 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Object Representations with Contrastive Learning
Jun 10, 2019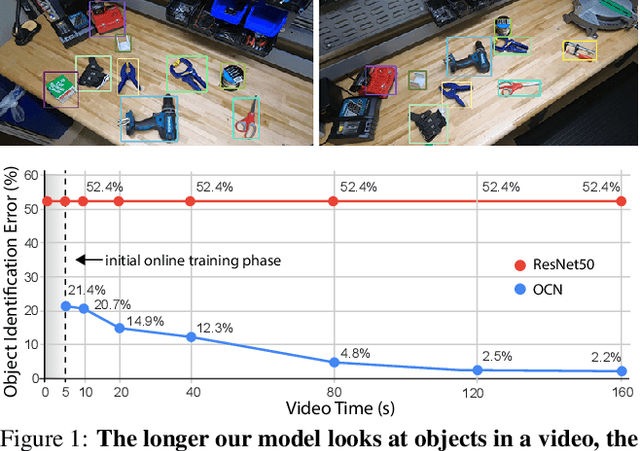
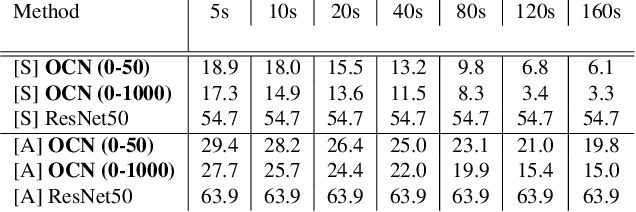
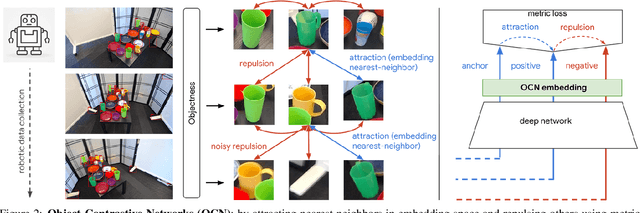

We propose a self-supervised approach for learning representations of objects from monocular videos and demonstrate it is particularly useful in situated settings such as robotics. The main contributions of this paper are: 1) a self-supervising objective trained with contrastive learning that can discover and disentangle object attributes from video without using any labels; 2) we leverage object self-supervision for online adaptation: the longer our online model looks at objects in a video, the lower the object identification error, while the offline baseline remains with a large fixed error; 3) to explore the possibilities of a system entirely free of human supervision, we let a robot collect its own data, train on this data with our self-supervise scheme, and then show the robot can point to objects similar to the one presented in front of it, demonstrating generalization of object attributes. An interesting and perhaps surprising finding of this approach is that given a limited set of objects, object correspondences will naturally emerge when using contrastive learning without requiring explicit positive pairs. Videos illustrating online object adaptation and robotic pointing are available at: https://online-objects.github.io/.
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019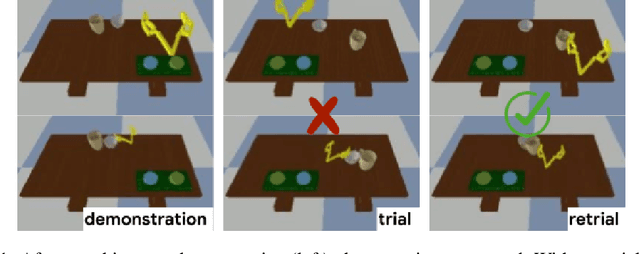
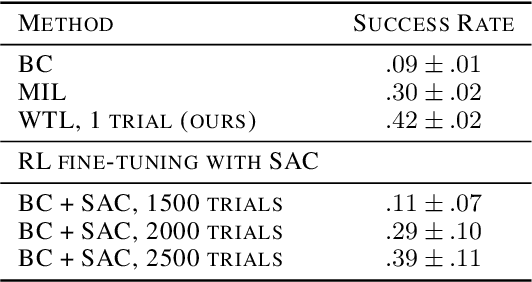
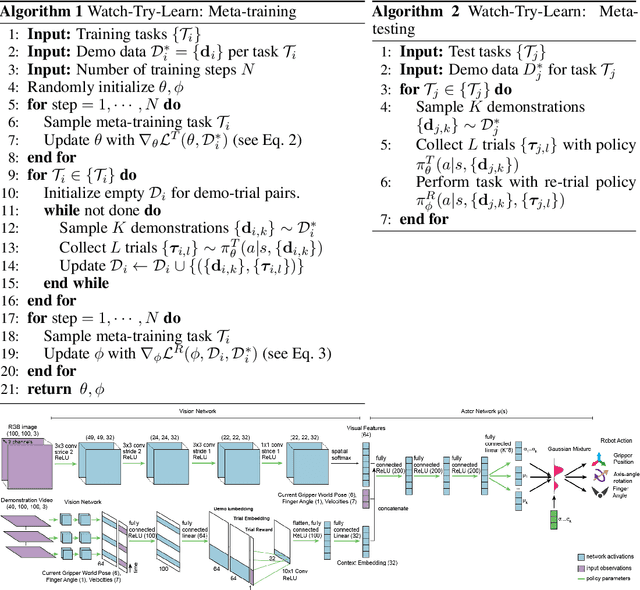
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.
Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Jun 15, 2018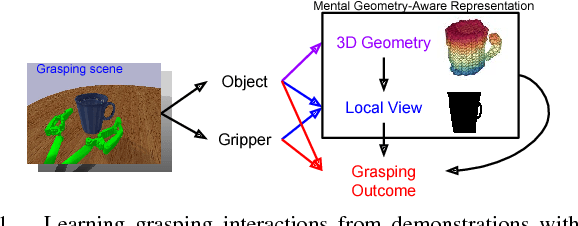
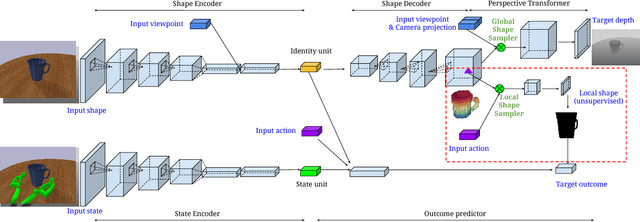
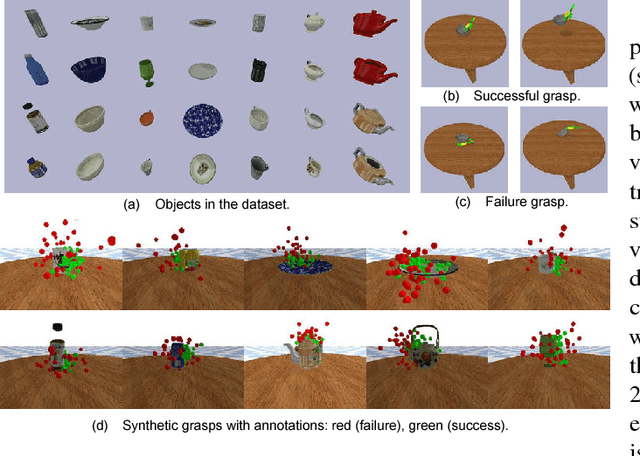
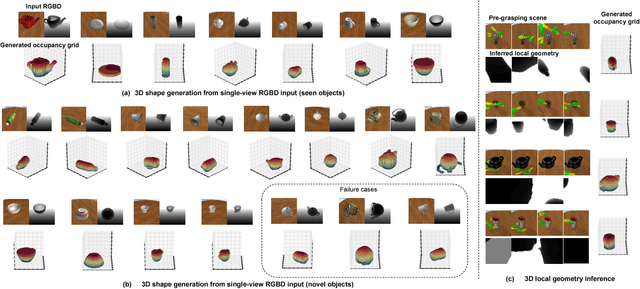
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
May 16, 2018

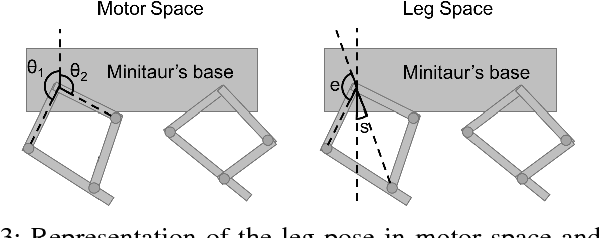
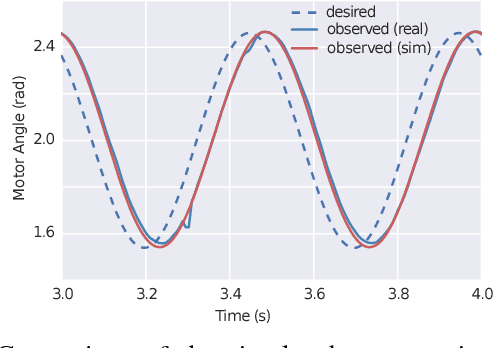
Designing agile locomotion for quadruped robots often requires extensive expertise and tedious manual tuning. In this paper, we present a system to automate this process by leveraging deep reinforcement learning techniques. Our system can learn quadruped locomotion from scratch using simple reward signals. In addition, users can provide an open loop reference to guide the learning process when more control over the learned gait is needed. The control policies are learned in a physics simulator and then deployed on real robots. In robotics, policies trained in simulation often do not transfer to the real world. We narrow this reality gap by improving the physics simulator and learning robust policies. We improve the simulation using system identification, developing an accurate actuator model and simulating latency. We learn robust controllers by randomizing the physical environments, adding perturbations and designing a compact observation space. We evaluate our system on two agile locomotion gaits: trotting and galloping. After learning in simulation, a quadruped robot can successfully perform both gaits in the real world.
Multi-Task Domain Adaptation for Deep Learning of Instance Grasping from Simulation
Mar 04, 2018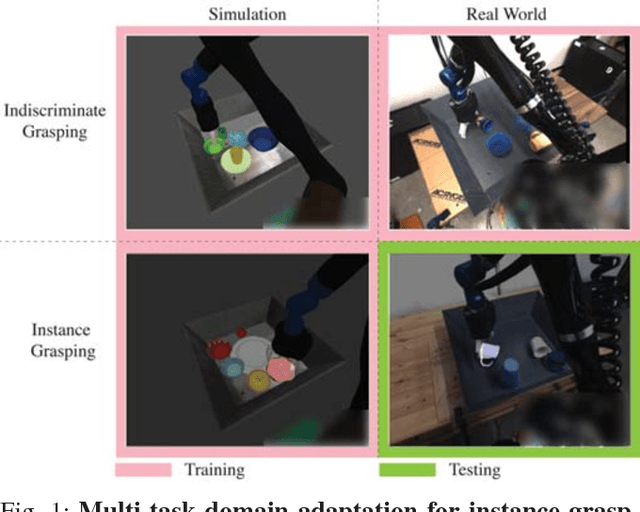

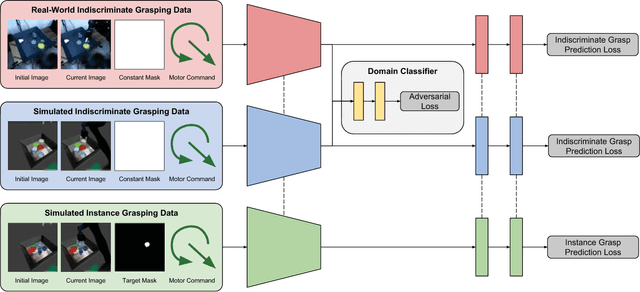
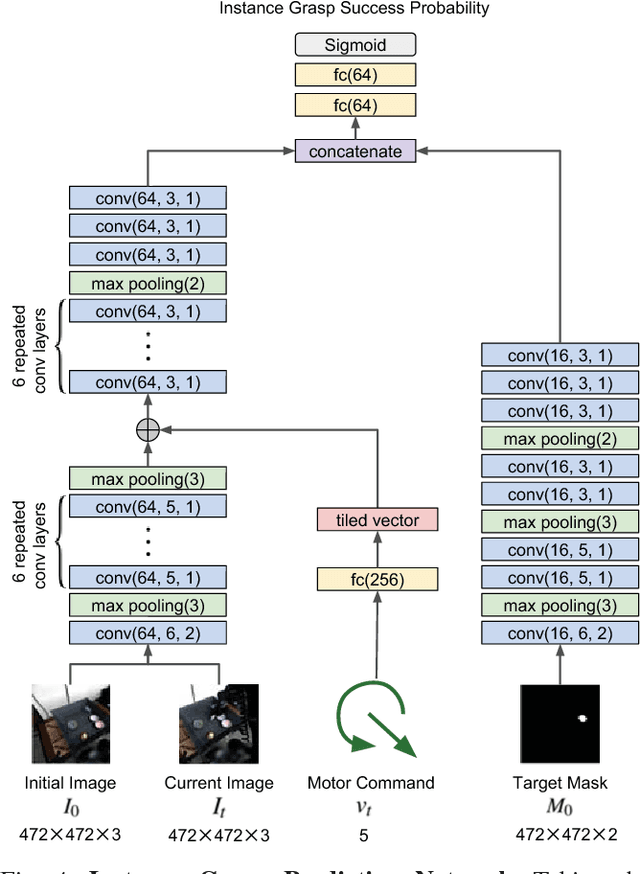
Learning-based approaches to robotic manipulation are limited by the scalability of data collection and accessibility of labels. In this paper, we present a multi-task domain adaptation framework for instance grasping in cluttered scenes by utilizing simulated robot experiments. Our neural network takes monocular RGB images and the instance segmentation mask of a specified target object as inputs, and predicts the probability of successfully grasping the specified object for each candidate motor command. The proposed transfer learning framework trains a model for instance grasping in simulation and uses a domain-adversarial loss to transfer the trained model to real robots using indiscriminate grasping data, which is available both in simulation and the real world. We evaluate our model in real-world robot experiments, comparing it with alternative model architectures as well as an indiscriminate grasping baseline.
Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
Sep 25, 2017


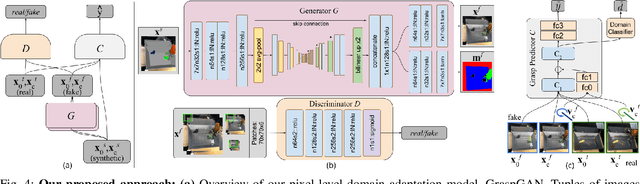
Instrumenting and collecting annotated visual grasping datasets to train modern machine learning algorithms can be extremely time-consuming and expensive. An appealing alternative is to use off-the-shelf simulators to render synthetic data for which ground-truth annotations are generated automatically. Unfortunately, models trained purely on simulated data often fail to generalize to the real world. We study how randomized simulated environments and domain adaptation methods can be extended to train a grasping system to grasp novel objects from raw monocular RGB images. We extensively evaluate our approaches with a total of more than 25,000 physical test grasps, studying a range of simulation conditions and domain adaptation methods, including a novel extension of pixel-level domain adaptation that we term the GraspGAN. We show that, by using synthetic data and domain adaptation, we are able to reduce the number of real-world samples needed to achieve a given level of performance by up to 50 times, using only randomly generated simulated objects. We also show that by using only unlabeled real-world data and our GraspGAN methodology, we obtain real-world grasping performance without any real-world labels that is similar to that achieved with 939,777 labeled real-world samples.