 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTS: A Drone-Based AI-Powered Real-Time Traffic Incident Detection System
Oct 29, 2025Rapid and reliable incident detection is critical for reducing crash-related fatalities, injuries, and congestion. However, conventional methods, such as closed-circuit television, dashcam footage, and sensor-based detection, separate detection from verification, suffer from limited flexibility, and require dense infrastructure or high penetration rates, restricting adaptability and scalability to shifting incident hotspots. To overcome these challenges, we developed DARTS, a drone-based, AI-powered real-time traffic incident detection system. DARTS integrates drones' high mobility and aerial perspective for adaptive surveillance, thermal imaging for better low-visibility performance and privacy protection, and a lightweight deep learning framework for real-time vehicle trajectory extraction and incident detection. The system achieved 99% detection accuracy on a self-collected dataset and supports simultaneous online visual verification, severity assessment, and incident-induced congestion propagation monitoring via a web-based interface. In a field test on Interstate 75 in Florida, DARTS detected and verified a rear-end collision 12 minutes earlier than the local transportation management center and monitored incident-induced congestion propagation, suggesting potential to support faster emergency response and enable proactive traffic control to reduce congestion and secondary crash risk. Crucially, DARTS's flexible deployment architecture reduces dependence on frequent physical patrols, indicating potential scalability and cost-effectiveness for use in remote areas and resource-constrained settings. This study presents a promising step toward a more flexible and integrated real-time traffic incident detection system, with significant implications for the operational efficiency and responsiveness of modern transportation management.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025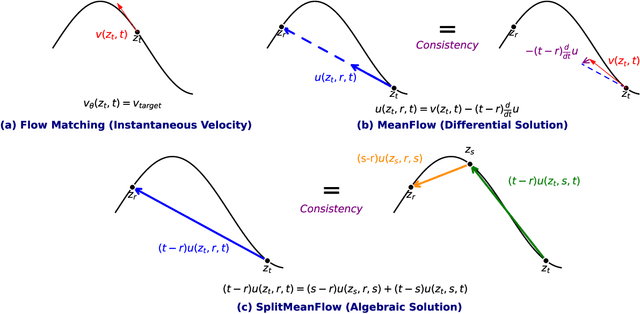


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.