 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Trustworthy Report Generation: A Deep Research Agent with Progressive Confidence Estimation and Calibration
Apr 07, 2026As agent-based systems continue to evolve, deep research agents are capable of automatically generating research-style reports across diverse domains. While these agents promise to streamline information synthesis and knowledge exploration, existing evaluation frameworks-typically based on subjective dimensions-fail to capture a critical aspect of report quality: trustworthiness. In open-ended research scenarios where ground-truth answers are unavailable, current evaluation methods cannot effectively measure the epistemic confidence of generated content, making calibration difficult and leaving users susceptible to misleading or hallucinated information. To address this limitation, we propose a novel deep research agent that incorporates progressive confidence estimation and calibration within the report generation pipeline. Our system leverages a deliberative search model, featuring deep retrieval and multi-hop reasoning to ground outputs in verifiable evidence while assigning confidence scores to individual claims. Combined with a carefully designed workflow, this approach produces trustworthy reports with enhanced transparency. Experimental results and case studies demonstrate that our method substantially improves interpretability and significantly increases user trust.
Efficient Document Parsing via Parallel Token Prediction
Mar 16, 2026Document parsing, as a fundamental yet crucial vision task, is being revolutionized by vision-language models (VLMs). However, the autoregressive (AR) decoding inherent to VLMs creates a significant bottleneck, severely limiting parsing speed. In this paper, we propose Parallel-Token Prediction (PTP), a plugable, model-agnostic and simple-yet-effective method that enables VLMs to generate multiple future tokens in parallel with improved sample efficiency. Specifically, we insert some learnable tokens into the input sequence and design corresponding training objectives to equip the model with parallel decoding capabilities for document parsing. Furthermore, to support effective training, we develop a comprehensive data generation pipeline that efficiently produces large-scale, high-quality document parsing training data for VLMs. Extensive experiments on OmniDocBench and olmOCR-bench demonstrate that our method not only significantly improves decoding speed (1.6x-2.2x) but also reduces model hallucinations and exhibits strong generalization abilities.
Large-Scale Multidimensional Knowledge Profiling of Scientific Literature
Jan 21, 2026The rapid expansion of research across machine learning, vision, and language has produced a volume of publications that is increasingly difficult to synthesize. Traditional bibliometric tools rely mainly on metadata and offer limited visibility into the semantic content of papers, making it hard to track how research themes evolve over time or how different areas influence one another. To obtain a clearer picture of recent developments, we compile a unified corpus of more than 100,000 papers from 22 major conferences between 2020 and 2025 and construct a multidimensional profiling pipeline to organize and analyze their textual content. By combining topic clustering, LLM-assisted parsing, and structured retrieval, we derive a comprehensive representation of research activity that supports the study of topic lifecycles, methodological transitions, dataset and model usage patterns, and institutional research directions. Our analysis highlights several notable shifts, including the growth of safety, multimodal reasoning, and agent-oriented studies, as well as the gradual stabilization of areas such as neural machine translation and graph-based methods. These findings provide an evidence-based view of how AI research is evolving and offer a resource for understanding broader trends and identifying emerging directions. Code and dataset: https://github.com/xzc-zju/Profiling_Scientific_Literature
RFM-Editing: Rectified Flow Matching for Text-guided Audio Editing
Sep 17, 2025Diffusion models have shown remarkable progress in text-to-audio generation. However, text-guided audio editing remains in its early stages. This task focuses on modifying the target content within an audio signal while preserving the rest, thus demanding precise localization and faithful editing according to the text prompt. Existing training-based and zero-shot methods that rely on full-caption or costly optimization often struggle with complex editing or lack practicality. In this work, we propose a novel end-to-end efficient rectified flow matching-based diffusion framework for audio editing, and construct a dataset featuring overlapping multi-event audio to support training and benchmarking in complex scenarios. Experiments show that our model achieves faithful semantic alignment without requiring auxiliary captions or masks, while maintaining competitive editing quality across metrics.
Learning ECG Representations via Poly-Window Contrastive Learning
Aug 21, 2025



Electrocardiogram (ECG) analysis is foundational for cardiovascular disease diagnosis, yet the performance of deep learning models is often constrained by limited access to annotated data. Self-supervised contrastive learning has emerged as a powerful approach for learning robust ECG representations from unlabeled signals. However, most existing methods generate only pairwise augmented views and fail to leverage the rich temporal structure of ECG recordings. In this work, we present a poly-window contrastive learning framework. We extract multiple temporal windows from each ECG instance to construct positive pairs and maximize their agreement via statistics. Inspired by the principle of slow feature analysis, our approach explicitly encourages the model to learn temporally invariant and physiologically meaningful features that persist across time. We validate our approach through extensive experiments and ablation studies on the PTB-XL dataset. Our results demonstrate that poly-window contrastive learning consistently outperforms conventional two-view methods in multi-label superclass classification, achieving higher AUROC (0.891 vs. 0.888) and F1 scores (0.680 vs. 0.679) while requiring up to four times fewer pre-training epochs (32 vs. 128) and 14.8% in total wall clock pre-training time reduction. Despite processing multiple windows per sample, we achieve a significant reduction in the number of training epochs and total computation time, making our method practical for training foundational models. Through extensive ablations, we identify optimal design choices and demonstrate robustness across various hyperparameters. These findings establish poly-window contrastive learning as a highly efficient and scalable paradigm for automated ECG analysis and provide a promising general framework for self-supervised representation learning in biomedical time-series data.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025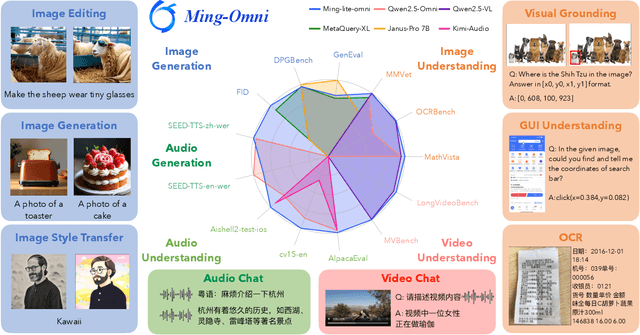
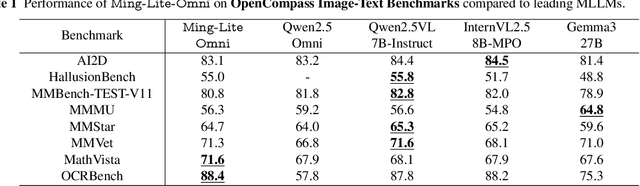
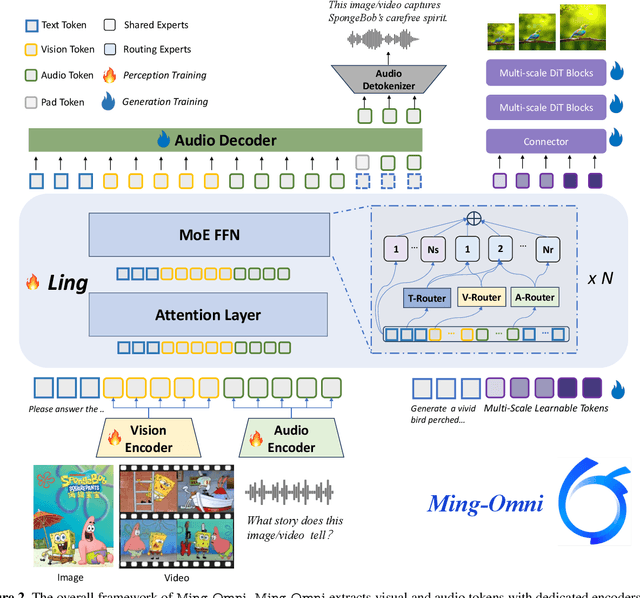
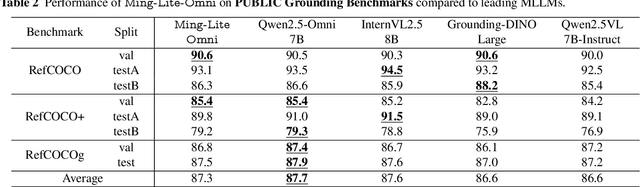
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
AudioMorphix: Training-free audio editing with diffusion probabilistic models
May 21, 2025



Editing sound with precision is a crucial yet underexplored challenge in audio content creation. While existing works can manipulate sounds by text instructions or audio exemplar pairs, they often struggled to modify audio content precisely while preserving fidelity to the original recording. In this work, we introduce a novel editing approach that enables localized modifications to specific time-frequency regions while keeping the remaining of the audio intact by operating on spectrograms directly. To achieve this, we propose AudioMorphix, a training-free audio editor that manipulates a target region on the spectrogram by referring to another recording. Inspired by morphing theory, we conceptualize audio mixing as a process where different sounds blend seamlessly through morphing and can be decomposed back into individual components via demorphing. Our AudioMorphix optimizes the noised latent conditioned on raw input and reference audio while rectifying the guided diffusion process through a series of energy functions. Additionally, we enhance self-attention layers with a cache mechanism to preserve detailed characteristics from the original recordings. To advance audio editing research, we devise a new evaluation benchmark, which includes a curated dataset with a variety of editing instructions. Extensive experiments demonstrate that AudioMorphix yields promising performance on various audio editing tasks, including addition, removal, time shifting and stretching, and pitch shifting, achieving high fidelity and precision. Demo and code are available at this url.
FlowSep: Language-Queried Sound Separation with Rectified Flow Matching
Sep 11, 2024



Language-queried audio source separation (LASS) focuses on separating sounds using textual descriptions of the desired sources. Current methods mainly use discriminative approaches, such as time-frequency masking, to separate target sounds and minimize interference from other sources. However, these models face challenges when separating overlapping soundtracks, which may lead to artifacts such as spectral holes or incomplete separation. Rectified flow matching (RFM), a generative model that establishes linear relations between the distribution of data and noise, offers superior theoretical properties and simplicity, but has not yet been explored in sound separation. In this work, we introduce FlowSep, a new generative model based on RFM for LASS tasks. FlowSep learns linear flow trajectories from noise to target source features within the variational autoencoder (VAE) latent space. During inference, the RFM-generated latent features are reconstructed into a mel-spectrogram via the pre-trained VAE decoder, followed by a pre-trained vocoder to synthesize the waveform. Trained on 1,680 hours of audio data, FlowSep outperforms the state-of-the-art models across multiple benchmarks, as evaluated with subjective and objective metrics. Additionally, our results show that FlowSep surpasses a diffusion-based LASS model in both separation quality and inference efficiency, highlighting its strong potential for audio source separation tasks. Code, pre-trained models and demos can be found at: https://audio-agi.github.io/FlowSep_demo/.
Universal Sound Separation with Self-Supervised Audio Masked Autoencoder
Jul 16, 2024Universal sound separation (USS) is a task of separating mixtures of arbitrary sound sources. Typically, universal separation models are trained from scratch in a supervised manner, using labeled data. Self-supervised learning (SSL) is an emerging deep learning approach that leverages unlabeled data to obtain task-agnostic representations, which can benefit many downstream tasks. In this paper, we propose integrating a self-supervised pre-trained model, namely the audio masked autoencoder (A-MAE), into a universal sound separation system to enhance its separation performance. We employ two strategies to utilize SSL embeddings: freezing or updating the parameters of A-MAE during fine-tuning. The SSL embeddings are concatenated with the short-time Fourier transform (STFT) to serve as input features for the separation model. We evaluate our methods on the AudioSet dataset, and the experimental results indicate that the proposed methods successfully enhance the separation performance of a state-of-the-art ResUNet-based USS model.
Improving Audio Generation with Visual Enhanced Caption
Jul 05, 2024



Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the low quality and relatively small quantity of training data. In this work, we aim to create a large-scale audio dataset with rich captions for improving audio generation models. We develop an automated pipeline to generate detailed captions for audio-visual datasets by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). We introduce Sound-VECaps, a dataset comprising 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We demonstrate that training with Sound-VECaps significantly enhances the capability of text-to-audio generation models to comprehend and generate audio from complex input prompts, improving overall system performance. Furthermore, we conduct ablation studies of Sound-VECaps across several audio-language tasks, suggesting its potential in advancing audio-text representation learning. Our dataset and models are available online.