 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Indexing-Decoding Gap in Multimodal Generative Retrieval via Prefix Retention Optimization
Jun 09, 2026Multimodal generative retrieval formulates multimodal retrieval as discrete identifier generation, eliminating the need for explicit similarity search over external embeddings. Existing approaches construct identifiers via residual quantization and decode them with trie-constrained beam search. This combination introduces an indexing-decoding gap: identifier learning objectives, including reconstruction and contrastive losses, do not explicitly enforce prefix discriminability during decoding. As a result, even well-optimized identifiers can be irreversibly pruned early in beam search due to low-rank prefixes. We theoretically characterize this gap and derive a survival bound that relates prefix retention to three controllable factors in indexing and decoding. Building on this bound, we propose PRO, prefix retention optimization, a unified framework comprising three mechanisms: (i) prefix ranking distillation aligns quantized prefix rankings with those induced by pre-quantization embeddings using a listwise loss; (ii) vocabulary scheduling increases codebook sizes from shallow to deep residual quantization levels to reduce early competition from non-target prefixes; and (iii) geometric score fusion vectorizes each candidate prefix and incorporates its similarity to the query into beam search scoring, further reducing the indexing-decoding mismatch. Experiments on nine multimodal retrieval tasks show that PRO improves retention of target identifier prefixes and outperforms existing multimodal generative retrieval baselines.
Seeing Before Agreeing: Aligning Multi-Agent Consensus with Visual Evidence
May 29, 2026Vision-language models (VLMs) have achieved strong performance on visual question answering (VQA). To mitigate individual hallucinations and blind spots, aggregating diverse perspectives via multi-agent collaboration has emerged as a promising paradigm. While this approach has shown great success in textual QA, its potential in the multimodal domain remains under-explored. Existing multi-agent VQA methods predominantly adapt text-centric protocols, focusing on textual discussions while ignoring the alignment of visual information. In this work, we reveal a key insight: answer-level agreement is insufficient for reliable multi-agent VQA; \textit{aligned visual evidence} -- shared support from the image regions agents rely on -- is essential for trustworthy consensus. To leverage this insight, we propose EAGLE (\textbf{E}vidence-\textbf{A}ligned \textbf{G}rounded mu\textbf{L}ti-agent r\textbf{E}asoning), a training-free evidence-centered framework for coordinating multiple VLM agents. EAGLE explicitly exposes each agent's grounding regions as visual evidence, enables mutual verification over the evidence, and uses evidence consistency to guide final decision-making. Experiments on six VQA benchmarks show that EAGLE achieves best average performance across domains while remaining lightweight, interpretable, and practical for deployment.
SCKAN: Structural Consensus-based KAN Prototype Learning for Semi-Supervised Pancreas Segmentation
May 26, 2026Accurate pancreas segmentation is critical for early cancer diagnosis, where annotation scarcity necessitates Semi-Supervised Learning (SSL). However, due to significant inter-sample morphological variability, existing SSL methods face severe generalizability limitations under sparse supervision, leading to the Supervision Bias problem. To address this, we propose Structural Consensus-based KAN Prototype Learning (SCKAN), which constructs the first cross-sample structural consensus learning with Kolmogorov-Arnold Networks (KANs), to achieve more generalizable and accurate segmentation. Specifically, SCKAN contains two key designs: Structure-constrained Prototype Consistency Learning (SPCL), which prompts unbiased structural representation by enforcing cross-sample consistency via prototype-level contrastive optimization, and Consensus-based Kolmogorov-Arnold Fusion (CKaF), which reduces morphology-specific bias by aggregating stable consensus and filtering sample-wise noise via KAN's adaptive B-spline nonlinearity. Extensive experiments on two public pancreas datasets demonstrate the effectiveness of SCKAN. Code is at https://github.com/rhodaliu17/SCKAN.
LongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Ground-truth effects in learning-based fiber orientation distribution estimation in neonatal brains
Sep 02, 2024



Diffusion Magnetic Resonance Imaging (dMRI) is a non-invasive method for depicting brain microstructure in vivo. Fiber orientation distributions (FODs) are mathematical representations extensively used to map white matter fiber configurations. Recently, FOD estimation with deep neural networks has seen growing success, in particular, those of neonates estimated with fewer diffusion measurements. These methods are mostly trained on target FODs reconstructed with multi-shell multi-tissue constrained spherical deconvolution (MSMT-CSD), which might not be the ideal ground truth for developing brains. Here, we investigate this hypothesis by training a state-of-the-art model based on the U-Net architecture on both MSMT-CSD and single-shell three-tissue constrained spherical deconvolution (SS3T-CSD). Our results suggest that SS3T-CSD might be more suited for neonatal brains, given that the ratio between single and multiple fiber-estimated voxels with SS3T-CSD is more realistic compared to MSMT-CSD. Additionally, increasing the number of input gradient directions significantly improves performance with SS3T-CSD over MSMT-CSD. Finally, in an age domain-shift setting, SS3T-CSD maintains robust performance across age groups, indicating its potential for more accurate neonatal brain imaging.
Memory AMP for Generalized MIMO: Coding Principle and Information-Theoretic Optimality
Nov 07, 2023



To support complex communication scenarios in next-generation wireless communications, this paper focuses on a generalized MIMO (GMIMO) with practical assumptions, such as massive antennas, practical channel coding, arbitrary input distributions, and general right-unitarily-invariant channel matrices (covering Rayleigh fading, certain ill-conditioned and correlated channel matrices). The orthogonal/vector approximate message passing (OAMP/VAMP) receiver has been proved to be information-theoretically optimal in GMIMO, but it is limited to high-complexity LMMSE. To solve this problem, a low-complexity memory approximate message passing (MAMP) receiver has recently been shown to be Bayes optimal but limited to uncoded systems. Therefore, how to design a low-complexity and information-theoretically optimal receiver for GMIMO is still an open issue. To address this issue, this paper proposes an information-theoretically optimal MAMP receiver and investigates its achievable rate analysis and optimal coding principle. Specifically, due to the long-memory linear detection, state evolution (SE) for MAMP is intricately multidimensional and cannot be used directly to analyze its achievable rate. To avoid this difficulty, a simplified single-input single-output variational SE (VSE) for MAMP is developed by leveraging the SE fixed-point consistent property of MAMP and OAMP/VAMP. The achievable rate of MAMP is calculated using the VSE, and the optimal coding principle is established to maximize the achievable rate. On this basis, the information-theoretic optimality of MAMP is proved rigorously. Numerical results show that the finite-length performances of MAMP with practical optimized LDPC codes are 0.5-2.7 dB away from the associated constrained capacities. It is worth noting that MAMP can achieve the same performances as OAMP/VAMP with 0.4% of the time consumption for large-scale systems.
Revisiting Cephalometric Landmark Detection from the view of Human Pose Estimation with Lightweight Super-Resolution Head
Sep 29, 2023



Accurate localization of cephalometric landmarks holds great importance in the fields of orthodontics and orthognathics due to its potential for automating key point labeling. In the context of landmark detection, particularly in cephalometrics, it has been observed that existing methods often lack standardized pipelines and well-designed bias reduction processes, which significantly impact their performance. In this paper, we revisit a related task, human pose estimation (HPE), which shares numerous similarities with cephalometric landmark detection (CLD), and emphasize the potential for transferring techniques from the former field to benefit the latter. Motivated by this insight, we have developed a robust and adaptable benchmark based on the well-established HPE codebase known as MMPose. This benchmark can serve as a dependable baseline for achieving exceptional CLD performance. Furthermore, we introduce an upscaling design within the framework to further enhance performance. This enhancement involves the incorporation of a lightweight and efficient super-resolution module, which generates heatmap predictions on high-resolution features and leads to further performance refinement, benefiting from its ability to reduce quantization bias. In the MICCAI CLDetection2023 challenge, our method achieves 1st place ranking on three metrics and 3rd place on the remaining one. The code for our method is available at https://github.com/5k5000/CLdetection2023.
Protecting the Intellectual Property of Diffusion Models by the Watermark Diffusion Process
Jun 06, 2023



Diffusion models have emerged as state-of-the-art deep generative architectures with the increasing demands for generation tasks. Training large diffusion models for good performance requires high resource costs, making them valuable intellectual properties to protect. While most of the existing ownership solutions, including watermarking, mainly focus on discriminative models. This paper proposes WDM, a novel watermarking method for diffusion models, including watermark embedding, extraction, and verification. WDM embeds the watermark data through training or fine-tuning the diffusion model to learn a Watermark Diffusion Process (WDP), different from the standard diffusion process for the task data. The embedded watermark can be extracted by sampling using the shared reverse noise from the learned WDP without degrading performance on the original task. We also provide theoretical foundations and analysis of the proposed method by connecting the WDP to the diffusion process with a modified Gaussian kernel. Extensive experiments are conducted to demonstrate its effectiveness and robustness against various attacks.
CILIATE: Towards Fairer Class-based Incremental Learning by Dataset and Training Refinement
Apr 09, 2023



Due to the model aging problem, Deep Neural Networks (DNNs) need updates to adjust them to new data distributions. The common practice leverages incremental learning (IL), e.g., Class-based Incremental Learning (CIL) that updates output labels, to update the model with new data and a limited number of old data. This avoids heavyweight training (from scratch) using conventional methods and saves storage space by reducing the number of old data to store. But it also leads to poor performance in fairness. In this paper, we show that CIL suffers both dataset and algorithm bias problems, and existing solutions can only partially solve the problem. We propose a novel framework, CILIATE, that fixes both dataset and algorithm bias in CIL. It features a novel differential analysis guided dataset and training refinement process that identifies unique and important samples overlooked by existing CIL and enforces the model to learn from them. Through this process, CILIATE improves the fairness of CIL by 17.03%, 22.46%, and 31.79% compared to state-of-the-art methods, iCaRL, BiC, and WA, respectively, based on our evaluation on three popular datasets and widely used ResNet models.
Amplifying Membership Exposure via Data Poisoning
Nov 01, 2022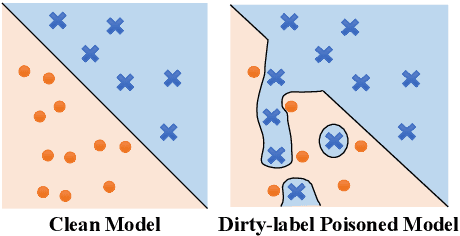
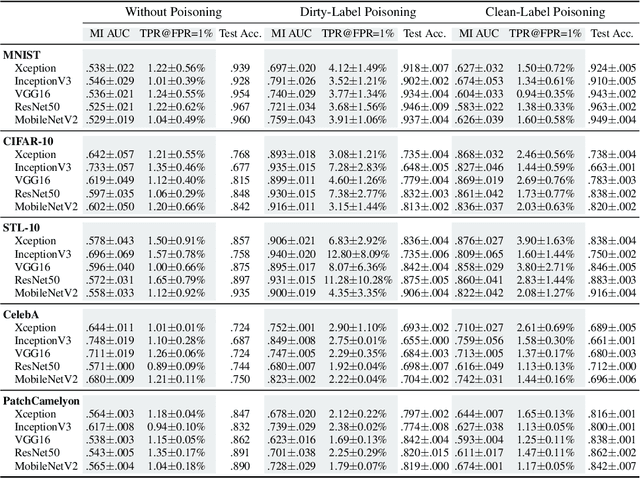
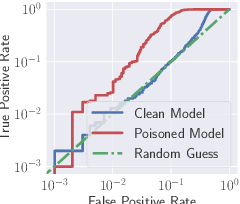
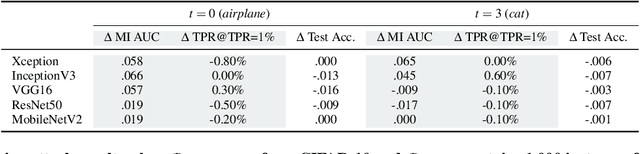
As in-the-wild data are increasingly involved in the training stage, machine learning applications become more susceptible to data poisoning attacks. Such attacks typically lead to test-time accuracy degradation or controlled misprediction. In this paper, we investigate the third type of exploitation of data poisoning - increasing the risks of privacy leakage of benign training samples. To this end, we demonstrate a set of data poisoning attacks to amplify the membership exposure of the targeted class. We first propose a generic dirty-label attack for supervised classification algorithms. We then propose an optimization-based clean-label attack in the transfer learning scenario, whereby the poisoning samples are correctly labeled and look "natural" to evade human moderation. We extensively evaluate our attacks on computer vision benchmarks. Our results show that the proposed attacks can substantially increase the membership inference precision with minimum overall test-time model performance degradation. To mitigate the potential negative impacts of our attacks, we also investigate feasible countermeasures.