 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Achieving Forgetting-free and Positive Knowledge Transfer
Jan 09, 2026Existing research on continual learning (CL) of a sequence of tasks focuses mainly on dealing with catastrophic forgetting (CF) to balance the learning plasticity of new tasks and the memory stability of old tasks. However, an ideal CL agent should not only be able to overcome CF, but also encourage positive forward and backward knowledge transfer (KT), i.e., using the learned knowledge from previous tasks for the new task learning (namely FKT), and improving the previous tasks' performance with the knowledge of the new task (namely BKT). To this end, this paper first models CL as an optimization problem in which each sequential learning task aims to achieve its optimal performance under the constraint that both FKT and BKT should be positive. It then proposes a novel Enhanced Task Continual Learning (ETCL) method, which achieves forgetting-free and positive KT. Furthermore, the bounds that can lead to negative FKT and BKT are estimated theoretically. Based on the bounds, a new strategy for online task similarity detection is also proposed to facilitate positive KT. To overcome CF, ETCL learns a set of task-specific binary masks to isolate a sparse sub-network for each task while preserving the performance of a dense network for the task. At the beginning of a new task learning, ETCL tries to align the new task's gradient with that of the sub-network of the previous most similar task to ensure positive FKT. By using a new bi-objective optimization strategy and an orthogonal gradient projection method, ETCL updates only the weights of previous similar tasks at the classification layer to achieve positive BKT. Extensive evaluations demonstrate that the proposed ETCL markedly outperforms strong baselines on dissimilar, similar, and mixed task sequences.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Not All Instances Are Equally Valuable: Towards Influence-Weighted Dataset Distillation
Oct 31, 2025Dataset distillation condenses large datasets into synthetic subsets, achieving performance comparable to training on the full dataset while substantially reducing storage and computation costs. Most existing dataset distillation methods assume that all real instances contribute equally to the process. In practice, real-world datasets contain both informative and redundant or even harmful instances, and directly distilling the full dataset without considering data quality can degrade model performance. In this work, we present Influence-Weighted Distillation IWD, a principled framework that leverages influence functions to explicitly account for data quality in the distillation process. IWD assigns adaptive weights to each instance based on its estimated impact on the distillation objective, prioritizing beneficial data while downweighting less useful or harmful ones. Owing to its modular design, IWD can be seamlessly integrated into diverse dataset distillation frameworks. Our empirical results suggest that integrating IWD tends to improve the quality of distilled datasets and enhance model performance, with accuracy gains of up to 7.8%.
RDD: Retrieval-Based Demonstration Decomposer for Planner Alignment in Long-Horizon Tasks
Oct 16, 2025



To tackle long-horizon tasks, recent hierarchical vision-language-action (VLAs) frameworks employ vision-language model (VLM)-based planners to decompose complex manipulation tasks into simpler sub-tasks that low-level visuomotor policies can easily handle. Typically, the VLM planner is finetuned to learn to decompose a target task. This finetuning requires target task demonstrations segmented into sub-tasks by either human annotation or heuristic rules. However, the heuristic subtasks can deviate significantly from the training data of the visuomotor policy, which degrades task performance. To address these issues, we propose a Retrieval-based Demonstration Decomposer (RDD) that automatically decomposes demonstrations into sub-tasks by aligning the visual features of the decomposed sub-task intervals with those from the training data of the low-level visuomotor policies. Our method outperforms the state-of-the-art sub-task decomposer on both simulation and real-world tasks, demonstrating robustness across diverse settings. Code and more results are available at rdd-neurips.github.io.
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025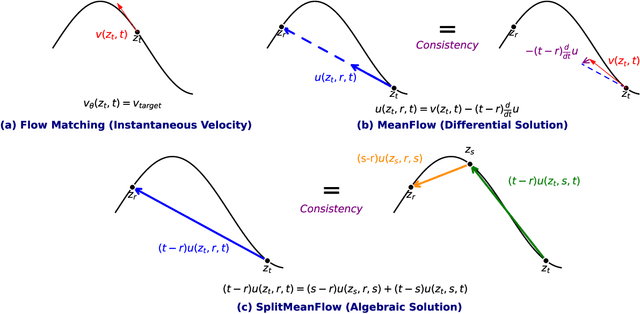


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.
AirV2X: Unified Air-Ground Vehicle-to-Everything Collaboration
Jun 24, 2025While multi-vehicular collaborative driving demonstrates clear advantages over single-vehicle autonomy, traditional infrastructure-based V2X systems remain constrained by substantial deployment costs and the creation of "uncovered danger zones" in rural and suburban areas. We present AirV2X-Perception, a large-scale dataset that leverages Unmanned Aerial Vehicles (UAVs) as a flexible alternative or complement to fixed Road-Side Units (RSUs). Drones offer unique advantages over ground-based perception: complementary bird's-eye-views that reduce occlusions, dynamic positioning capabilities that enable hovering, patrolling, and escorting navigation rules, and significantly lower deployment costs compared to fixed infrastructure. Our dataset comprises 6.73 hours of drone-assisted driving scenarios across urban, suburban, and rural environments with varied weather and lighting conditions. The AirV2X-Perception dataset facilitates the development and standardized evaluation of Vehicle-to-Drone (V2D) algorithms, addressing a critical gap in the rapidly expanding field of aerial-assisted autonomous driving systems. The dataset and development kits are open-sourced at https://github.com/taco-group/AirV2X-Perception.
SAFEFLOW: A Principled Protocol for Trustworthy and Transactional Autonomous Agent Systems
Jun 09, 2025Recent advances in large language models (LLMs) and vision-language models (VLMs) have enabled powerful autonomous agents capable of complex reasoning and multi-modal tool use. Despite their growing capabilities, today's agent frameworks remain fragile, lacking principled mechanisms for secure information flow, reliability, and multi-agent coordination. In this work, we introduce SAFEFLOW, a new protocol-level framework for building trustworthy LLM/VLM-based agents. SAFEFLOW enforces fine-grained information flow control (IFC), precisely tracking provenance, integrity, and confidentiality of all the data exchanged between agents, tools, users, and environments. By constraining LLM reasoning to respect these security labels, SAFEFLOW prevents untrusted or adversarial inputs from contaminating high-integrity decisions. To ensure robustness in concurrent multi-agent settings, SAFEFLOW introduces transactional execution, conflict resolution, and secure scheduling over shared state, preserving global consistency across agents. We further introduce mechanisms, including write-ahead logging, rollback, and secure caches, that further enhance resilience against runtime errors and policy violations. To validate the performances, we built SAFEFLOWBENCH, a comprehensive benchmark suite designed to evaluate agent reliability under adversarial, noisy, and concurrent operational conditions. Extensive experiments demonstrate that agents built with SAFEFLOW maintain impressive task performance and security guarantees even in hostile environments, substantially outperforming state-of-the-art. Together, SAFEFLOW and SAFEFLOWBENCH lay the groundwork for principled, robust, and secure agent ecosystems, advancing the frontier of reliable autonomy.
Sounding that Object: Interactive Object-Aware Image to Audio Generation
Jun 04, 2025Generating accurate sounds for complex audio-visual scenes is challenging, especially in the presence of multiple objects and sound sources. In this paper, we propose an {\em interactive object-aware audio generation} model that grounds sound generation in user-selected visual objects within images. Our method integrates object-centric learning into a conditional latent diffusion model, which learns to associate image regions with their corresponding sounds through multi-modal attention. At test time, our model employs image segmentation to allow users to interactively generate sounds at the {\em object} level. We theoretically validate that our attention mechanism functionally approximates test-time segmentation masks, ensuring the generated audio aligns with selected objects. Quantitative and qualitative evaluations show that our model outperforms baselines, achieving better alignment between objects and their associated sounds. Project page: https://tinglok.netlify.app/files/avobject/
Towards Reliable Large Audio Language Model
May 25, 2025Recent advancements in large audio language models (LALMs) have demonstrated impressive results and promising prospects in universal understanding and reasoning across speech, music, and general sound. However, these models still lack the ability to recognize their knowledge boundaries and refuse to answer questions they don't know proactively. While there have been successful attempts to enhance the reliability of LLMs, reliable LALMs remain largely unexplored. In this paper, we systematically investigate various approaches towards reliable LALMs, including training-free methods such as multi-modal chain-of-thought (MCoT), and training-based methods such as supervised fine-tuning (SFT). Besides, we identify the limitations of previous evaluation metrics and propose a new metric, the Reliability Gain Index (RGI), to assess the effectiveness of different reliable methods. Our findings suggest that both training-free and training-based methods enhance the reliability of LALMs to different extents. Moreover, we find that awareness of reliability is a "meta ability", which can be transferred across different audio modalities, although significant structural and content differences exist among sound, music, and speech.
AudioMorphix: Training-free audio editing with diffusion probabilistic models
May 21, 2025



Editing sound with precision is a crucial yet underexplored challenge in audio content creation. While existing works can manipulate sounds by text instructions or audio exemplar pairs, they often struggled to modify audio content precisely while preserving fidelity to the original recording. In this work, we introduce a novel editing approach that enables localized modifications to specific time-frequency regions while keeping the remaining of the audio intact by operating on spectrograms directly. To achieve this, we propose AudioMorphix, a training-free audio editor that manipulates a target region on the spectrogram by referring to another recording. Inspired by morphing theory, we conceptualize audio mixing as a process where different sounds blend seamlessly through morphing and can be decomposed back into individual components via demorphing. Our AudioMorphix optimizes the noised latent conditioned on raw input and reference audio while rectifying the guided diffusion process through a series of energy functions. Additionally, we enhance self-attention layers with a cache mechanism to preserve detailed characteristics from the original recordings. To advance audio editing research, we devise a new evaluation benchmark, which includes a curated dataset with a variety of editing instructions. Extensive experiments demonstrate that AudioMorphix yields promising performance on various audio editing tasks, including addition, removal, time shifting and stretching, and pitch shifting, achieving high fidelity and precision. Demo and code are available at this url.