 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVibeFlow: Versatile Video Chroma-Lux Editing through Self-Supervised Learning
Apr 15, 2026Video chroma-lux editing, which aims to modify illumination and color while preserving structural and temporal fidelity, remains a significant challenge. Existing methods typically rely on expensive supervised training with synthetic paired data. This paper proposes VibeFlow, a novel self-supervised framework that unleashes the intrinsic physical understanding of pre-trained video generation models. Instead of learning color and light transitions from scratch, we introduce a disentangled data perturbation pipeline that enforces the model to adaptively recombine structure from source videos and color-illumination cues from reference images, enabling robust disentanglement in a self-supervised manner. Furthermore, to rectify discretization errors inherent in flow-based models, we introduce Residual Velocity Fields alongside a Structural Distortion Consistency Regularization, ensuring rigorous structural preservation and temporal coherence. Our framework eliminates the need for costly training resources and generalizes in a zero-shot manner to diverse applications, including video relighting, recoloring, low-light enhancement, day-night translation, and object-specific color editing. Extensive experiments demonstrate that VibeFlow achieves impressive visual quality with significantly reduced computational overhead. Our project is publicly available at https://lyf1212.github.io/VibeFlow-webpage.
Token Pruning for In-Context Generation in Diffusion Transformers
Feb 02, 2026In-context generation significantly enhances Diffusion Transformers (DiTs) by enabling controllable image-to-image generation through reference examples. However, the resulting input concatenation drastically increases sequence length, creating a substantial computational bottleneck. Existing token reduction techniques, primarily tailored for text-to-image synthesis, fall short in this paradigm as they apply uniform reduction strategies, overlooking the inherent role asymmetry between reference contexts and target latents across spatial, temporal, and functional dimensions. To bridge this gap, we introduce ToPi, a training-free token pruning framework tailored for in-context generation in DiTs. Specifically, ToPi utilizes offline calibration-driven sensitivity analysis to identify pivotal attention layers, serving as a robust proxy for redundancy estimation. Leveraging these layers, we derive a novel influence metric to quantify the contribution of each context token for selective pruning, coupled with a temporal update strategy that adapts to the evolving diffusion trajectory. Empirical evaluations demonstrate that ToPi can achieve over 30\% speedup in inference while maintaining structural fidelity and visual consistency across complex image generation tasks.
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
Aug 05, 2024



With the advancement of Multimodal Large Language Models (MLLM), LLM-driven visual agents are increasingly impacting software interfaces, particularly those with graphical user interfaces. This work introduces a novel LLM-based multimodal agent framework for mobile devices. This framework, capable of navigating mobile devices, emulates human-like interactions. Our agent constructs a flexible action space that enhances adaptability across various applications including parser, text and vision descriptions. The agent operates through two main phases: exploration and deployment. During the exploration phase, functionalities of user interface elements are documented either through agent-driven or manual explorations into a customized structured knowledge base. In the deployment phase, RAG technology enables efficient retrieval and update from this knowledge base, thereby empowering the agent to perform tasks effectively and accurately. This includes performing complex, multi-step operations across various applications, thereby demonstrating the framework's adaptability and precision in handling customized task workflows. Our experimental results across various benchmarks demonstrate the framework's superior performance, confirming its effectiveness in real-world scenarios. Our code will be open source soon.
LinguaLinker: Audio-Driven Portraits Animation with Implicit Facial Control Enhancement
Jul 26, 2024This study delves into the intricacies of synchronizing facial dynamics with multilingual audio inputs, focusing on the creation of visually compelling, time-synchronized animations through diffusion-based techniques. Diverging from traditional parametric models for facial animation, our approach, termed LinguaLinker, adopts a holistic diffusion-based framework that integrates audio-driven visual synthesis to enhance the synergy between auditory stimuli and visual responses. We process audio features separately and derive the corresponding control gates, which implicitly govern the movements in the mouth, eyes, and head, irrespective of the portrait's origin. The advanced audio-driven visual synthesis mechanism provides nuanced control but keeps the compatibility of output video and input audio, allowing for a more tailored and effective portrayal of distinct personas across different languages. The significant improvements in the fidelity of animated portraits, the accuracy of lip-syncing, and the appropriate motion variations achieved by our method render it a versatile tool for animating any portrait in any language.
EMMA: Your Text-to-Image Diffusion Model Can Secretly Accept Multi-Modal Prompts
Jun 13, 2024Recent advancements in image generation have enabled the creation of high-quality images from text conditions. However, when facing multi-modal conditions, such as text combined with reference appearances, existing methods struggle to balance multiple conditions effectively, typically showing a preference for one modality over others. To address this challenge, we introduce EMMA, a novel image generation model accepting multi-modal prompts built upon the state-of-the-art text-to-image (T2I) diffusion model, ELLA. EMMA seamlessly incorporates additional modalities alongside text to guide image generation through an innovative Multi-modal Feature Connector design, which effectively integrates textual and supplementary modal information using a special attention mechanism. By freezing all parameters in the original T2I diffusion model and only adjusting some additional layers, we reveal an interesting finding that the pre-trained T2I diffusion model can secretly accept multi-modal prompts. This interesting property facilitates easy adaptation to different existing frameworks, making EMMA a flexible and effective tool for producing personalized and context-aware images and even videos. Additionally, we introduce a strategy to assemble learned EMMA modules to produce images conditioned on multiple modalities simultaneously, eliminating the need for additional training with mixed multi-modal prompts. Extensive experiments demonstrate the effectiveness of EMMA in maintaining high fidelity and detail in generated images, showcasing its potential as a robust solution for advanced multi-modal conditional image generation tasks.
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Mar 08, 2024Diffusion models have demonstrated remarkable performance in the domain of text-to-image generation. However, most widely used models still employ CLIP as their text encoder, which constrains their ability to comprehend dense prompts, encompassing multiple objects, detailed attributes, complex relationships, long-text alignment, etc. In this paper, we introduce an Efficient Large Language Model Adapter, termed ELLA, which equips text-to-image diffusion models with powerful Large Language Models (LLM) to enhance text alignment without training of either U-Net or LLM. To seamlessly bridge two pre-trained models, we investigate a range of semantic alignment connector designs and propose a novel module, the Timestep-Aware Semantic Connector (TSC), which dynamically extracts timestep-dependent conditions from LLM. Our approach adapts semantic features at different stages of the denoising process, assisting diffusion models in interpreting lengthy and intricate prompts over sampling timesteps. Additionally, ELLA can be readily incorporated with community models and tools to improve their prompt-following capabilities. To assess text-to-image models in dense prompt following, we introduce Dense Prompt Graph Benchmark (DPG-Bench), a challenging benchmark consisting of 1K dense prompts. Extensive experiments demonstrate the superiority of ELLA in dense prompt following compared to state-of-the-art methods, particularly in multiple object compositions involving diverse attributes and relationships.
FaceStudio: Put Your Face Everywhere in Seconds
Dec 06, 2023This study investigates identity-preserving image synthesis, an intriguing task in image generation that seeks to maintain a subject's identity while adding a personalized, stylistic touch. Traditional methods, such as Textual Inversion and DreamBooth, have made strides in custom image creation, but they come with significant drawbacks. These include the need for extensive resources and time for fine-tuning, as well as the requirement for multiple reference images. To overcome these challenges, our research introduces a novel approach to identity-preserving synthesis, with a particular focus on human images. Our model leverages a direct feed-forward mechanism, circumventing the need for intensive fine-tuning, thereby facilitating quick and efficient image generation. Central to our innovation is a hybrid guidance framework, which combines stylized images, facial images, and textual prompts to guide the image generation process. This unique combination enables our model to produce a variety of applications, such as artistic portraits and identity-blended images. Our experimental results, including both qualitative and quantitative evaluations, demonstrate the superiority of our method over existing baseline models and previous works, particularly in its remarkable efficiency and ability to preserve the subject's identity with high fidelity.
Michelangelo: Conditional 3D Shape Generation based on Shape-Image-Text Aligned Latent Representation
Jul 03, 2023



We present a novel alignment-before-generation approach to tackle the challenging task of generating general 3D shapes based on 2D images or texts. Directly learning a conditional generative model from images or texts to 3D shapes is prone to producing inconsistent results with the conditions because 3D shapes have an additional dimension whose distribution significantly differs from that of 2D images and texts. To bridge the domain gap among the three modalities and facilitate multi-modal-conditioned 3D shape generation, we explore representing 3D shapes in a shape-image-text-aligned space. Our framework comprises two models: a Shape-Image-Text-Aligned Variational Auto-Encoder (SITA-VAE) and a conditional Aligned Shape Latent Diffusion Model (ASLDM). The former model encodes the 3D shapes into the shape latent space aligned to the image and text and reconstructs the fine-grained 3D neural fields corresponding to given shape embeddings via the transformer-based decoder. The latter model learns a probabilistic mapping function from the image or text space to the latent shape space. Our extensive experiments demonstrate that our proposed approach can generate higher-quality and more diverse 3D shapes that better semantically conform to the visual or textural conditional inputs, validating the effectiveness of the shape-image-text-aligned space for cross-modality 3D shape generation.
Learning Variational Motion Prior for Video-based Motion Capture
Oct 28, 2022Motion capture from a monocular video is fundamental and crucial for us humans to naturally experience and interact with each other in Virtual Reality (VR) and Augmented Reality (AR). However, existing methods still struggle with challenging cases involving self-occlusion and complex poses due to the lack of effective motion prior modeling. In this paper, we present a novel variational motion prior (VMP) learning approach for video-based motion capture to resolve the above issue. Instead of directly building the correspondence between the video and motion domain, We propose to learn a generic latent space for capturing the prior distribution of all natural motions, which serve as the basis for subsequent video-based motion capture tasks. To improve the generalization capacity of prior space, we propose a transformer-based variational autoencoder pretrained over marker-based 3D mocap data, with a novel style-mapping block to boost the generation quality. Afterward, a separate video encoder is attached to the pretrained motion generator for end-to-end fine-tuning over task-specific video datasets. Compared to existing motion prior models, our VMP model serves as a motion rectifier that can effectively reduce temporal jittering and failure modes in frame-wise pose estimation, leading to temporally stable and visually realistic motion capture results. Furthermore, our VMP-based framework models motion at sequence level and can directly generate motion clips in the forward pass, achieving real-time motion capture during inference. Extensive experiments over both public datasets and in-the-wild videos have demonstrated the efficacy and generalization capability of our framework.
Coordinates Are NOT Lonely -- Codebook Prior Helps Implicit Neural 3D Representations
Oct 20, 2022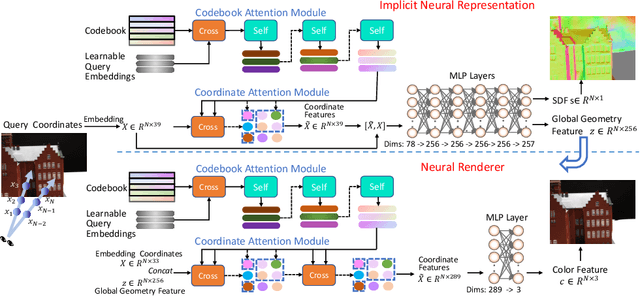


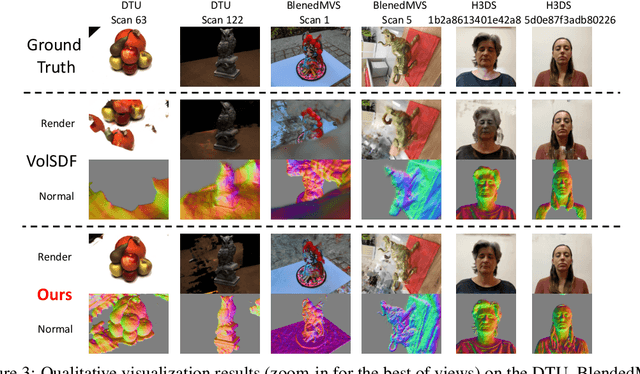
Implicit neural 3D representation has achieved impressive results in surface or scene reconstruction and novel view synthesis, which typically uses the coordinate-based multi-layer perceptrons (MLPs) to learn a continuous scene representation. However, existing approaches, such as Neural Radiance Field (NeRF) and its variants, usually require dense input views (i.e. 50-150) to obtain decent results. To relive the over-dependence on massive calibrated images and enrich the coordinate-based feature representation, we explore injecting the prior information into the coordinate-based network and introduce a novel coordinate-based model, CoCo-INR, for implicit neural 3D representation. The cores of our method are two attention modules: codebook attention and coordinate attention. The former extracts the useful prototypes containing rich geometry and appearance information from the prior codebook, and the latter propagates such prior information into each coordinate and enriches its feature representation for a scene or object surface. With the help of the prior information, our method can render 3D views with more photo-realistic appearance and geometries than the current methods using fewer calibrated images available. Experiments on various scene reconstruction datasets, including DTU and BlendedMVS, and the full 3D head reconstruction dataset, H3DS, demonstrate the robustness under fewer input views and fine detail-preserving capability of our proposed method.