 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025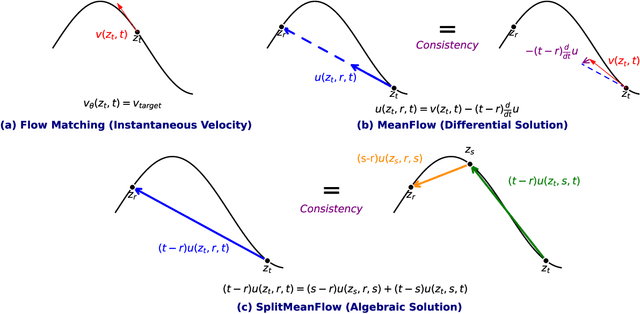


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Nov 19, 2021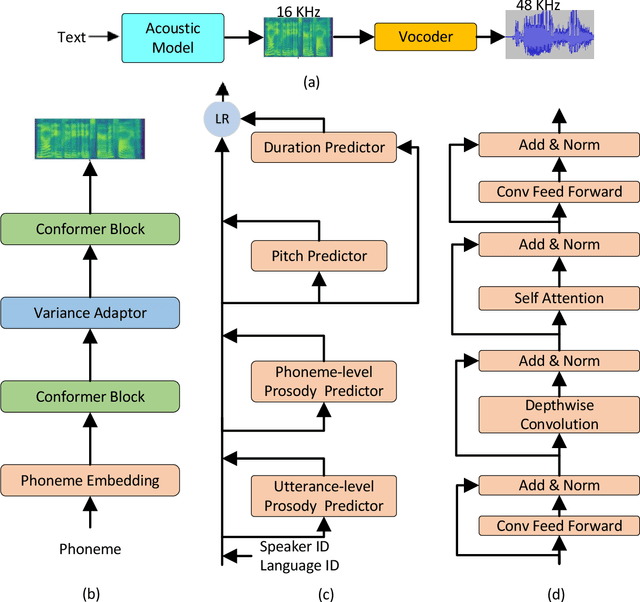
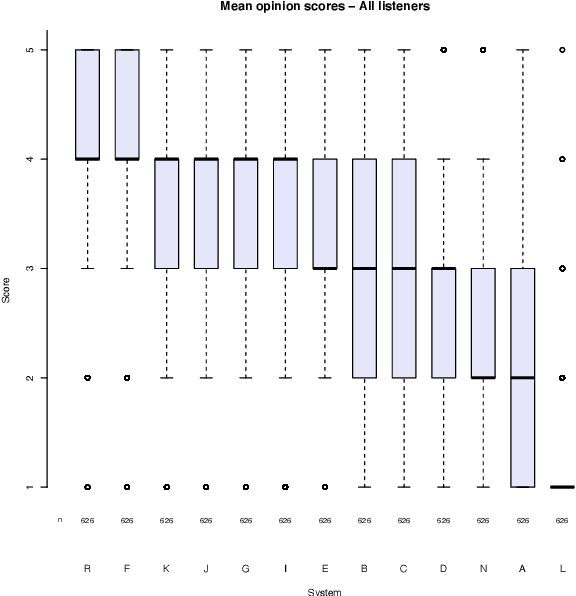
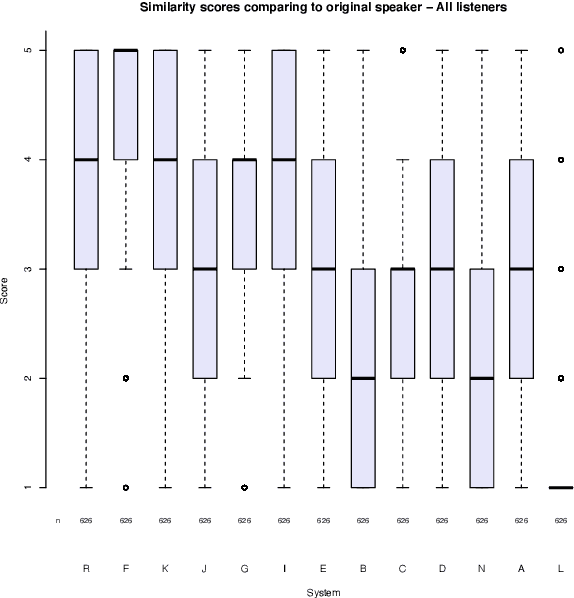
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system