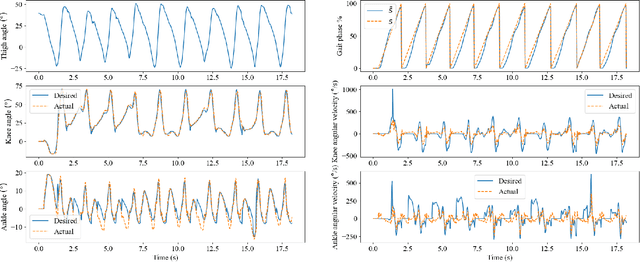
Gait phase-based control is a trending research topic for walking-aid robots, especially robotic lower-limb prostheses. Gait phase estimation is a challenge for gait phase-based control. Previous researches used the integration or the differential of the human's thigh angle to estimate the gait phase, but accumulative measurement errors and noises can affect the estimation results. In this paper, a more robust gait phase estimation method is proposed using a unified form of piecewise monotonic gait phase-thigh angle models for various locomotion modes. The gait phase is estimated from only the thigh angle, which is a stable variable and avoids phase drifting. A Kalman filter-based smoother is designed to further suppress the mutations of the estimated gait phase. Based on the proposed gait phase estimation method, a gait phase-based joint angle tracking controller is designed for a transfemoral prosthesis. The proposed gait estimation method, the gait phase smoother, and the controller are evaluated through offline analysis on walking data in various locomotion modes. And the real-time performance of the gait phase-based controller is validated in an experiment on the transfemoral prosthesis.
Ensemble diverse hypotheses and knowledge distillation for unsupervised cross-subject adaptation
Apr 15, 2022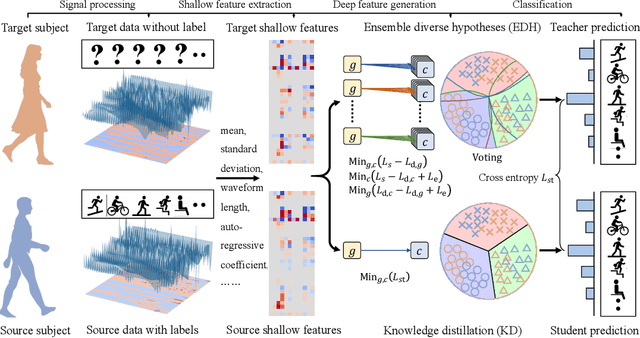
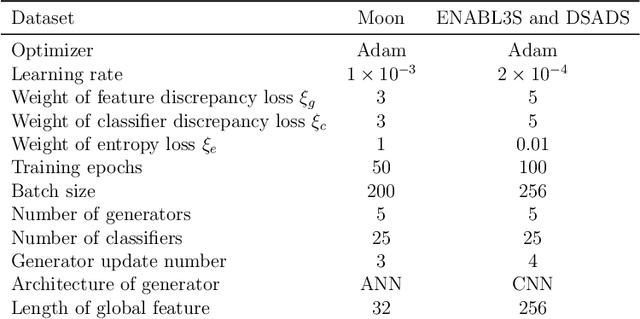
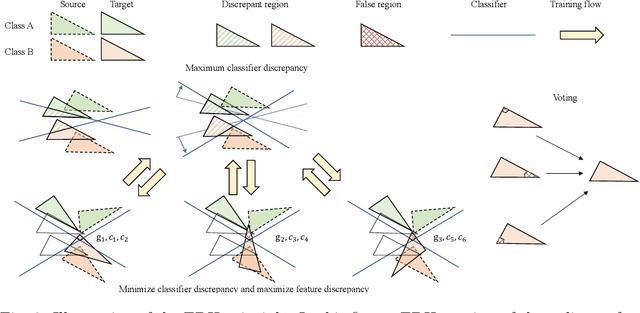
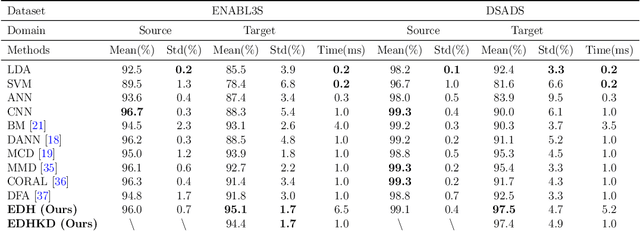
Recognizing human locomotion intent and activities is important for controlling the wearable robots while walking in complex environments. However, human-robot interface signals are usually user-dependent, which causes that the classifier trained on source subjects performs poorly on new subjects. To address this issue, this paper designs the ensemble diverse hypotheses and knowledge distillation (EDHKD) method to realize unsupervised cross-subject adaptation. EDH mitigates the divergence between labeled data of source subjects and unlabeled data of target subjects to accurately classify the locomotion modes of target subjects without labeling data. Compared to previous domain adaptation methods based on the single learner, which may only learn a subset of features from input signals, EDH can learn diverse features by incorporating multiple diverse feature generators and thus increases the accuracy and decreases the variance of classifying target data, but it sacrifices the efficiency. To solve this problem, EDHKD (student) distills the knowledge from the EDH (teacher) to a single network to remain efficient and accurate. The performance of the EDHKD is theoretically proved and experimentally validated on a 2D moon dataset and two public human locomotion datasets. Experimental results show that the EDHKD outperforms all other methods. The EDHKD can classify target data with 96.9%, 94.4%, and 97.4% average accuracy on the above three datasets with a short computing time (1 ms). Compared to a benchmark (BM) method, the EDHKD increases 1.3% and 7.1% average accuracy for classifying the locomotion modes of target subjects. The EDHKD also stabilizes the learning curves. Therefore, the EDHKD is significant for increasing the generalization ability and efficiency of the human intent prediction and human activity recognition system, which will improve human-robot interactions.
Natural grasp intention recognition based on gaze fixation in human-robot interaction
Dec 16, 2020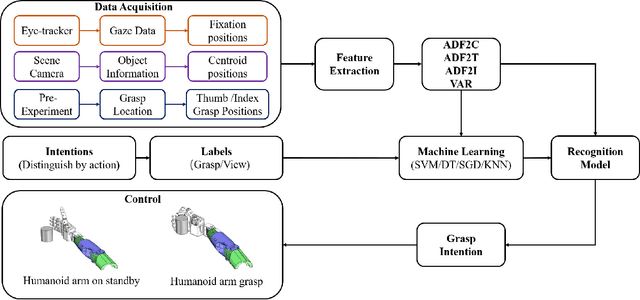
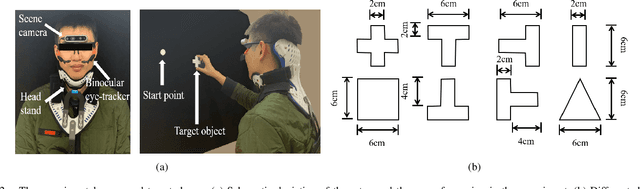
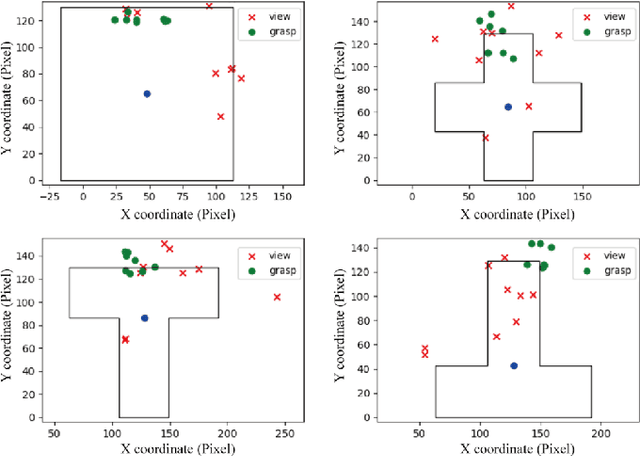
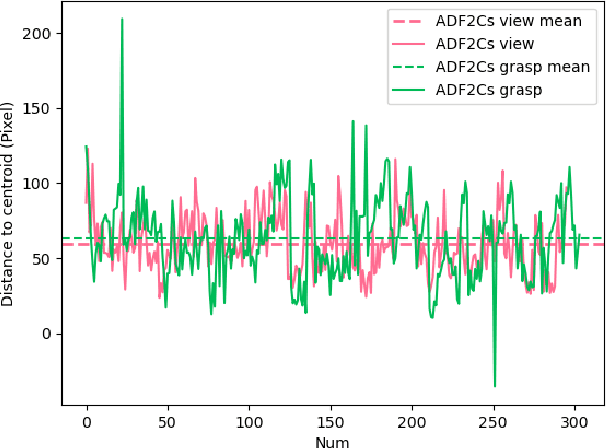
Eye movement is closely related to limb actions, so it can be used to infer movement intentions. More importantly, in some cases, eye movement is the only way for paralyzed and impaired patients with severe movement disorders to communicate and interact with the environment. Despite this, eye-tracking technology still has very limited application scenarios as an intention recognition method. The goal of this paper is to achieve a natural fixation-based grasping intention recognition method, with which a user with hand movement disorders can intuitively express what tasks he/she wants to do by directly looking at the object of interest. Toward this goal, we design experiments to study the relationships of fixations in different tasks. We propose some quantitative features from these relationships and analyze them statistically. Then we design a natural method for grasping intention recognition. The experimental results prove that the accuracy of the proposed method for the grasping intention recognition exceeds 89\% on the training objects. When this method is extendedly applied to objects not included in the training set, the average accuracy exceeds 85\%. The grasping experiment in the actual environment verifies the effectiveness of the proposed method.