 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Achieving Forgetting-free and Positive Knowledge Transfer
Jan 09, 2026Existing research on continual learning (CL) of a sequence of tasks focuses mainly on dealing with catastrophic forgetting (CF) to balance the learning plasticity of new tasks and the memory stability of old tasks. However, an ideal CL agent should not only be able to overcome CF, but also encourage positive forward and backward knowledge transfer (KT), i.e., using the learned knowledge from previous tasks for the new task learning (namely FKT), and improving the previous tasks' performance with the knowledge of the new task (namely BKT). To this end, this paper first models CL as an optimization problem in which each sequential learning task aims to achieve its optimal performance under the constraint that both FKT and BKT should be positive. It then proposes a novel Enhanced Task Continual Learning (ETCL) method, which achieves forgetting-free and positive KT. Furthermore, the bounds that can lead to negative FKT and BKT are estimated theoretically. Based on the bounds, a new strategy for online task similarity detection is also proposed to facilitate positive KT. To overcome CF, ETCL learns a set of task-specific binary masks to isolate a sparse sub-network for each task while preserving the performance of a dense network for the task. At the beginning of a new task learning, ETCL tries to align the new task's gradient with that of the sub-network of the previous most similar task to ensure positive FKT. By using a new bi-objective optimization strategy and an orthogonal gradient projection method, ETCL updates only the weights of previous similar tasks at the classification layer to achieve positive BKT. Extensive evaluations demonstrate that the proposed ETCL markedly outperforms strong baselines on dissimilar, similar, and mixed task sequences.
Defeating Catastrophic Forgetting via Enhanced Orthogonal Weights Modification
Nov 19, 2021
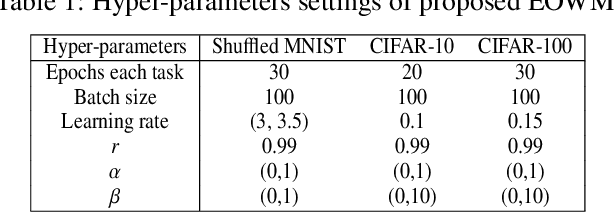
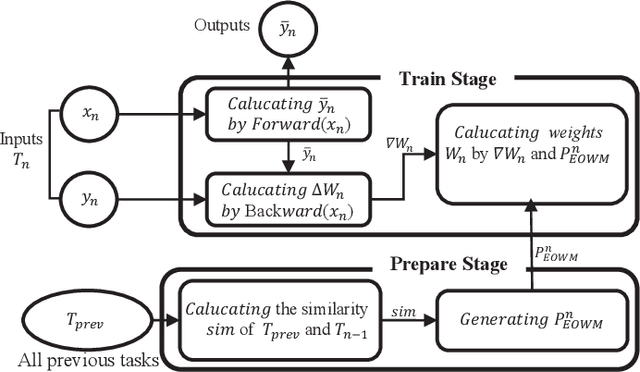
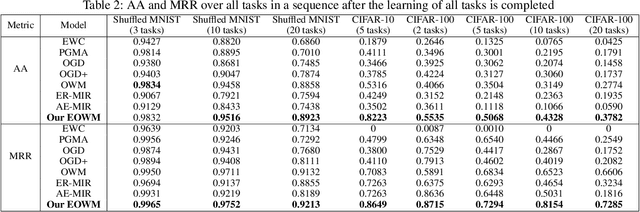
The ability of neural networks (NNs) to learn and remember multiple tasks sequentially is facing tough challenges in achieving general artificial intelligence due to their catastrophic forgetting (CF) issues. Fortunately, the latest OWM Orthogonal Weights Modification) and other several continual learning (CL) methods suggest some promising ways to overcome the CF issue. However, none of existing CL methods explores the following three crucial questions for effectively overcoming the CF issue: that is, what knowledge does it contribute to the effective weights modification of the NN during its sequential tasks learning? When the data distribution of a new learning task changes corresponding to the previous learned tasks, should a uniform/specific weight modification strategy be adopted or not? what is the upper bound of the learningable tasks sequentially for a given CL method? ect. To achieve this, in this paper, we first reveals the fact that of the weight gradient of a new learning task is determined by both the input space of the new task and the weight space of the previous learned tasks sequentially. On this observation and the recursive least square optimal method, we propose a new efficient and effective continual learning method EOWM via enhanced OWM. And we have theoretically and definitively given the upper bound of the learningable tasks sequentially of our EOWM. Extensive experiments conducted on the benchmarks demonstrate that our EOWM is effectiveness and outperform all of the state-of-the-art CL baselines.
Enhanced countering adversarial attacks via input denoising and feature restoring
Nov 19, 2021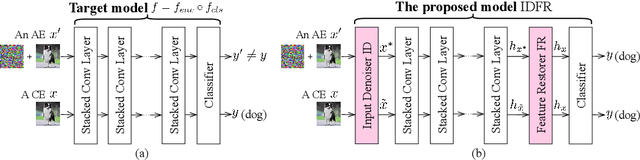
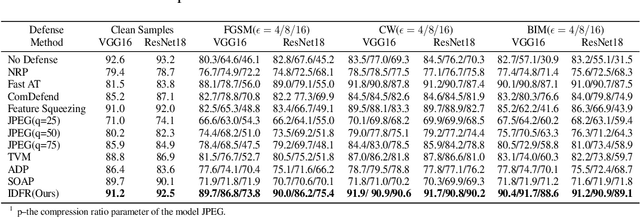
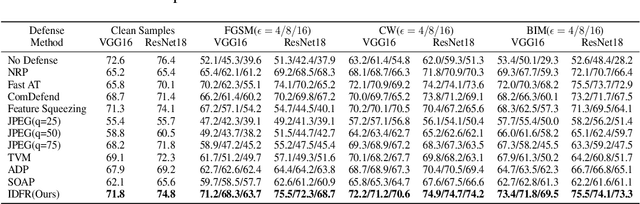
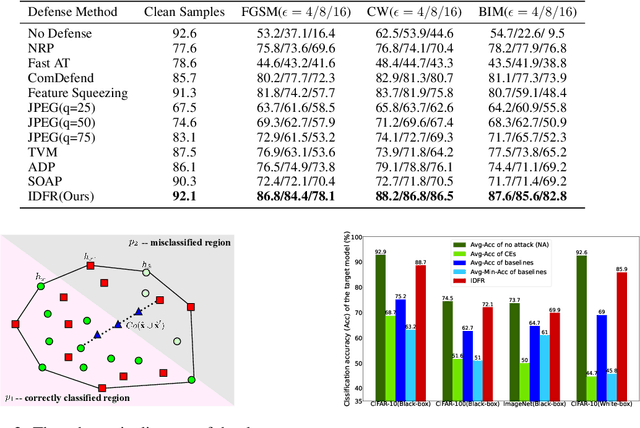
Despite the fact that deep neural networks (DNNs) have achieved prominent performance in various applications, it is well known that DNNs are vulnerable to adversarial examples/samples (AEs) with imperceptible perturbations in clean/original samples. To overcome the weakness of the existing defense methods against adversarial attacks, which damages the information on the original samples, leading to the decrease of the target classifier accuracy, this paper presents an enhanced countering adversarial attack method IDFR (via Input Denoising and Feature Restoring). The proposed IDFR is made up of an enhanced input denoiser (ID) and a hidden lossy feature restorer (FR) based on the convex hull optimization. Extensive experiments conducted on benchmark datasets show that the proposed IDFR outperforms the various state-of-the-art defense methods, and is highly effective for protecting target models against various adversarial black-box or white-box attacks. \footnote{Souce code is released at: \href{https://github.com/ID-FR/IDFR}{https://github.com/ID-FR/IDFR}}