 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSVMA+: Exploring Multi-granularity Semantic-visual Adaption for Generalized Zero-shot Learning
Oct 15, 2024



Generalized zero-shot learning (GZSL) endeavors to identify the unseen categories using knowledge from the seen domain, necessitating the intrinsic interactions between the visual features and attribute semantic features. However, GZSL suffers from insufficient visual-semantic correspondences due to the attribute diversity and instance diversity. Attribute diversity refers to varying semantic granularity in attribute descriptions, ranging from low-level (specific, directly observable) to high-level (abstract, highly generic) characteristics. This diversity challenges the collection of adequate visual cues for attributes under a uni-granularity. Additionally, diverse visual instances corresponding to the same sharing attributes introduce semantic ambiguity, leading to vague visual patterns. To tackle these problems, we propose a multi-granularity progressive semantic-visual mutual adaption (PSVMA+) network, where sufficient visual elements across granularity levels can be gathered to remedy the granularity inconsistency. PSVMA+ explores semantic-visual interactions at different granularity levels, enabling awareness of multi-granularity in both visual and semantic elements. At each granularity level, the dual semantic-visual transformer module (DSVTM) recasts the sharing attributes into instance-centric attributes and aggregates the semantic-related visual regions, thereby learning unambiguous visual features to accommodate various instances. Given the diverse contributions of different granularities, PSVMA+ employs selective cross-granularity learning to leverage knowledge from reliable granularities and adaptively fuses multi-granularity features for comprehensive representations. Experimental results demonstrate that PSVMA+ consistently outperforms state-of-the-art methods.
Bridge the Points: Graph-based Few-shot Segment Anything Semantically
Oct 09, 2024



The recent advancements in large-scale pre-training techniques have significantly enhanced the capabilities of vision foundation models, notably the Segment Anything Model (SAM), which can generate precise masks based on point and box prompts. Recent studies extend SAM to Few-shot Semantic Segmentation (FSS), focusing on prompt generation for SAM-based automatic semantic segmentation. However, these methods struggle with selecting suitable prompts, require specific hyperparameter settings for different scenarios, and experience prolonged one-shot inference times due to the overuse of SAM, resulting in low efficiency and limited automation ability. To address these issues, we propose a simple yet effective approach based on graph analysis. In particular, a Positive-Negative Alignment module dynamically selects the point prompts for generating masks, especially uncovering the potential of the background context as the negative reference. Another subsequent Point-Mask Clustering module aligns the granularity of masks and selected points as a directed graph, based on mask coverage over points. These points are then aggregated by decomposing the weakly connected components of the directed graph in an efficient manner, constructing distinct natural clusters. Finally, the positive and overshooting gating, benefiting from graph-based granularity alignment, aggregate high-confident masks and filter out the false-positive masks for final prediction, reducing the usage of additional hyperparameters and redundant mask generation. Extensive experimental analysis across standard FSS, One-shot Part Segmentation, and Cross Domain FSS datasets validate the effectiveness and efficiency of the proposed approach, surpassing state-of-the-art generalist models with a mIoU of 58.7% on COCO-20i and 35.2% on LVIS-92i. The code is available in https://andyzaq.github.io/GF-SAM/.
Collapsed Language Models Promote Fairness
Oct 06, 2024



To mitigate societal biases implicitly encoded in recent successful pretrained language models, a diverse array of approaches have been proposed to encourage model fairness, focusing on prompting, data augmentation, regularized fine-tuning, and more. Despite the development, it is nontrivial to reach a principled understanding of fairness and an effective algorithm that can consistently debias language models. In this work, by rigorous evaluations of Neural Collapse -- a learning phenomenon happen in last-layer representations and classifiers in deep networks -- on fairness-related words, we find that debiased language models exhibit collapsed alignment between token representations and word embeddings. More importantly, this observation inspires us to design a principled fine-tuning method that can effectively improve fairness in a wide range of debiasing methods, while still preserving the performance of language models on standard natural language understanding tasks. We attach our code at https://anonymous.4open.science/r/Fairness_NC-457E .
C2P-CLIP: Injecting Category Common Prompt in CLIP to Enhance Generalization in Deepfake Detection
Aug 19, 2024



This work focuses on AIGC detection to develop universal detectors capable of identifying various types of forgery images. Recent studies have found large pre-trained models, such as CLIP, are effective for generalizable deepfake detection along with linear classifiers. However, two critical issues remain unresolved: 1) understanding why CLIP features are effective on deepfake detection through a linear classifier; and 2) exploring the detection potential of CLIP. In this study, we delve into the underlying mechanisms of CLIP's detection capabilities by decoding its detection features into text and performing word frequency analysis. Our finding indicates that CLIP detects deepfakes by recognizing similar concepts (Fig. \ref{fig:fig1} a). Building on this insight, we introduce Category Common Prompt CLIP, called C2P-CLIP, which integrates the category common prompt into the text encoder to inject category-related concepts into the image encoder, thereby enhancing detection performance (Fig. \ref{fig:fig1} b). Our method achieves a 12.41\% improvement in detection accuracy compared to the original CLIP, without introducing additional parameters during testing. Comprehensive experiments conducted on two widely-used datasets, encompassing 20 generation models, validate the efficacy of the proposed method, demonstrating state-of-the-art performance. The code is available at \url{https://github.com/chuangchuangtan/C2P-CLIP-DeepfakeDetection}
SLCA++: Unleash the Power of Sequential Fine-tuning for Continual Learning with Pre-training
Aug 15, 2024In recent years, continual learning with pre-training (CLPT) has received widespread interest, instead of its traditional focus of training from scratch. The use of strong pre-trained models (PTMs) can greatly facilitate knowledge transfer and alleviate catastrophic forgetting, but also suffers from progressive overfitting of pre-trained knowledge into specific downstream tasks. A majority of current efforts often keep the PTMs frozen and incorporate task-specific prompts to instruct representation learning, coupled with a prompt selection process for inference. However, due to the limited capacity of prompt parameters, this strategy demonstrates only sub-optimal performance in continual learning. In comparison, tuning all parameters of PTMs often provides the greatest potential for representation learning, making sequential fine-tuning (Seq FT) a fundamental baseline that has been overlooked in CLPT. To this end, we present an in-depth analysis of the progressive overfitting problem from the lens of Seq FT. Considering that the overly fast representation learning and the biased classification layer constitute this particular problem, we introduce the advanced Slow Learner with Classifier Alignment (SLCA++) framework to unleash the power of Seq FT, serving as a strong baseline approach for CLPT. Our approach involves a Slow Learner to selectively reduce the learning rate of backbone parameters, and a Classifier Alignment to align the disjoint classification layers in a post-hoc fashion. We further enhance the efficacy of SL with a symmetric cross-entropy loss, as well as employ a parameter-efficient strategy to implement Seq FT with SLCA++. Across a variety of continual learning scenarios on image classification benchmarks, our approach provides substantial improvements and outperforms state-of-the-art methods by a large margin. Code: https://github.com/GengDavid/SLCA.
DreamLCM: Towards High-Quality Text-to-3D Generation via Latent Consistency Model
Aug 06, 2024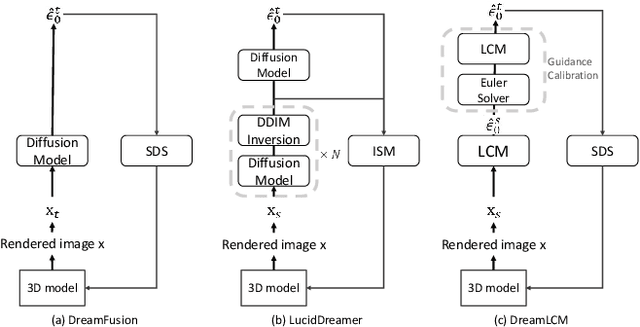
Recently, the text-to-3D task has developed rapidly due to the appearance of the SDS method. However, the SDS method always generates 3D objects with poor quality due to the over-smooth issue. This issue is attributed to two factors: 1) the DDPM single-step inference produces poor guidance gradients; 2) the randomness from the input noises and timesteps averages the details of the 3D contents.In this paper, to address the issue, we propose DreamLCM which incorporates the Latent Consistency Model (LCM). DreamLCM leverages the powerful image generation capabilities inherent in LCM, enabling generating consistent and high-quality guidance, i.e., predicted noises or images. Powered by the improved guidance, the proposed method can provide accurate and detailed gradients to optimize the target 3D models.In addition, we propose two strategies to enhance the generation quality further. Firstly, we propose a guidance calibration strategy, utilizing Euler Solver to calibrate the guidance distribution to accelerate 3D models to converge. Secondly, we propose a dual timestep strategy, increasing the consistency of guidance and optimizing 3D models from geometry to appearance in DreamLCM. Experiments show that DreamLCM achieves state-of-the-art results in both generation quality and training efficiency. The code is available at https://github.com/1YimingZhong/DreamLCM.
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
Aug 05, 2024



With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
Collaborative Vision-Text Representation Optimizing for Open-Vocabulary Segmentation
Aug 01, 2024



Pre-trained vision-language models, e.g. CLIP, have been increasingly used to address the challenging Open-Vocabulary Segmentation (OVS) task, benefiting from their well-aligned vision-text embedding space. Typical solutions involve either freezing CLIP during training to unilaterally maintain its zero-shot capability, or fine-tuning CLIP vision encoder to achieve perceptual sensitivity to local regions. However, few of them incorporate vision-text collaborative optimization. Based on this, we propose the Content-Dependent Transfer to adaptively enhance each text embedding by interacting with the input image, which presents a parameter-efficient way to optimize the text representation. Besides, we additionally introduce a Representation Compensation strategy, reviewing the original CLIP-V representation as compensation to maintain the zero-shot capability of CLIP. In this way, the vision and text representation of CLIP are optimized collaboratively, enhancing the alignment of the vision-text feature space. To the best of our knowledge, we are the first to establish the collaborative vision-text optimizing mechanism within the OVS field. Extensive experiments demonstrate our method achieves superior performance on popular OVS benchmarks. In open-vocabulary semantic segmentation, our method outperforms the previous state-of-the-art approaches by +0.5, +2.3, +3.4, +0.4 and +1.1 mIoU, respectively on A-847, A-150, PC-459, PC-59 and PAS-20. Furthermore, in a panoptic setting on ADE20K, we achieve the performance of 27.1 PQ, 73.5 SQ, and 32.9 RQ. Code will be available at https://github.com/jiaosiyu1999/MAFT-Plus.git .
ACTRESS: Active Retraining for Semi-supervised Visual Grounding
Jul 03, 2024Semi-Supervised Visual Grounding (SSVG) is a new challenge for its sparse labeled data with the need for multimodel understanding. A previous study, RefTeacher, makes the first attempt to tackle this task by adopting the teacher-student framework to provide pseudo confidence supervision and attention-based supervision. However, this approach is incompatible with current state-of-the-art visual grounding models, which follow the Transformer-based pipeline. These pipelines directly regress results without region proposals or foreground binary classification, rendering them unsuitable for fitting in RefTeacher due to the absence of confidence scores. Furthermore, the geometric difference in teacher and student inputs, stemming from different data augmentations, induces natural misalignment in attention-based constraints. To establish a compatible SSVG framework, our paper proposes the ACTive REtraining approach for Semi-Supervised Visual Grounding, abbreviated as ACTRESS. Initially, the model is enhanced by incorporating an additional quantized detection head to expose its detection confidence. Building upon this, ACTRESS consists of an active sampling strategy and a selective retraining strategy. The active sampling strategy iteratively selects high-quality pseudo labels by evaluating three crucial aspects: Faithfulness, Robustness, and Confidence, optimizing the utilization of unlabeled data. The selective retraining strategy retrains the model with periodic re-initialization of specific parameters, facilitating the model's escape from local minima. Extensive experiments demonstrates our superior performance on widely-used benchmark datasets.
PVUW 2024 Challenge on Complex Video Understanding: Methods and Results
Jun 24, 2024



Pixel-level Video Understanding in the Wild Challenge (PVUW) focus on complex video understanding. In this CVPR 2024 workshop, we add two new tracks, Complex Video Object Segmentation Track based on MOSE dataset and Motion Expression guided Video Segmentation track based on MeViS dataset. In the two new tracks, we provide additional videos and annotations that feature challenging elements, such as the disappearance and reappearance of objects, inconspicuous small objects, heavy occlusions, and crowded environments in MOSE. Moreover, we provide a new motion expression guided video segmentation dataset MeViS to study the natural language-guided video understanding in complex environments. These new videos, sentences, and annotations enable us to foster the development of a more comprehensive and robust pixel-level understanding of video scenes in complex environments and realistic scenarios. The MOSE challenge had 140 registered teams in total, 65 teams participated the validation phase and 12 teams made valid submissions in the final challenge phase. The MeViS challenge had 225 registered teams in total, 50 teams participated the validation phase and 5 teams made valid submissions in the final challenge phase.